版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
项目案例
数据集介绍
数据集链接:https://pan.baidu.com/s/1qg7Z2ZJUi5pk9RIZN32srg
提取码:bhdz
复制这段内容后打开百度网盘手机App,操作更方便哦
这是一份好莱坞电影数据,有28个特征,五千多个样本,特征有电影时长、导演、票房、语言、评分等,样本中有缺失值,需要进行处理。
项目任务
- 查看票房收入统计
- 导演vs票房总收入
- 主演vs票房总收入
- 导演+主演vs票房收入
- 查看imdb评分统计
- 查看各imdb评分的电影个数
- 查看平均imdb评分最高的前20导演
- 电影产量年份趋势
- 电影类型分析
- 按题材分类,统计个数
- 按题材统计票房
涉及知识点
- pandas缺失值处理
- pandas分组、排序、统计
- pandas绘图
- pandas读取与输出
- DataFrame扩充
任务实现过程
-
读取并处理缺失值
import pandas as pd import matplotlib.pyplot as plt # 1.1、加载数据 data = pd.read_csv('movie_data.csv') print('数据的形状:', data.shape) # 1.2、处理缺失值 data = data.dropna(how='any') data.head()
数据的形状: (5043, 28)
…
-
任务1、查看票房收入统计
# 1.1 导演vs票房总收入 group_director = data.groupby(by='director_name')['gross'].sum() group_director.sort_values(ascending=False)# 1.2 主演vs票房总收入 group_actor = data.groupby(by=['actor_1_name'])['gross'].sum() group_actor.sort_values(ascending=False)# 1.3 导演+主演vs票房收入 group_actor = data.groupby(by=['director_name','actor_1_name'])['gross'].sum() group_actor.sort_values(ascending=False) -
任务2、查看imdb评分统计
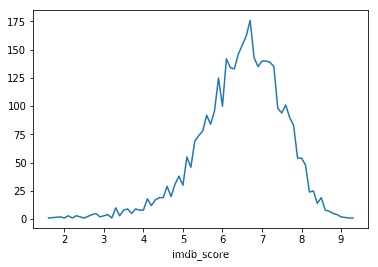
# 2.1 查看各imdb评分的电影个数 imdb = data.groupby('imdb_score')['movie_title'].count() plt.figure() imdb.plot() plt.savefig('./output/imdb_scores.png') plt.show()
# 2.2 查看imdb平均分最高的前20导演
director_mean = data.groupby('director_name')['imdb_score'].mean()
# 使用sort排序,ascending=False代表降序
top20_imdb_directors = director_mean.sort_values(ascending=False)[:20]
plt.figure(figsize=(18.0, 10.0))
# kind='barh' 水平条形图
top20_imdb_directors.plot(kind='barh')
plt.savefig('./output/top20_imdb_directors.png')
plt.show()

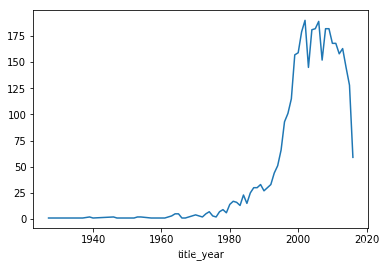
4. 任务3、电影产量年份趋势
# 根据年份分组,统计每年上映电影个数
movie_years = data.groupby('title_year')['movie_title'].count()
plt.figure()
movie_years.plot()
plt.savefig('./output/movie_years.png')
plt.show()
5. 任务4、电影类型分析
从数据中看出,每个电影可以对应好几种题材,需要先将数据处理为一个电影对应一个类型,否则直接按照genres分组,得出的是同时对应这几个类型的数据
例如:movie1对应 Action|Adventure|Fantasy|Sci-Fi 这四个类型,需要将它处理为四条数据,分别对应一个类型,如movie1—>Action, movie1—>Adventure, movie1—>Fantasy, movie1—> Sci-Fi
# 构建一个新的dataframe,只需要类别和票房这两个特征
genre_data = pd.DataFrame(columns = ['genre','gross'])
# data.iterrows:使用迭代器的方式读取数据,返回数字索引(int)和每一行的数据(series)
for i, row_data in data.iterrows():
# 使用split将genres分割
genres = row_data['genres'].split('|')
n_genres = len(genres)
# 构建一个空字典,用以保存genre和gross的值
dict_obj = {}
dict_obj['gross'] = [row_data['gross']] * n_genres
dict_obj['genre'] = genres
# 将字典转为dataframe类型
genre_df = pd.DataFrame(dict_obj)
# DataFrame的append将genre_df的数据添加进genre_data
genre_data = genre_data.append(genre_df)
# 将最终的数据写入csv保存
genre_data.to_csv('./output/genre_data.csv',index=None)
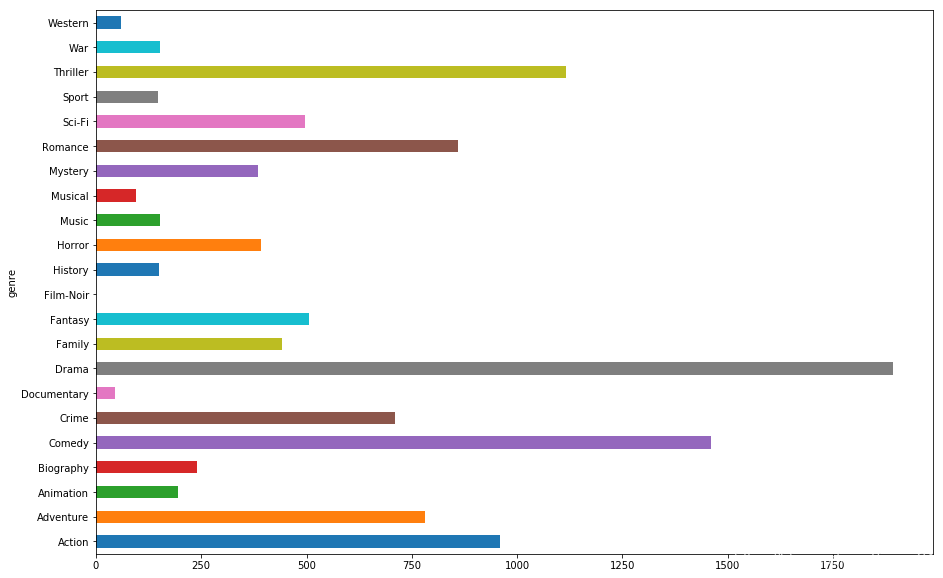
# 4.1 按题材分类,统计个数
genre_count = genre_data.groupby('genre').size()
plt.figure(figsize=(15.0, 10.0))
genre_count.plot(kind='barh')
plt.savefig('./output/genre_count.png')
plt.show()
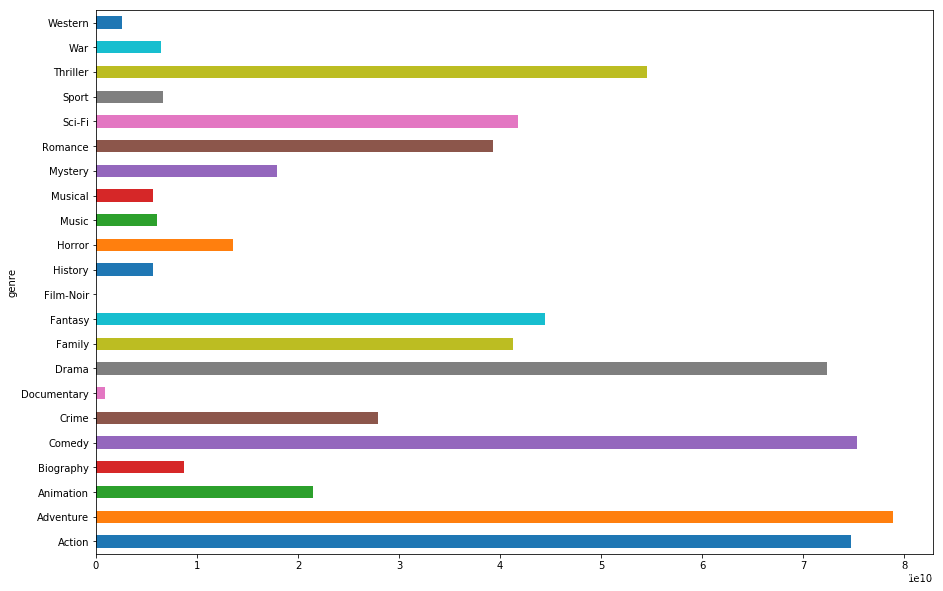
# 4.2 按题材统计票房
genre_gross = genre_data.groupby('genre')['gross'].sum()
plt.figure(figsize=(15.0, 10.0))
genre_gross.plot(kind='barh')
plt.savefig('./output/genre_gross.png')
plt.show()