版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
平时我们使用爬虫是都是直接用urllib库,就可以直接访问网页,爬取数据,但是有些网站会设置一些反爬机制,识别是浏览器还是爬虫,所以对于这些网站我们需要将网站伪装成浏览器进行访问
1、首先我们看一下浏览器访问的标识,打开一个浏览器,进入开发者模式,然后点击下面的network,再看下面的name下面很多个连接,随便点进去一个,在其右边,拉到最底下,可以看到user-agent:这就是这个浏览器的标识,不同浏览器的标识不同。
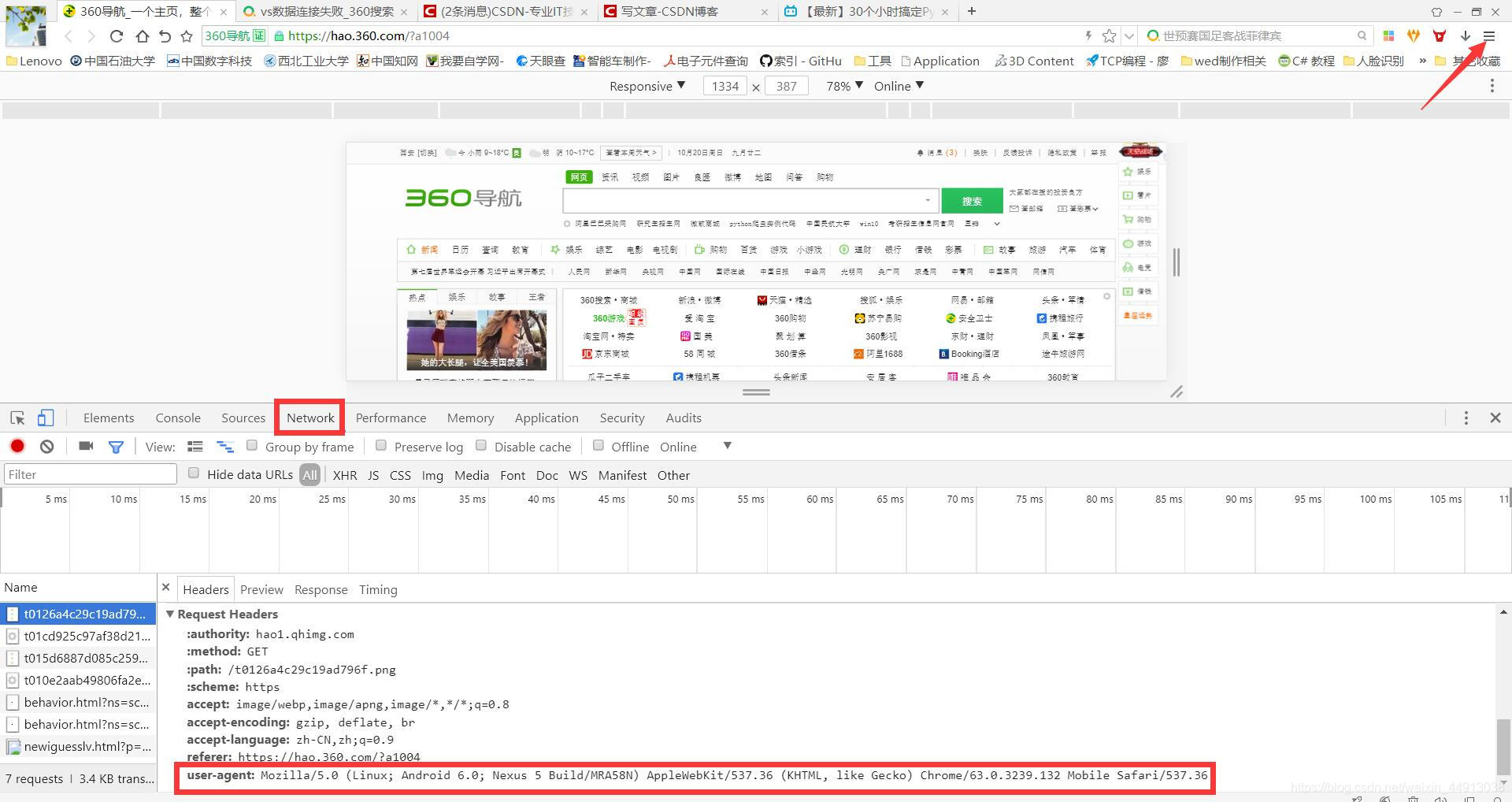
2、好了,接下来需要些伪装浏览器的代码,将上面的user agent这行全部复制下来,做成一个元组赋给headers,然后新建一个opener,将headers赋给opener,之后就可以使用opener打开网页,访问网页,爬取数据
import urllib.request
url = "https://blog.csdn.net"
#######伪装浏览器代码部分#######
headers = ("User-Agent","Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Mobile Safari/537.36")
opener = urllib.request.build_opener()
opener.addheaders = [headers]
#######伪装浏览器代码部分#######
data = opener.open(url).read().decode('utf-16-le','ignore')