源码:
文档:
写一个入口代码进行调试
from sklearn.datasets import load_iris
from sklearn.metrics import accuracy_score
from sklearn.model_selection import train_test_split
from numpy_ml.trees import DecisionTree
X, y = load_iris(True)
dt = DecisionTree()
X_train, X_test, y_train, y_test = train_test_split(X, y)
dt.fit(X_train, y_train)
y_pred = dt.predict(X_test)
score = accuracy_score(y_test, y_pred)
print(score)
看到建树的关键代码
numpy_ml.trees.dt.DecisionTree#_grow
递归退出条件1:
# if all labels are the same, return a leaf
if len(set(Y)) == 1:
if self.classifier:
prob = np.zeros(self.n_classes)
prob[Y[0]] = 1.0
return Leaf(prob) if self.classifier else Leaf(Y[0])
如果是分类,叶子结点是独热码表示的类别。
递归退出条件2:
扫描二维码关注公众号,回复:
12518089 查看本文章

# if we have reached max_depth, return a leaf
if cur_depth >= self.max_depth:
v = np.mean(Y, axis=0)
if self.classifier:
v = np.bincount(Y, minlength=self.n_classes) / len(Y)
return Leaf(v)

看到结点分裂
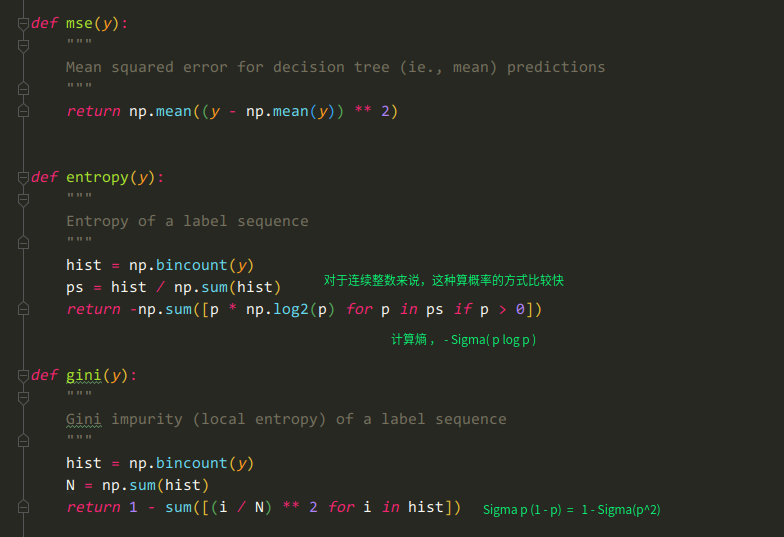

算信息增益
n = len(Y)
n_l, n_r = len(left), len(right)
e_l, e_r = loss(Y[left]), loss(Y[right])
child_loss = (n_l / n) * e_l + (n_r / n) * e_r
# impurity gain is difference in loss before vs. after split
ig = parent_loss - child_loss
因为是二叉树,所以信息增益比没有意义(固定分裂两个子节点,不存在分裂多个子节点导致信息增益提高的情况)
得到分割点后,直接array传参造孩子结点了,没有花里胡哨的操作
# greedily select the best split according to `criterion`
feat, thresh = self._segment(X, Y, feat_idxs)
l = np.argwhere(X[:, feat] <= thresh).flatten()
r = np.argwhere(X[:, feat] > thresh).flatten()
# grow the children that result from the split
left = self._grow(X[l, :], Y[l], cur_depth)
right = self._grow(X[r, :], Y[r], cur_depth)
return Node(left, right, (feat, thresh))
很遗憾,没有看到CART剪枝的代码