一、爬虫异常处理
爬虫在运行的过程中,经常会遇到异常。若不进行异常处理,则爬虫程序会直接崩溃停止运行,当下次再次运行时,则又会重头开始。因此,开发一个具有顽强生命力的爬虫,必须要进行异常处理。
常见的爬虫异常状态码:
301 Moved Permanently:重定向到新的URL,永久性。
302 Found:重定向到临时的URL,非永久性。
304 Not Modified:请求的资源未更新。
400 Bad Request:非法请求。
401 Unauthorized:请求未经授权。
403 Forbidden:禁止访问。
404 Not Found:没有找到对应页面。
500 Internal Server Error:服务器内部出现错误。
501 Not Implemented:服务器不支持实现请求所需要的功能。
常见的爬虫异常类型:主要为URLError与HTTPError类
触发URLError的原因:
1、连不上服务器
2、远程URL不存在
3、本地没有网络
4、触发HTTPError子类
二者的区别:
HTTPError为URLError的子类,HTTPError有异常状态码与异常原因即code与reason属性,URLError没有异常状态码,所以,在处理的时候,不能使用URLError直接代替HTTPError。如果要代替,必须要判断是否有状态码属性,以下为正确使用URLError的实例代码:
import urllib.error
import urllib.request
try:
urllib.request.urlopen("输入的网址")
except urllib.error.URLError as e:
if hasattr(e,"code"):
print(e.code)
if hasattr(e,"reason"):
print(e.reason)
二、解决反爬机制的利器--浏览器伪装
首先打开一个网页,按F12进入开发者选项,找到Network选项卡,然后刷新页面,找到一个js文件并点击,找到Headers,可以最终看到如下界面:
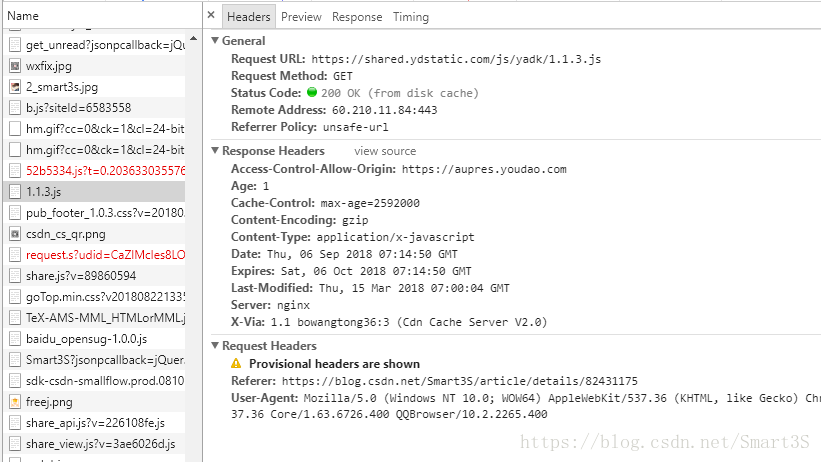
页面中的User-Agent很重要,即用户的浏览器码,模拟浏览器的代码如下:
import urllib.request
#以博客网页为例
url="http://blog.csdn.net/Smart3S/article/details/82431464"
#从网页开发者选项中找到的浏览器码
headers=("User-Agent","Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.26 Safari/537.36 Core/1.63.6726.400 QQBrowser/10.2.2265.400")
opener=urllib.request.build_opener()
opener.addheaders=[headers]
data=opener.open(url).read()
fh=open("F:/233.html","wb")
fh.write(data)
fh.close()由于urlopen()对于一些HTTP的高级功能不支持,所以,如果要修改报头,可以使用urllib.request.build_opener()进行,当然,也可以使用urllib.request.Request()下的add_header()实现浏览器的模拟。