STL容器由于各自用途的不同,底层实现的数据结构也有所不同。
具体来讲,容器的主要用途就是对其中存储的数据进行“增删改查”。那么不同的数据结构的设计,增删改查的效率是不一样的。
下面是《The C++ Standard Library 2nd》的一个截图,

我们可以看到,STL容器的类型可以分为两种:序列容器和关联容器。
关联容器中又包括不定序容器。不定序容器是指元素在容器中的位置是不确定的,也就是减少了关联容器的排序的过程,对于不需要排序的数据来讲,效率会更高一些。
下面分别讨论下。

从图中可以看出来,stl中的array是固定大小容器,底层实现是C-Style array。
这个容器和vector和C类型数组的功能类似,那么它的优势在哪?
1、和std::vector相比,std::array是静态数组实现,在编译时就可以确定大小,所以没有vector的容量动态扩充时的消耗。当然也就没有vector灵活。
2、和C-Style array相比,
std::array保持了和一般STL容器的一致的接口函数,迭代器,这样可以更好的利用STL的算法,在使用上也更为灵活。
std::array不会隐式转成指针,在作为参数传递时,也不会丢失大小信息。

底层也是数组,和array不同的是可以动态改变大小。
内存连续。所以可以通过迭代器,指针和偏移量来随机访问。
容量动态扩充。当插入新的元素时,如果空间不足,会重新申请一块2倍于当前容量的内存,并和当前内存空间做交换。原来的指针和引用会失效。

双端队列。从上面这个图可以看出来,deque可以实现两端的插入和删除,同时又支持随机访问。但其实底层实现比上面这张图实现的更复杂。
以下这个图很好的阐明了底层的实现,转自知乎
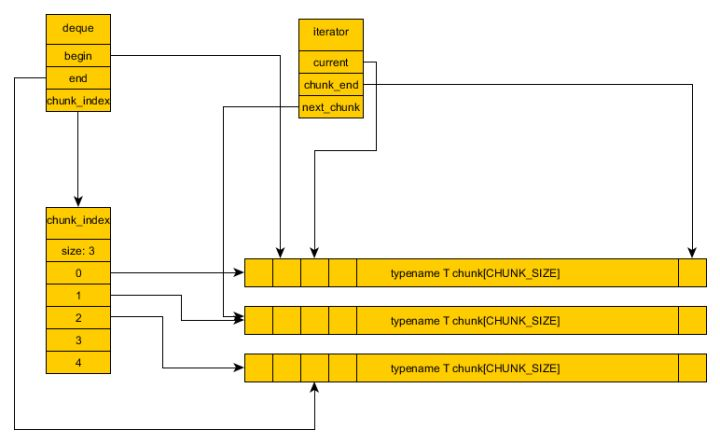
1. deque是由多块不连续的内存chunk组成的,再用一个表来存储索引每一个chunk,数据存储在chunk中,每个chunk的大小是相同的。
这样设计最重要的原因是:
同时保证在两端的插入删除和随机访问可以在常量时间内完成。
这其实兼容了vector的随机访问和后面要提到的list常量时间插入删除的优点。
2. deque可以做到动态大小。但是又不像vector需要重新申请内存和内存交换。
3. deque的随机访问需要做两次定位。先查询索引表,再查询chunk中的偏移。
std::queue和std::stack是对deque的封装。

前者双向链表,后者单向链表。
由于是链表,所以两个容器都可以实现O(1)的任意位置的插入和移除。但都不支持随机访问。
前者提供双向迭代器,同时在空间上占用的更多。
后者只提供在头部插入和删除,空间占用比list更高效,如果只需要在一端操作,forward_list更适合。
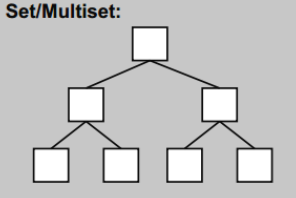

std::set, std::map, std::multiset, std::multimap
关联型容器底层实现都是红黑树。
为什么要使用红黑树呢?因为关联型容器对查询的效率要求很高。而红黑树是一种自平衡二叉搜索树(属于二叉搜索树 BST)。
我们知道在BST中,左子树小于父节点,右子树大于父节点。所以查询就是遍历节点的过程。如果树的结构是平衡二叉树,也就是节点的高度之间不会大于2,那么查询的复杂度就是O(logn),这还不仅是平均时间复杂度,在最坏的情况下也是如此,因为平衡。
红黑树通过一些规则限制,保证节点在创建,插入和删除后,依然能保持平衡。
所以这些关联型容器的插入,查询,删除的时间复杂度都是O(logn)
后面我要总结一篇红黑树的文章。
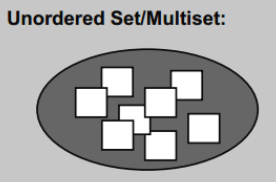

std::unordered_set, std::unordered_map
这两个也是关联型容器,不同的是内部存储的数据并不按照一定的顺序排列。
为了实现平均时间复杂度O(1)的搜索,插入和删除,底层的实现采用哈希表的方式。
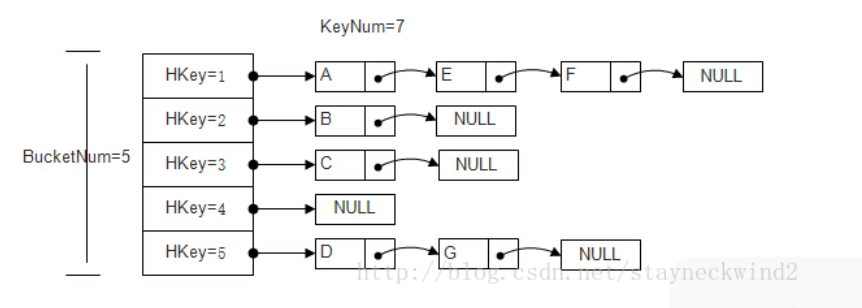
链地址法:HashTable由多个bucket组成,bucket以hashkey为索引,bucket里面存储的是相同hashkey的元素。