一、思路
语义分割既需要丰富的空间信息,又需要较大的感受野。然而,现代方法通常会牺牲空间分辨率来实现实时推理速度,导致性能低下。本文提出了一种新的双边分割网络(BiSeNet)来解决这一难题。我们首先设计一个空间路径以较小的步幅保存空间信息并生成高分辨率特征。同时,采用快速下采样策略的上下文路径获取足够的接受域。在此基础上,提出了一种新的特征融合模块,实现了特征的有效融合。
二、语义分割研究现状
实时语义分割的算法表明,模型的加速方法主要有三种。1)尝试通过裁剪或调整大小来限制输入大小,降低计算复杂度。虽然该方法简单有效,但空间细节的丢失会破坏预测,特别是边界附近的预测,导致度量和可视化精度下降。2)一些工作不是调整输入图像的大小,而是对网络的通道进行修剪以提高推理速度,特别是在基础模型的早期阶段。然而,它削弱了空间能力。3)对于最后一种情况,ENet建议放弃模型的最后一个阶段,追求一个非常紧密的框架。然而,这种方法的缺点是显而易见的:由于ENet在最后阶段放弃了向下采样操作,模型的接受域不足以覆盖较大的对象,导致识别能力较差。总的来说,以上方法都是在精度和速度之间进行折衷,在实际应用中效果较差。
为了弥补上述空间细节的损失,研究者们广泛采用了U型结构。通过融合骨干网的层次特征,u形结构逐渐提高了空间分辨率,填补了一些缺失的细节。然而,这种技术有两个缺点。
1)由于在高分辨率地形图上引入了额外的计算,完整的u型结构会降低模型的速度。2)更重要的是,通过下图(b)所示的浅层,大部分在修剪或剪切过程中丢失的空间信息很难恢复。换句话说,u型技术更像是一种减轻,而不是一种必要的解决方案。
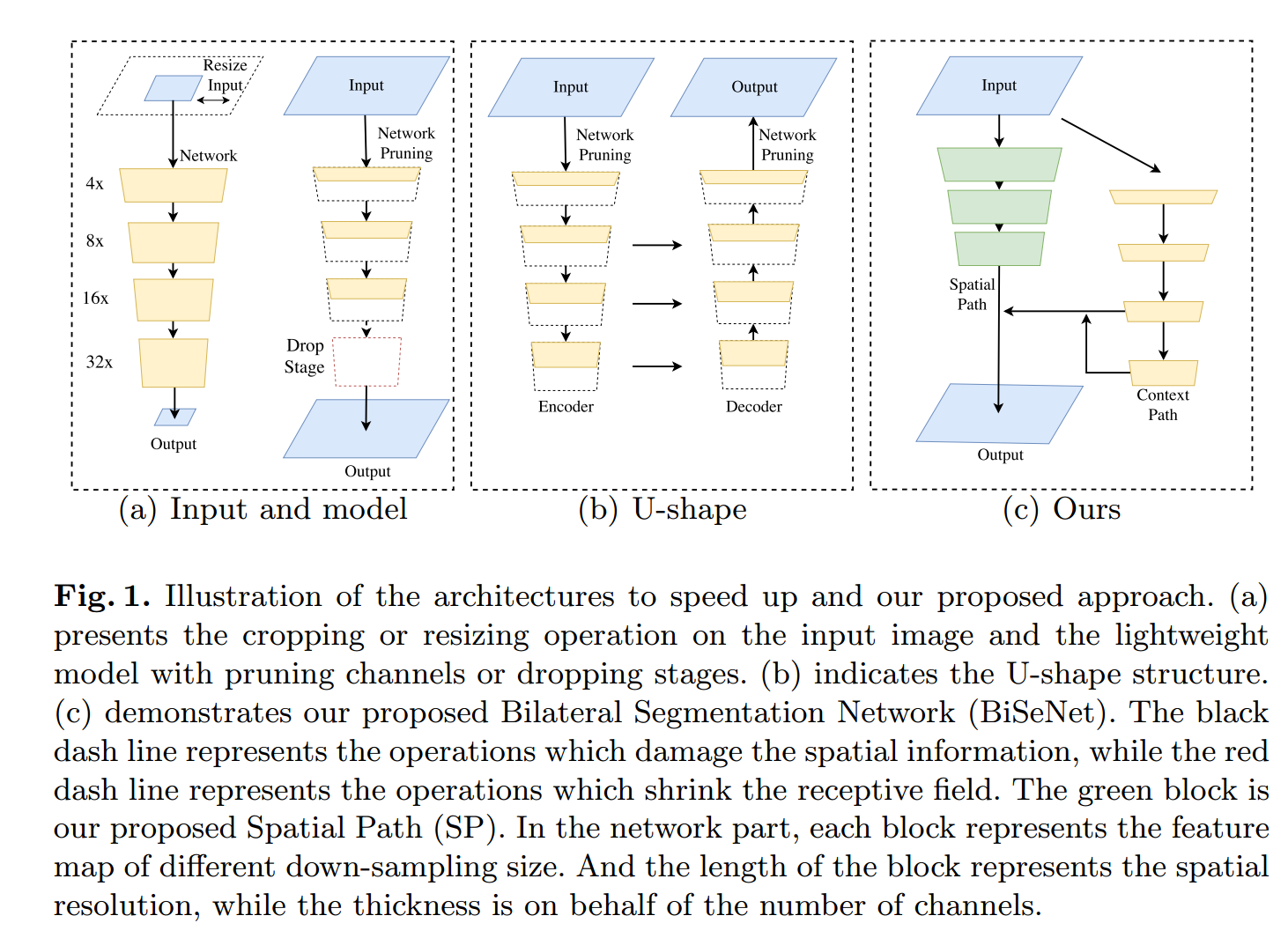
在此基础上,我们提出了由空间路径(SP)和上下文路径(CP)两部分组成的双边分割网络(BiSeNet)。正如它们的名字所暗示的,这两个组成部分被设计用来分别应对空间信息的丢失和接受域的收缩。这两条道路的设计理念是明确的。对于空间路径,我们仅将3个卷积层叠加得到1/8的feature map,它保留了丰富的空间细节。在上下文路径方面,我们在Xception[8]的尾部附加了一个全局平均池层,其中接受域是主干网络的最大值。上图(c)显示了这两个组件的结构。
为了在不损失速度的情况下获得更好的精度,我们还研究了两种路径的融合以及最终预测的细化,提出了特征融合的方法分别为注意细化模块(FFM)和注意细化模块(ARM)。
三、限制语义分割模型的原因
丰富的空间信息或扩大接受域

空间信息:卷积神经网络(CNN)[16]通过连续的下采样操作来编码高级语义信息。然而,在语义分割任务中,图像的空间信息是预测细节输出的关键。现代现有的方法致力于编码丰富的空间信息。DUC [32], PSPNet [40],DeepLab v2[5]和DeepLab v3[6]使用扩展卷积来保持特征图的空间大小。全局卷积网络[26]利用了“大核”,扩大感受野。
U型方法:u型结构[1,10,22,24,27]可以恢复一定程度的空间信息。原始的FCN[22]网络通过一个跨跃连接的网络结构来编码不同层次的特征。一些方法将其特有的细化结构转化为u形网络结构。[1,24]利用反卷积层创建u形网络结构。U-net[27]为这个任务介绍了有用的跳跃连接网络结构。全局卷积网络[26]将u型结构与大核相结合。LRR[10]采用拉普拉斯金字塔重构网络。RefineNet[18]增加了多路径细化结构来细化预测。DFN[36]设计了一个通道注意块来实现特征选择。然而,在u型结构中,一些丢失的空间信息是不容易恢复的。
上下文信息:语义分割需要上下文信息来生成高质量的结果。大多数常用的方法是扩大接受域或融合不同的上下文信息。[5,6,32,37]利用卷积层中不同的膨胀率来捕获不同的上下文信息。在图像金字塔的驱动下,语义分割网络结构通常采用多尺度特征集成。在[5]中,提出了一个“ASPP”模块来捕获不同接受域的上下文信息。PSPNet[40]应用了一个PSP模块,它包含了几个不同规模的平均池化层。[6]设计了一个带有全局平均池的ASPP模块来捕获图像的全局上下文。[38]通过自适应卷积层对神经网络进行改进,获得自适应的场环境信息。DFN[36]将全局池添加到u形结构的顶部以对全局上下文进行编码。
注意力机制:注意机制可以利用高层信息来引导前馈网络[23,31]。在[7]中,CNN的注意力取决于输入图像的尺度。在[13]中,它们将通道注意力机制应用于识别任务,达到了最先进的水平。像DFN[36]一样,他们学习全局上下文作为注意力并修改特性。
四、感受野
在卷积神经网络CNN中,决定某一层输出结果中一个元素所对应的输入层的区域大小,被称作感受野Receptive field。
感受野大才能充分考虑图片信息,使得分割结果完整、精确。
网络深,感受野就大,设置Context Path, 采用Resnet, Xception等骨架网络,增加深度,扩大感受野。
五、网络框架
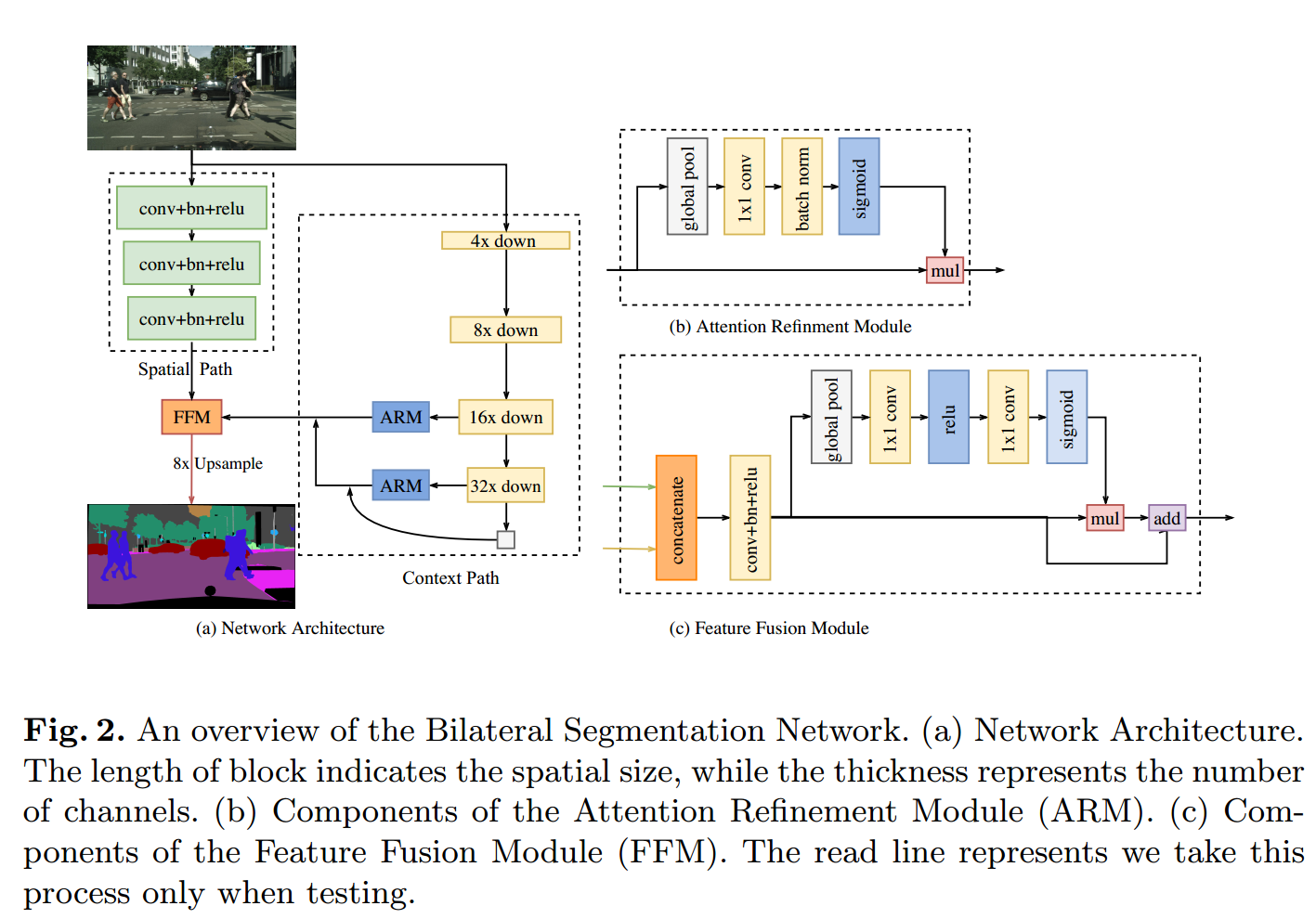
1、Spatial Path
每一层包含一个stride = 2的卷积,然后批量归一化[15]和ReLU[11],输出图像为原图的1/8。由于特征图的空间尺寸大,编码的空间信息丰富。
2、Context path
空间路径编码丰富的空间信息,而上下文路径的设计是为了提供足够的接受域。
包含一个深度骨架网络,用于模型调整的卷积网络,以及一系列注意力优化模块。值得一提的是采用了全局均值化来降低计算量,稳定最大感受野。
ARM(注意力优化模块)
在 Context Path 中,借助全局平均池化捕获全局语境,计算注意力向量,优化 Context Path 中每一阶段的输出特征,便于整合全局语境信息,大大降低计算成本。
3、(FFM)特征融合模块:
Spatial Path 捕获的空间信息编码了绝大多数的丰富细节信息,Context Path 的输出特征主要编码语境信息。两路网络的特征并不相同,因此不能简单地加权两种特征,要用一个独特的特征融合模块以融合这些特征。简而言之,两个路径的特征图直接叠加不合适,那就设定个卷积网络,去训练学习一下两部分如何叠加,如上图。
针对不同层次的特征,首先将空间路径和上下文路径的输出特征串联起来。然后利用批处理归一化[15]来平衡特征的尺度。接下来,我们将连接的特征集合到一个特征向量并计算一个权重向量,就像SENet[13]那样。该权向量可对特征进行重权,相当于特征的选择和组合。
六、总结
a、单独用Spatial path 来保留丰富的空间信息
b、Context Path 直接用预训练经典网络提取深层特征,扩大感受野,提取上下文信息
c、使用了一个ARM模块,优化 Context Path 中每一阶段的输出特征,便于整合全局语境信息
d、Context Path 与Spatial path的特征整合方式:FFM
e、Loss Function 中,对Context Path 另外做监督