决策树
决策树基本概念
- 通过一系列节点判断,得到最终的结果。
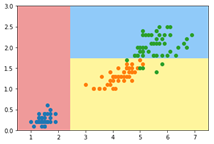
- 例如鸢尾花数据集,仅取两个特征:
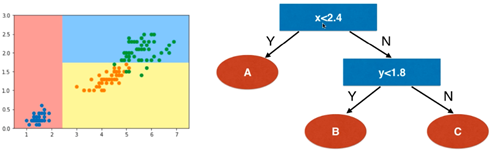
- 决策树为非参数学习算法,天然的可解决多分类问题,不需使用OvR、OvO等策略。
- 同样也可以解决回归问题。
- 构建一个决策树,主要考虑2个问题:
- 每个节点要在哪一个特征(维度)上进行划分?
- 特征(维度)以阀值多少作为划分?
- 主要流程:
利用训练样本特征及真值,通过衡量算法求出每一个节点最佳特征及划分阀值,从而构建一颗决策树。
衡量算法
-
熵在热力学中的定义,物体熵越大粒子运动越剧烈,熵越小粒子运动越平静。
-
熵在信息论中代表随机变量的不确定度。
-
熵越大,数据的不确定性越高。熵越小,数据的不确定性越低。
-
信息熵公式:
[数据集共有 类, 表示数据集中 类别所占的比例,log()以e为底。] -
Eg: 假设一个数据集有3类,每类样本量占比均为 。另一个数据集同样3类,每类样本量占比为{ }。信息熵为:
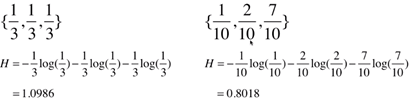
依概率右边数据的确定度更高,熵计算的结果右边也确实更低。再比如3类占比{1,0,0},信息熵就等于0,因此确定度就很高,因为只有一个种类。 -
我们构建决策树,就是要找到每一个节点最合适的划分特征,使数据集在节点划分后得到的分支,信息熵总和最小的为最适合的划分特征。
-
信息增益公式:
[ 为总样本集。 为某离散特征 可能取值,将 分成了 群。 为 中第 个值的样本集。]
总熵减去各个分支熵的权重和,称信息增益。 -
信息增益最大的为最适合的划分特征。
-
Eg:
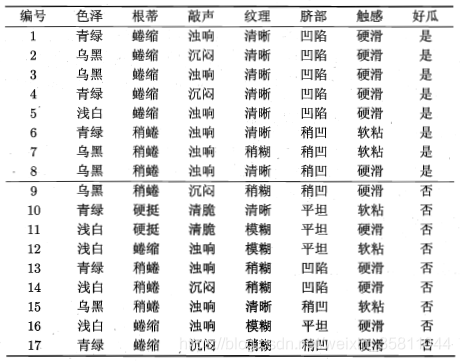
以西瓜数据为例共17个样本,有两类:8个正例,9个反例。特征集为:{色泽、根蒂、敲声、纹理、脐部、触感}.。以特征 ‘色泽’ 为例:有3个可能值 {青绿、乌黑、浅白},(色泽=青绿)有6个,其中正反例占比:p1=3/6,p2=3/6、(色泽=乌黑)有6个,其中正反例占比:p1=4/6,p2=2/6、(色泽=浅白)有5个,其中正反例占比:p1=1/5,p2=4/5。- 整个数据集总熵
:
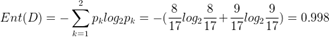
- 分支熵
:
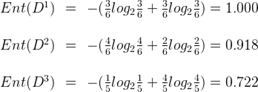
- 特征’色泽’ 信息增益
:
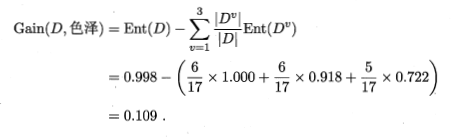
- 用同样的方式,计算出除 ‘色泽’ 剩下的5个特征的信息增益值,这里我直接给出结果:

- 经过对比,特征 ‘纹理’ 的信息增益最大,因此将纹理作为划分节点:
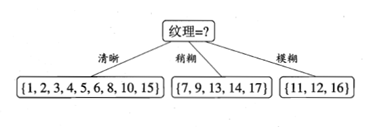
- 第一个节点决定后,在此基础上,同样使用信息增益继续对每个分支节点做进一步划分,最终可以得出一个完整的决策树模型,如图:
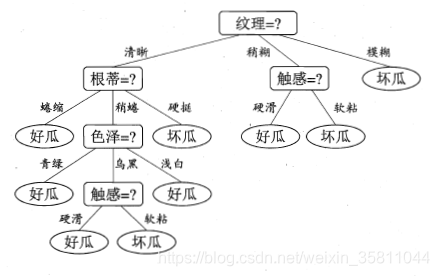
- 整个数据集总熵
:
-
信息增益准则对特征可取数目较多的特征有偏好,为了减少这种影响,增益率(Gain Ratio)诞生。
-
增益率公式:
,其中 称为特征 的 ‘固有值’ ,特征 的可能取值数目越多 就越大。 -
增益率是对特征可取数目较少的特征有偏好,因此常不直接使用增益率,而是采用先找出信息增益高于平均水平的特征,再从中选择增益率最高的,为最适合的划分特征。
- 和信息熵的作用一致,只是计算公式不同。
- 基尼公式:
[ 表示数据集中i类别所占的比例] - G越大,数据的不确定性越高。G越小,数据的不确定性越低。
选取’划分特征’方式
- 离散特征: 可能取值数是有限的,就如同上面西瓜数据例子。处理方式即通过对不同特征的不同可能值进行分群,计算信息增益或增益率,比较所有特征的信息增益或增益率值,从而为每一个节点选出最佳划分特征。 (Tips:离散特征,子节点是不能再考虑父节点使用过的所有特征。)
- 连续特征: 可能取值数不再有限,处理方式通常采用二分法。1. 样本每一个特征单独考虑,按从小到大顺序排列,从头开始按先后顺序两两相邻样本,对当前考虑的特征取均值作为阀值,根据此阀值对样本集进行二分,计算信息增益或增益率,比较所有特征的信息增益或增益率值,选出最佳划分特征。(Tips:连续特征,子节点依旧还可以使用父节点特征,即每个节点每次选择划分特征都可以考虑全部连续特征,不论父节点是否已经使用过此特征。)
Eg:
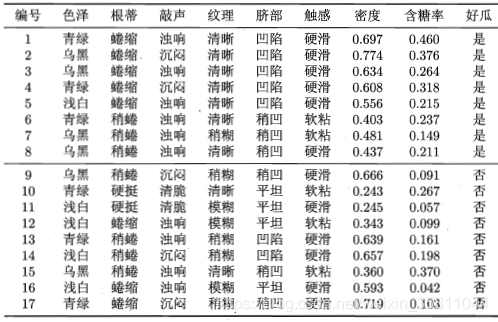
同样以西瓜数据为例,现在多了两个连续特征:'密度,‘含糖率’。
对于特征 ‘密度’ : 先从小到大排序,然后两两取均值得到16个阀值,根据每一个阀值,对样本集进行划分,然后算出信息增益,选取信息增益最大的阀值作为划分点。这里最大信息增益为0.262,对应于阀值0.381。

对于特征 ‘含糖率’ : 同样步骤,得出最大信息增益为0.349,对应于阀值0.126。

- ID3、C4.5、C5 等决策树算法通,特征离散就采用分群法,连续就采用二分法,采用计算信息增益或增益率的方式。CART决策树算法,不管特征离散还是连续都采用二分法,采用计算gini系数或信息熵的方式。(sklearn只实现CART决策树算法)
Scikit-learn中决策树
主要参数:
| 参数名 | 含义 |
|---|---|
| criterion | 衡量算法: ‘gini’(默认), ‘entropy’ |
| splitter | 每个节点处选择拆分的策略:‘best’(默认),‘random’ |
| min_samples_split | 子节点拆分所需的最小样本数:如果是int,直接表示最小样本数,如果是float,表示概率,最小样本数为min_samples_split * n_samples。默认 = 2。 |
| min_samples_leaf | 子节点至少要有的样本数:如果是int,直接表示需要样本数,如果是float,表示概率,需要样本数为min_samples_split * n_samples。默认 = 1。 |
| max_depth | 树的最大深度。默认 = None,扩展节点直到所有子节点都是纯的或直到所有子节点包含少于min_samples_split样本。 |
| max_leaf_nodes | 最多能有多少子节点,默认=None,可以有无限个。 |
| max_features | 每次拆分考虑的特征数量:int,float,‘auto’,‘sqrt’,‘log2’,‘None’(默认)。None即考虑全部特征。 |
| class_weight | 各类别的权重:字典({0:0.9,1:0.1}),‘balanced’,默认None。如果class_weight选择balanced,会根据训练样本量来计算权重,某类样本量越多,权重越低,反之亦然。 |
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
from matplotlib.colors import ListedColormap
from sklearn.tree import DecisionTreeClassifier
#画决策边界函数
def plot_decision_boundary(model, axis):
x0, x1 = np.meshgrid(
np.linspace(axis[0], axis[1], int((axis[1]-axis[0])*100)).reshape(-1, 1),
np.linspace(axis[2], axis[3], int((axis[3]-axis[2])*100)).reshape(-1, 1),)
X_new = np.c_[x0.ravel(), x1.ravel()]
y_predict = model.predict(X_new)
zz = y_predict.reshape(x0.shape)
custom_cmap = ListedColormap(['#EF9A9A','#FFF59D','#90CAF9'])
plt.contourf(x0, x1, zz, linewidth=5, cmap=custom_cmap)
#为了可视化,只取两个维度
iris = datasets.load_iris()
X = iris.data[:,2:]
y = iris.target
dt_clf = DecisionTreeClassifier(max_depth=2, criterion="entropy", random_state=42)
dt_clf.fit(X, y)
plot_decision_boundary(dt_clf, axis=[0.5, 7.5, 0, 3])
plt.scatter(X[y==0,0], X[y==0,1])
plt.scatter(X[y==1,0], X[y==1,1])
plt.scatter(X[y==2,0], X[y==2,1])
plt.show()