GPT1
GPT1使用了无监督预训练-有监督微调的方法,基于Transformer解码器构建了一个在NLP领域上卓有成效的模型;是GPT2和GPT3的基础。
-
无监督框架
1)框架:使用语言模型进行预训练,使用n-gram方法对当前词进行预测;(使用前k个词进行预测第k个词,最大化出现可能性)
2) GPT和BERT都是使用Transformer作为模型的基础,但是GPT使用的是Transformer的解码器,而BERT使用的是编码器;
3)GPT使用的Transformer解码器的数学表达如下:
其中U表示的是token的上下文向量,We是token的embedding矩阵,Wp是位置编码矩阵;h0表示token的word embedding 和 position embedding的和(每一个tocken由单词含义和位置组成);hl是transformer decoder输出的结果;最后乘以一个WeT进行softmax可以得到分类的概率;
-
有监督微调
1)已知数据集 C C C的格式为 x 1 , . . . , x m − > y x^1,...,x^m -> y x1,...,xm−>y,其中 x 1 , . . . , x m x^1,...,x^m x1,...,xm为token,y为标签,数据经过预训练模型,输入到softmax层进行分类,得到模型预测结果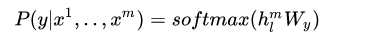 上图左边是Transformer block的结构示意图,因为就是Transformer的解码器所以文章中的介绍也非常简单;右边表示了如何应用GPT的预训练模型进行各种各样的微调,然后应用到不同的任务之中。
上图左边是Transformer block的结构示意图,因为就是Transformer的解码器所以文章中的介绍也非常简单;右边表示了如何应用GPT的预训练模型进行各种各样的微调,然后应用到不同的任务之中。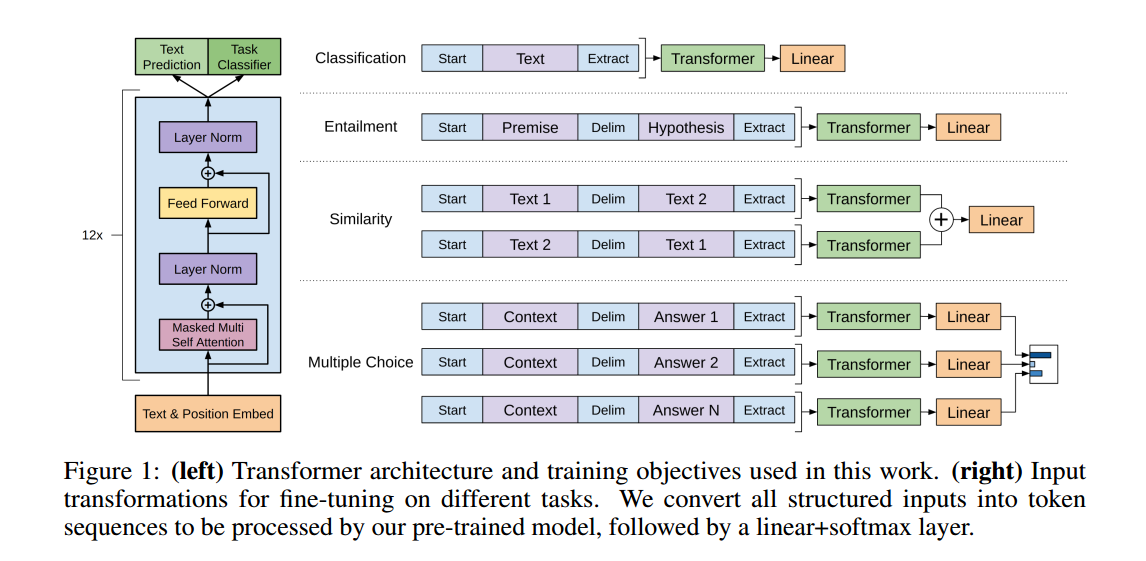
GPT2
- 核心思想:zero-shot,不需要进行监督学习就可以做到有监督学习可以做到地事情!!(用无监督预训练做有监督的工作)
1)语言模型的核心就是进行序列的条件建模 p ( s n − k , . . . , s n ∣ s 1 , s 2 , . . . s n − k − 1 ) p(s_{n-k},...,s_n \vert s_1,s_2,...s_{n-k-1}) p(sn−k,...,sn∣s1,s2,...sn−k−1)
2) 任何有监督的任务,都是在估计 p ( o u t p u t ∣ i n p u t ) p(output \vert input) p(output∣input),通常我们需要使用特定的网络结构去进行建模,但是如果做通用的模型,不同任务的网络结构相同,那么不同的只能是输入的数据。对于NLP任务的input和output我们可以用向量表示,对于不同地task,其实我们可以在input上面加上我们的task描述,也就是表示为 ( t r a n s l a t e t o f r e n c h , e n g l i s h t e x t , f r e c h t e x t ) (translate to french,english text,frech text) (translatetofrench,englishtext,frechtext),或者表示为 ( a n s w e r t h e q u e s t i o n , d o c u m e n t , q u e s t i o n , a n s w e r ) (answer the question, document,question,answer) (answerthequestion,document,question,answer) - 细节
- 数据收集,现有的语料数据库存在很多的问题,包括数据量和数据质量,OpenAI团队搜集了40GB的高质量数据
- Word-Level做embedding需要解决OOV(out of Vocabulary 数据中的词不在预训练模型之中),而char-level的模型效果没有word-level的好。作者团队选择了一种折中的方法:将罕见词拆分为子词
- 模型相对于GPT1的改变:
- layer norm放到了每个sub-blcok前面
- 残差层的参数初始化根据网络深度进行调节
- 扩大了字典、输入序列长度、batchsize
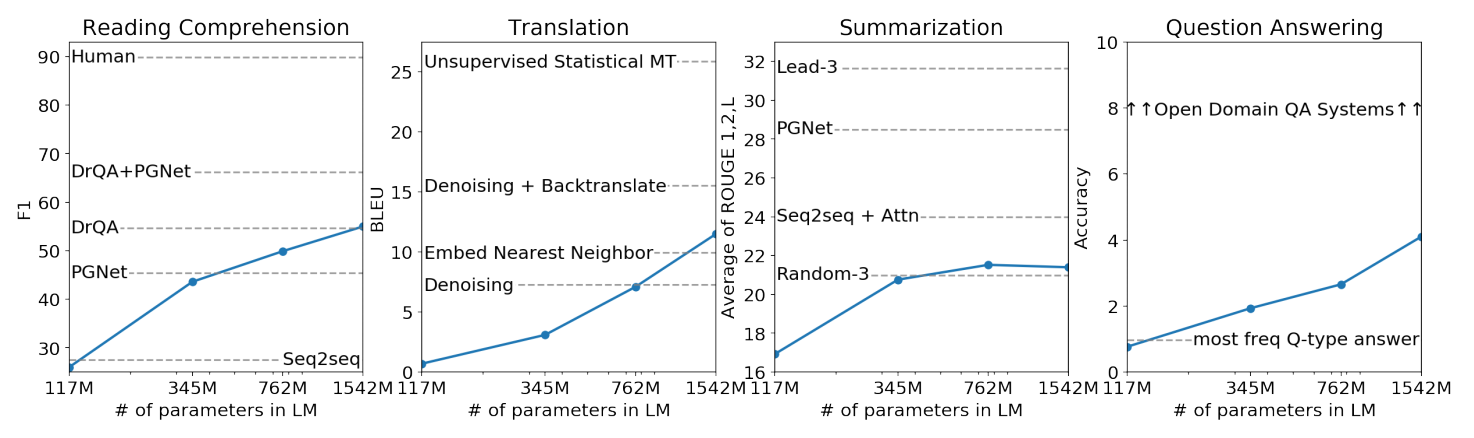
GPT3
GPT3是那个被大家玩儿出花的工作,其参数量达到了1700亿
GPT2的一大卖点是:zero-shot,但是GPT3的工作发现在增加参数量的情况下进行few-shot的效果会更好,也就是说在预训练的模型上给定一定的监督数据进行微调得到的效果会好很多。所以个人认为GPT3的创新性在于使得巨大的网络结构可以应用于各种不同的任务(注意这里的微调不会改变网络的参数,因为参数量巨大微调的时候也不会计算梯度)
GPT3的网络结构和GPT2相同,但是训练数据扩大了100倍,OpenAI在数据处理上下了很多的功夫,包括对底质量数据进行QC、去重等等。