本文为《机器学习实战:基于Scikit-Learn和TensorFlow》的读书笔记。
中文翻译参考
决策树可以分类,也可以回归,还有多输出任务
是随机森林的基础组成部分
1. 训练与可视化
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier
iris = load_iris()
X = iris.data[:, 2:] # petal length and width
y = iris.target
tree_clf = DecisionTreeClassifier(max_depth=2)
tree_clf.fit(X, y)
from sklearn.tree import export_graphviz
export_graphviz(
tree_clf,
out_file="iris_tree.dot",
feature_names=iris.feature_names[2:],
class_names=iris.target_names,
rounded=True,
filled=True
)
安装好Graphviz,在cmd下输入 dot -Tpng iris_tree.dot -o iris_tree.png # cmd,生成决策树可视化图片
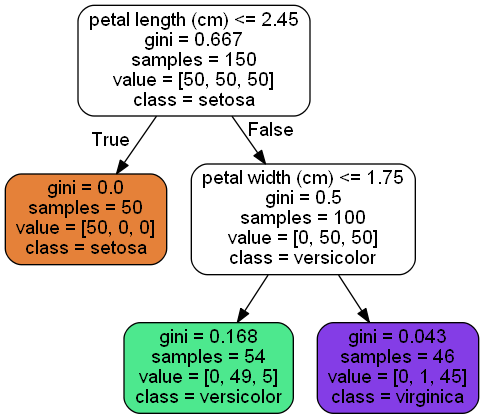
2. 分类预测
决策树特性:不需要太多的数据预处理,尤其是不需特征缩放或归一化
tree_clf.predict_proba([[5,1.5]])
# array([[0. , 0.90740741, 0.09259259]])
tree_clf.predict([[5,1.5]])
# array([1])
- 预测时间复杂度: ,与特征数量无关,m为样本数
- 训练时间复杂度:
,n 为特征数量
max_features
通常,算法使用 Gini 不纯度来进行检测,也可以设置为entropy
- 基尼指数计算稍微快一点,SKlearn默认值
- 基尼指数会趋于在树的分支中将最多的类隔离出来
- 熵指数趋向于产生略微平衡一些的决策树模型
3. 模型参数
决策树不需要事先设置参数,不添加约束的决策树模型,能很好的拟合数据,容易过拟合
min_samples_split(节点在被分裂之前必须具有的最小样本数)min_samples_leaf(叶节点必须具有的最小样本数)min_weight_fraction_leaf(和min_samples_leaf相同,但表示为加权总数的一小部分实例)max_leaf_nodes(叶节点的最大数量)max_features(在每个节点被评估是否分裂的时候,具有的最大特征数量)- 增加
min_* hyperparameters或者减少max_* hyperparameters会使模型正则化。
使用假设检验进行剪枝
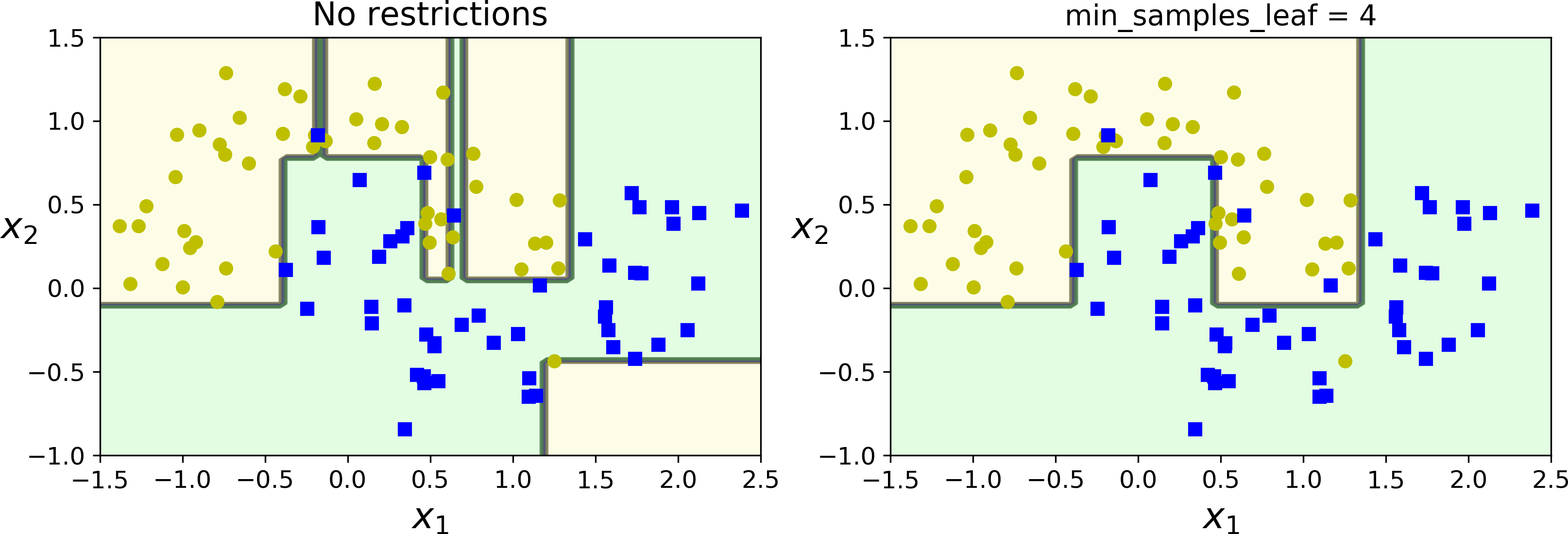
上图左侧没有剪枝,模型过拟合了
4. 回归
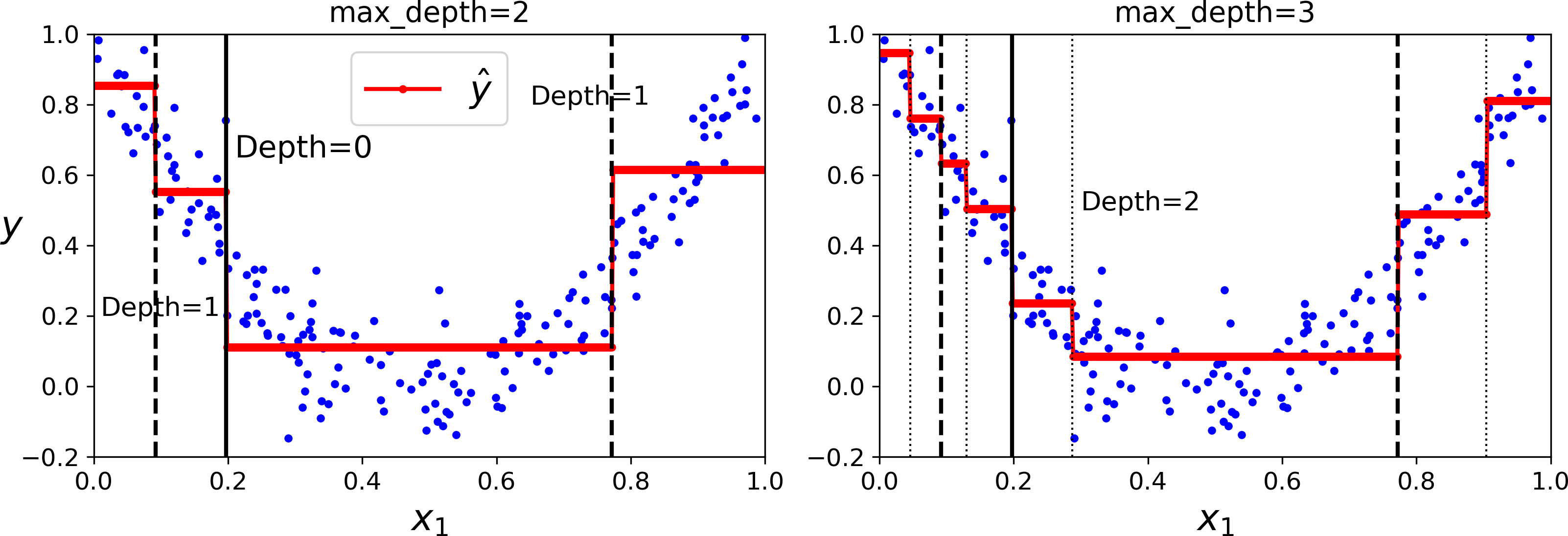
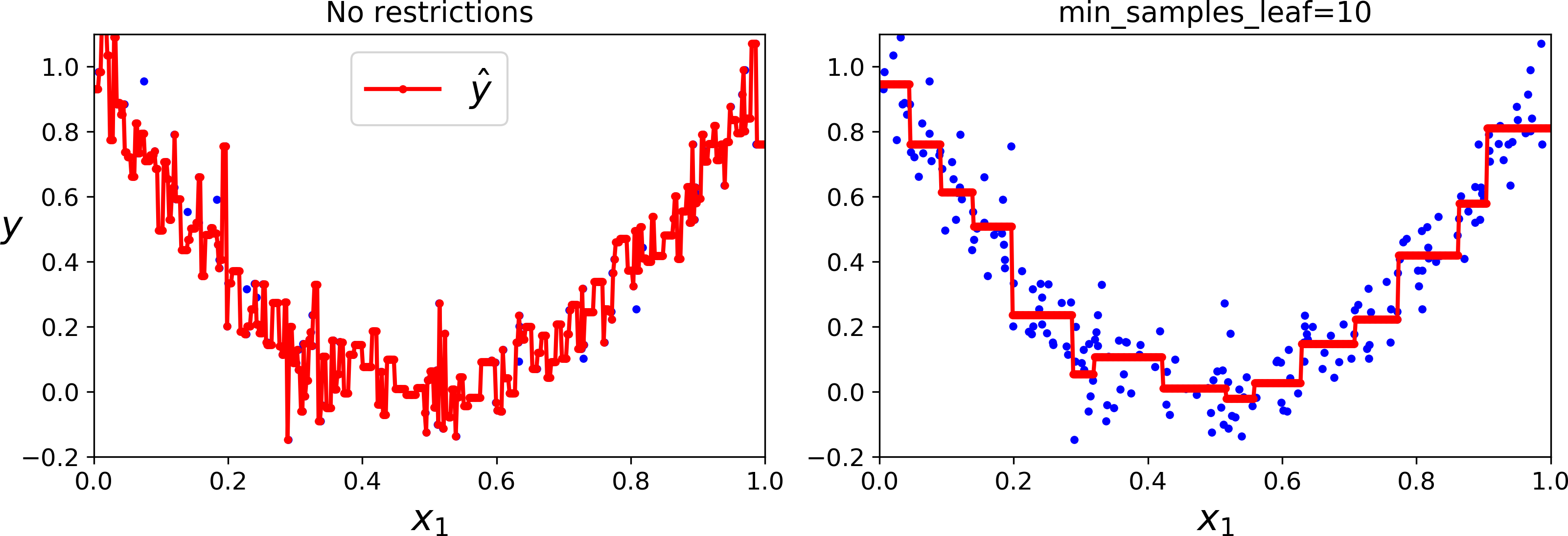
同样需要设置合理的参数,左侧过拟合了
5. 不稳定性
- 决策树 对旋转很敏感,可以使用 PCA 主成分分析,缓解
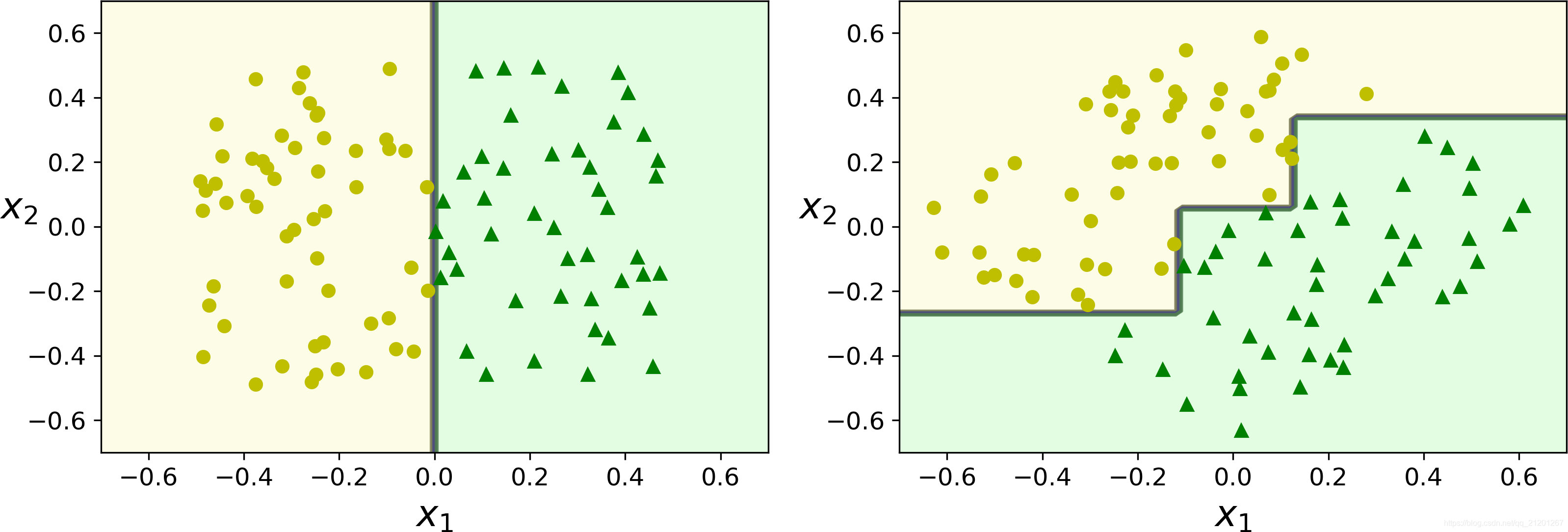
- 决策树 对训练数据的微小变化非常敏感,随机森林可以通过多棵树的平均预测值限制这种不稳定性