学习时间:2019/10/25 周五晚上22点半开始。
学习目标:Page188-Page217,共30页,目标6天学完,每天5页,预期1029学完。
实际反馈:X集中学习1.5小时,学习6页。实际XXX学完,耗时N天,M小时
数据准备工作:加载、清理、转换以及重塑,通常会占用分析师80%的时间或更多!!!学会高效的数据清洗和准备,将绝对提升生产力!本章将讨论处理缺失数据、重复数据、字符串操作和其他分析数据转换的工具。下一章将关注用多种方法合并、重塑数据集。
7.1 处理缺失数据
缺失数据在pandas中呈现的方式有些不完美,但对于大多数用户可以保证功能正常。
对于数值数据,pandas使用浮点值NaN(Not a Number)表示缺失数据。称其为哨兵值,可以方便地检测出来:
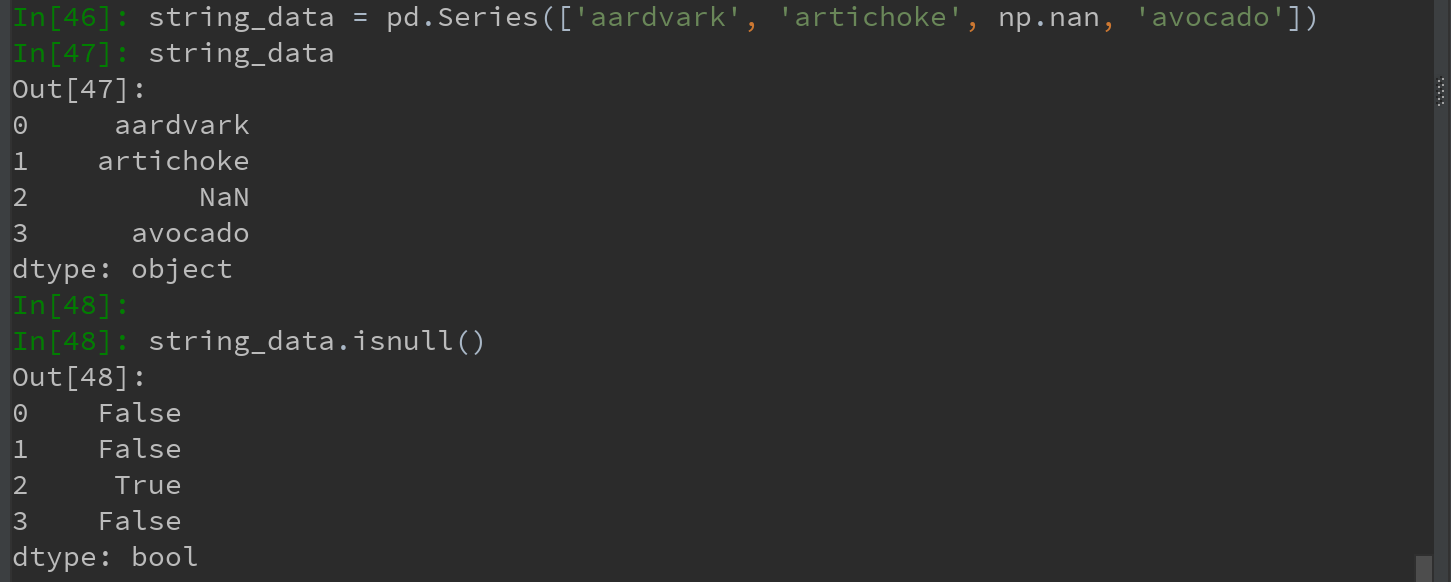
在pandas中,将缺失值表示为NA(R语言地惯用法),表示not available。NA数据可能是不存在地数据或虽然存在但没有观察到。(进行数据清洗时,为便于分析最好直接对缺失数据进行分析,以判断数据采集地问题或缺失胡数据可能导致的偏差。)
Python内置的None值在对象数据中也可以作为NA:

表7-1 一些关于缺失数据处理的函数

7.1.1 滤除缺失数据
过滤缺失数据,用dropna更为实用(也可通过pandas.isnull或布尔索引的手工方法)
对于Series,dropna返回一个仅含非空数据和索引值的Series:

等价于:

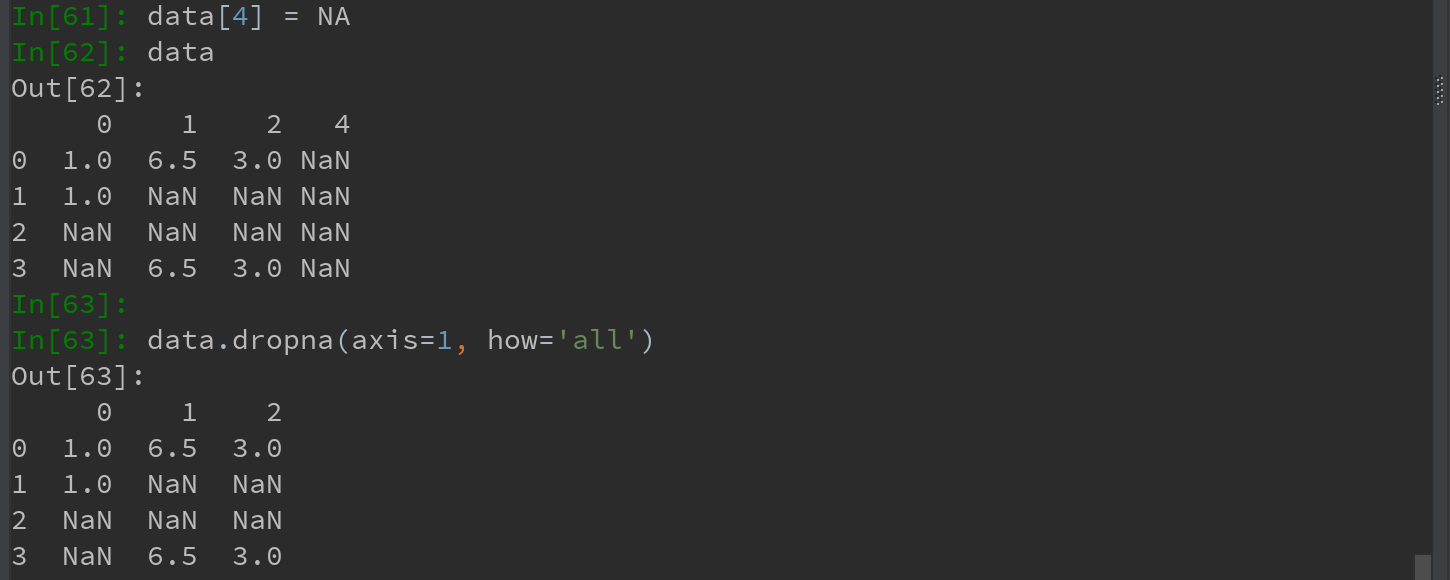
对于DataFrame对象, dropna默认丢弃任何含有缺失值的行:

1)传入 how = 'all' 将只丢弃全为NA的行:

2)传入 axis = 1,将丢弃含有NA的所有列,如果同时传入 how = 'all' 则会丢弃全为NA的列:
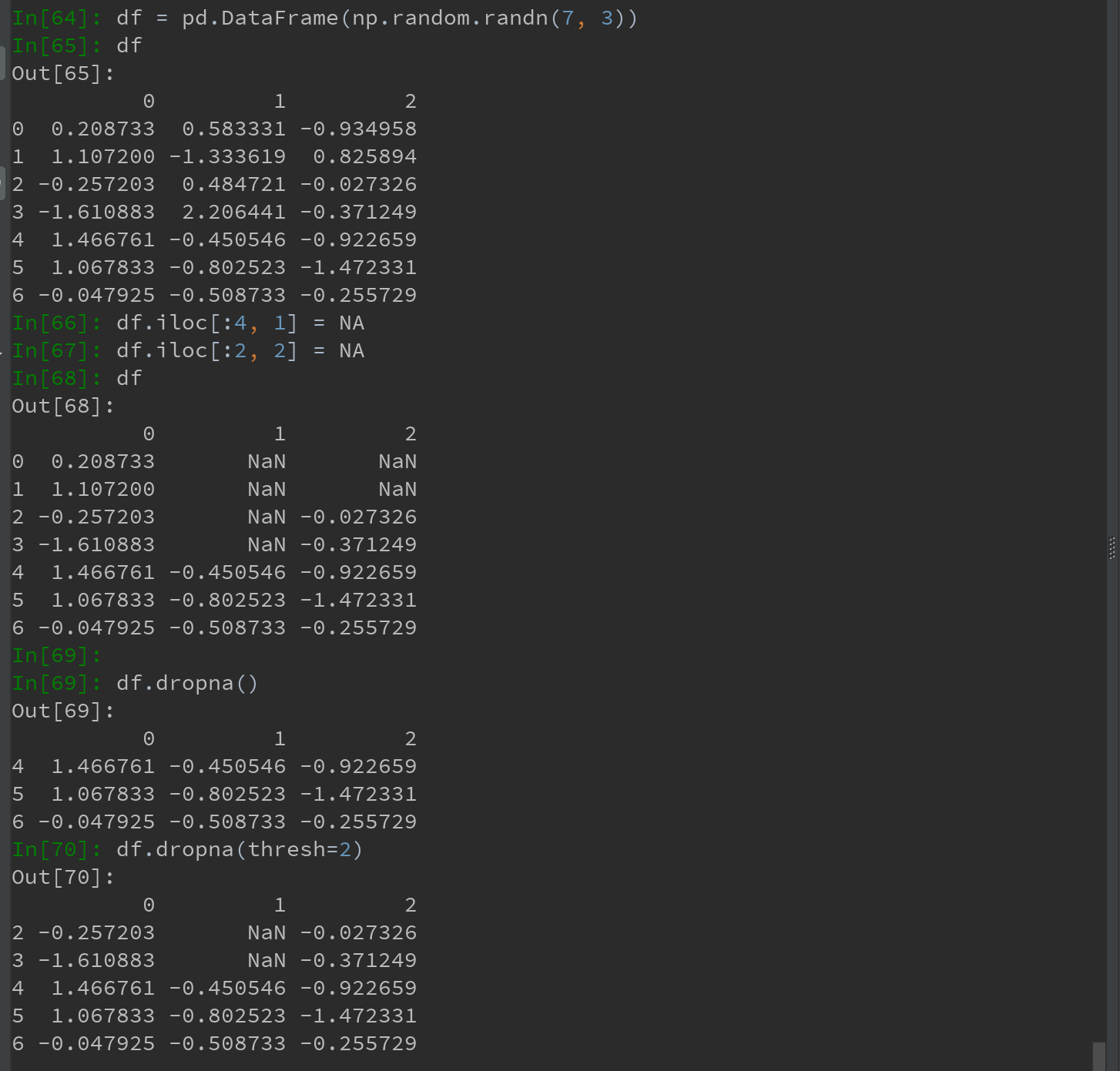
3)另一个滤除DataFrame行的问题涉及时间序列数据。假设需要留下一部分观测数据,可用 thresh=N 参数实现此目的(丢弃前N行含有NA的行,对于列如何处理???):
7.1.2 填充缺失数据
如果不想滤除缺失数据,而是希望通过其他方式填补哪些缺失数据,则fillna方法是最主要的函数。通过一个常数调用fillna就会将缺失值替换为该常数:
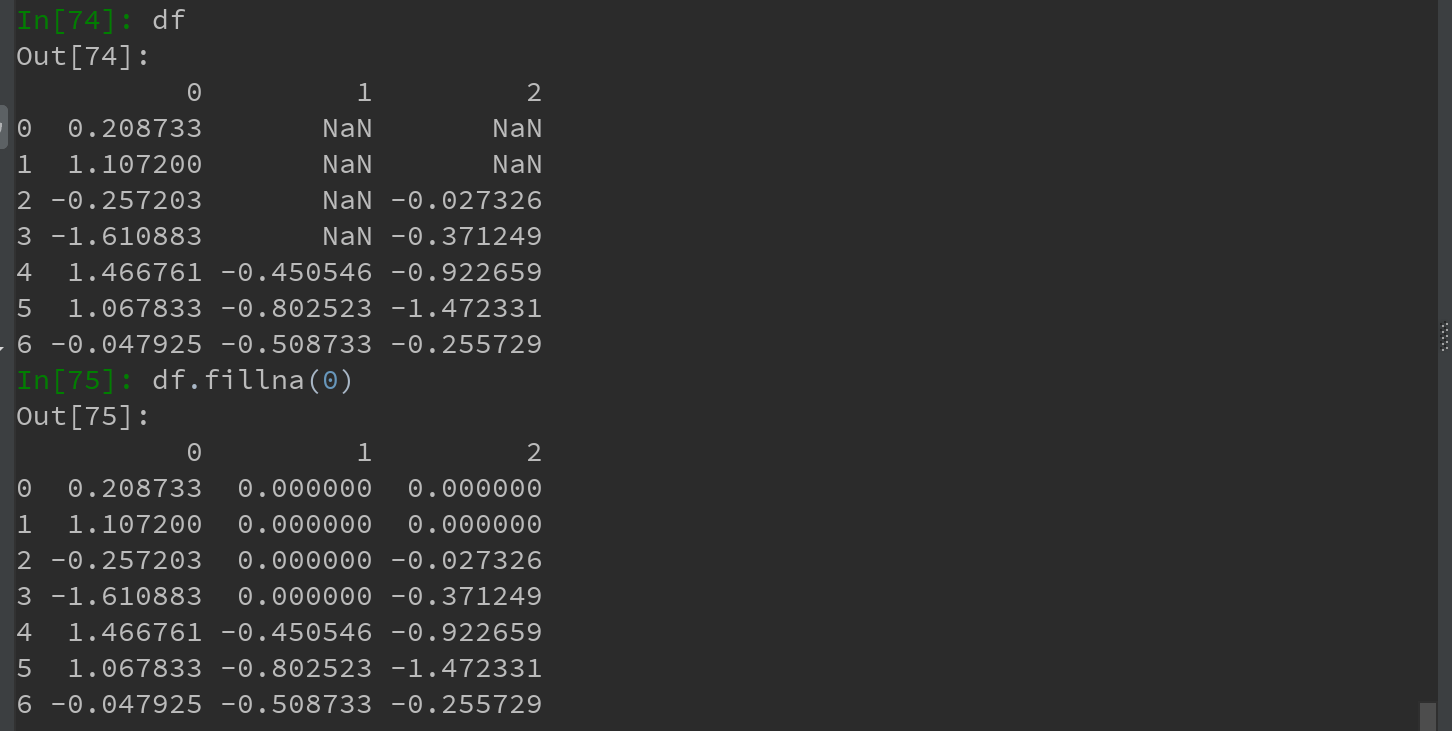
通过一个字典调用fillna,可实现对不同列填充不同的值:
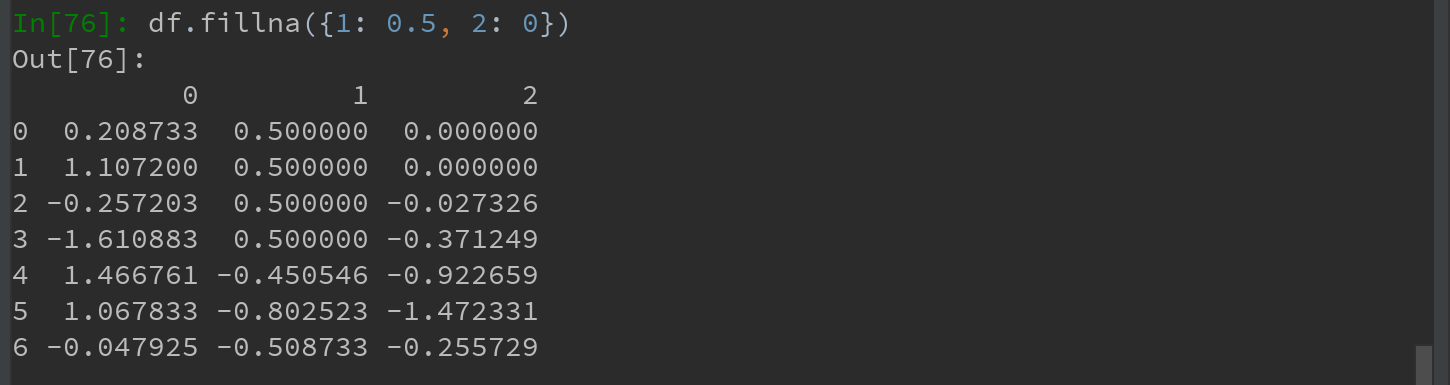
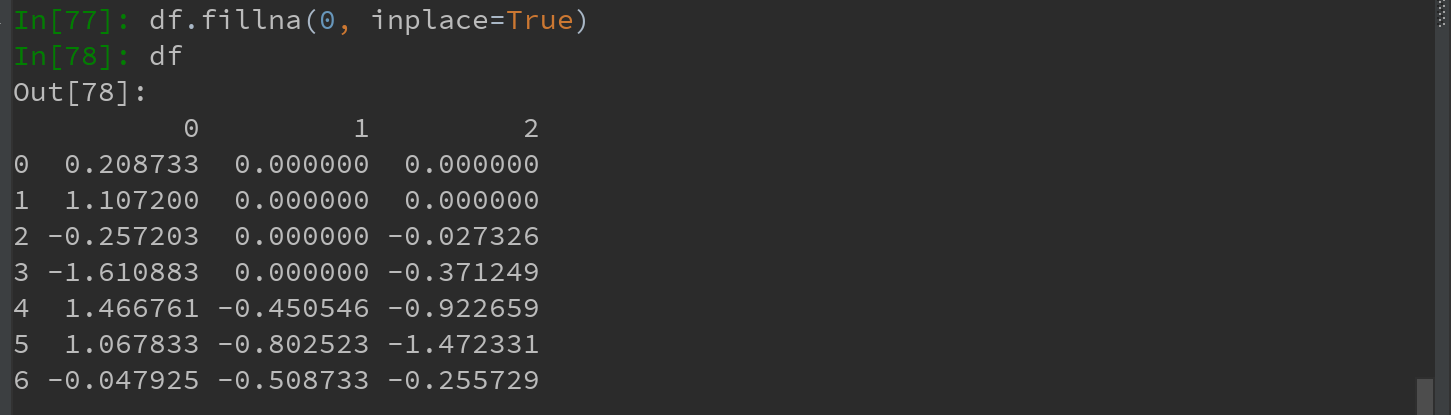
fillna默认会返回新对象,如果想对现有对象进行就地修改,则可以通过传入 inplace = True实现:
对reindex(书中为reindexing,是否有误?)有效的插值方法,同样适用于fillna:

7.2 数据转换
7.2.1 移除重复数据
7.2.2 利用函数或映射进行数据转换
7.2.3 替换值
7.2.4 重命名轴索引
7.2.5 离散化和面元划分
7.2.6 检测和过滤异常值
7.2.7 排列和随机采样
7.2.8 计算指标和哑变量
7.3 字符串操作
7.3.1 字符串对象方法
7.3.2 正则表达式
7.3.3 pandas的矢量化字符串函数
7.4 总结
高效的数据准备,可以为数据分析留出更多时间。下一章,将学习pandas的聚合与分组。