前言:
Python越来越流行,跟着时代的进程,我也不用全身心的投入训练,我也来玩玩Python,想着以后工作应该不会有windows的所以我就去安装了Ubuntu 和win10的双系统,这个现在网上到处都是教程我就不细说了,按着教程来就是,百度是个万能的东西,至于pycharm也一样的。
我的配置:Ubuntu16.04+pycharm2018.3(Professional)。
预备知识:
爬虫我的理解:
爬虫(spider)故名思议就是像一个蜘蛛一样在网页上爬来爬去获取我们想要的东西。
爬虫的原理:
这个需要一点的计算机网络的知识啦,当我们浏览网页的时候,我们想访问那个网站就可以在浏览器输入网址就好,用专业术语来解释一下,就是我们的浏览器也就是客服端像网站的服务器发送一个请求,这个过程就叫请求,当服务器收到我们发送的请求的后就把我们访问的数据给们发送过来,这个称之为响应,当然发送的是自己HTML的代码,当我们的浏览器接收到这些响应后就编译HTML代码给我们看,我们要得是这些数据,所以我们用了python的requests的库函数去模拟浏览器就可以收到服务器的数据。
数据的提取:
python最强到的地方就是它有各种各样的库你能想到的库它都有,没有的是你不知道,对于服务器返回的数据有很多是我们不需要的,所以需要我们把有用的数据提取出来,这个用到了正则表达式,Python的re库正则表达式我觉得十分复杂,不过我相信等我们用过很多次后一定会认为这个正则表达式也不过如此,对于不同的网页网页结构不同,我们提取内容的正则表达式也不一样,感兴趣的自己去详细学习一下,在这里为了直接用我们就举个例子:
content=re.findall('<title>(.*?)</title>',html)
这个式子中,htm l表示我们发送请求的后服务器返回给我们的数据(一个很长很大的列表),content表示我们提取后得到的内容,而re.findall()这个函数表示的正是用正则表达式re库中的findall函数去提取内容,最重要的就是这个''<title>(.*?)</title>',其中,<title>为html中的内用,而 (.*?) 则是我们需要提取的内容,其中“.*?”表示任意内容,这个括号表示提取出来,这两个<title>用于定位,整体的的意思就是在html中提取所有两个'<title>'中间的任意内容。
求情访问以及伪装:
Python就是这么方便你想爬虫,只需要需要直接调用库函数就好,我用的是requests库:response=requests.get(url) 其中response就是其响应,包括了所有内容,有的时候需要response.encoding='utf-8' 来确定其编码,然后html=response.text,然后输出html就是在网页上按F12下面出现内容一样的东西啦。我以爬取noel_url='http://www.tianyashuku.com/wuxia/7/'为例,初步代码为:
novl_url='http://www.tianyashuku.com/wuxia/7/'#小说的url
response=requests.get(novl_url)#模拟浏览器进行访问
response.encoding='utf-8'#确定编码规则
html=response.text
print(html)

这是爬取后的《倚天屠龙记》小说的主页面Python输出的结果以及在浏览器上按F12,看到的网页编辑框。
现在随着爬虫越来越火热越来越多的人会爬虫,然后如果一个网站有爬虫程序大量的访问的话一定会使网络瘫痪,使那些正常用户又不好的正常体验,所以一般都有一定的反爬机制,一般有三种方法第一种是对你的访问进行识别如果你不是浏览器的话直接拒绝访问了,可以让你的爬虫伪装成一个浏览器就好,第二种则是发现你有异常的访问直接封你的ip23333,也有技术手段可以让你边访问边修改你的ip地址,第三种是设计动态网页,也可以用技术手段解决。参考见:最全反爬虫技术介绍。对于本蒟蒻,以及我们本次访问的网站我们就只使用伪装成浏览器的方法来成功的爬取。
在requests去访问网站时会如实的告诉服务器自己是什么,所以这时需要我们把爬虫伪装一下,一般只需要这样(来源):
socket.setdefaulttimeout(10)#socket访问时延
send_headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36",
"Connection": "keep-alive",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8",
"Accept-Language": "zh-CN,zh;q=0.8"
}#伪装成浏览器
response=requests.get(novl_url,send_headers)#访问
response.close()#访问后就关闭访问在我没发现服务器拒绝我访问的时候我还不知道是什么问题,各种百度,先让我设置套接字的延时以及访问后就关闭访问,最后才知道要伪装成浏览器233333,最后本网站不受阻的访问一个网站就是这样完成了。
提取小说的标题以及章节信息:
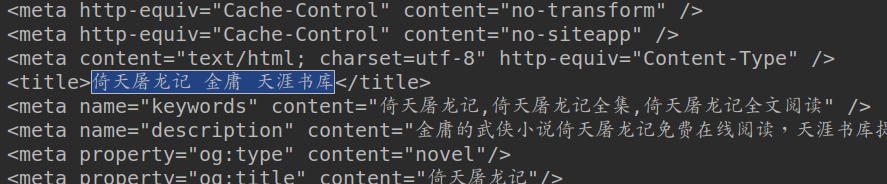
看到这个标题没有这就是我们需要的东西,如果网页规范的话其他小说也是这样的格式(<title>标题</title>)可以自需要更改小说的主页的url就好,不过这个网站不规范,每部小小说都不一样2333,爬其他的都需要换正则表达式....
我们再把这个从 html 中标题提取出来
title=re.findall('<title>(.*?)</title>',html)[0]#返回的是一个列表提 [0]取出来
print(title)
可以了,可是我们爬取的是整本小说又不是只有这个标题,看这个小说的主界面不但有每个章节的链接以及标题:


这就是我们需要的每一章节的url以及标题,我们需要把每个章节的标题以及url都提取出来,那么我们就需要类似的提取标题一样的方法将其提取出来:
chapter_info=re.findall('<a href="(.*?)" title="(.*?)">.*?</a>',html)
print(chapter_info)
所有的章节的url以及标题都被提取出来了,然后就是依次的进行访问。
小说内容的爬取与内容保存到txt:
在上面的每个小说章节的url都被提取出来啦剩下的就是依次访问啦,可能你们以及注意到了,除了第一个我们提取的url中只有一半是不能正常访问的,会报错,所以我们把残缺的内容补上就好了,问题又来了如果我们全在访问前补全网址我们第一个正确的url也会出错,无法正常访问,问题是无穷无尽的我们在不断学习的过程中发现问题解决问题,这就是学习的过程,正好第一个是网站的主页,是我们不需要的,我们可以chapter_info.pop(0)把第一个删除了,也可以在特判第一个不补全,但是我采用的是try:except:语句,这样如果我们不但可以解决第一个有出错的的问题,又可以处理在在不是第一个url无法访问的时候出错了我们还可以爬取下一章节,十分强大。
对于写入txt文档,就是按照模板来就好啦,先写入标题,然后访问每一个章节的url爬取小说的内容,可气的是最后的一章和前面的所有章节都有一个不同点,那就是前面的章节都是<p>(一自然段)</p>唯独只有最后一个章节是<P>(一自然段)</P>,最开始我还没发现,我看成果的时候才发现,最开始我用的是
re.findall(r'[<P>|<p>] (.*?)[<P>|<p>]',chapter_html);
最后一章的确可以爬取啦,不过就是最后一章每一自然段都会差那么一段而且还有部分乱码,不知道为什么,最后改成现在这样就啥问题没有了,难受。然后就是可能是配置问题我爬取的内容中的有些符号会便成代码为了让我的爬取的小说更加美观我们需要把这些代码都替换回来。
访问url都是一样的我就不说细说啦看代码:
fp=open('%s.txt'%title,'w',encoding='utf-8')#创建这个txt,%s十分智能2333
fp.write(title)#先将标题写入文档
fp.write('\n\n')#两个回车
for chapter in chapter_info:
chapter_title=chapter[1]
#由于正则表达式中有两个(.*?)所以章节都是二维列表 0是标题 1是url
chapter_url='http://www.tianyashuku.com' +chapter[0]#补全url
print(chapter_url,chapter_title)#打印url以及标题,这样在爬虫的时候我们能看我们爬取到哪里了
try:
chapter_response=requests.get(chapter_url,send_headers)
chapter_response.encoding='utf-8'
chapter_html=chapter_response.text
chapter_response.close()
#print(chapter_html)
chapter_content=re.findall(r'<[P/p]> (.*?)</[P/p]>',chapter_html);
#匹配每一自然段
fp.write(chapter_title)
fp.write('\n')#写入每一章节的标题并回车
try :
for content in chapter_content:
#因为正则表达式的原因我们爬取每一个章节的内容都是每一个元素为一自然段的列表,所以我们需要在来一个循环来写入
#print(content)
temp=str(content)
temp=temp.replace('·','.')
temp=temp.replace('”','”')
temp=temp.replace('“','“')
temp=temp.replace('…','…')
temp=temp.replace('—','—')
temp=temp.replace('’','’')
temp=temp.replace('‘','‘')
#标点符号替换标点符号代码
fp.write(temp)
fp.write('\n ')
print("成功访问并写入:%s"%chapter_title)
fp.write('\n')
except:
print("写入出错!")
except:
print("访问失败!")成果:
完整代码:
import requests
import re
import time
import socket
socket.setdefaulttimeout(10)
novl_url='http://www.tianyashuku.com/wuxia/7/'
send_headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36",
"Connection": "keep-alive",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8",
"Accept-Language": "zh-CN,zh;q=0.8"
}#伪装成浏览器
#小说的url
response=requests.get(novl_url,send_headers)#访问
response.close()
response.encoding='utf-8'
html=response.text
#print(html)
title=re.findall('<title>(.*?)</title>',html)[0]
fp=open('%s.txt'%title,'w',encoding='utf-8')
print(title)
fp.write(title)
fp.write('\n\n')
chapter_info=re.findall('<a href="(.*?)" title="(.*?)">.*?</a>',html)
for chapter in chapter_info:
chapter_title=chapter[1]
chapter_url='http://www.tianyashuku.com' +chapter[0]
print(chapter_url,chapter_title)
try:
chapter_response=requests.get(chapter_url,send_headers)
chapter_response.encoding='utf-8'
chapter_html=chapter_response.text
chapter_response.close()
print(chapter_html)
chapter_content=re.findall(r'<[P/p]> (.*?)</[P/p]>',chapter_html);
fp.write(chapter_title)
fp.write('\n')
try :
for content in chapter_content:
temp=str(content)
temp=temp.replace('·','.')
temp=temp.replace('”','”')
temp=temp.replace('“','“')
temp=temp.replace('…','…')
temp=temp.replace('—','—')
temp=temp.replace('’','’')
temp=temp.replace('‘','‘')
fp.write(temp)
fp.write('\n ')
print("成功访问并写入:%s"%chapter_title)
fp.write('\n')
except:
print("写入出错!")
except:
print("访问失败!")
#fp.close()
print(len(chapter_info))爬取的小说(95w字,10s不到,2.9MB23333):
