网络爬虫学习,仅作笔记
1. 面向对象
1.1 类定义 , 属性 , 初始化
1. 面向对象最重要的概念就是类(Class) 和实例(Instance), 面向对象编程是一种编程设计思想.
class Cat: """这是一个猫类""" # class 关键字 # Cat 类名 同变量名 大驼峰命名法 # 三引号中的内容是解释这个类的用途
2. 实例化对象
kitty = Cat()
3. 属性
kitty = Cat() #添加属性 kitty.color = 'white' kitty.eat = 'fish'
4. 实例化--初始化
#Cat实例化 class Cat: """猫类""" #初始化方法 def __init__(self, color ,eat): self.color = color self.eat = eat kitty = Cat('white','fish')
1.2 类和函数
#类和函数 class Point: """表示二位平面中的一个点""" #初始化方法 def __init__(self, x ,y): self.x = x self.y = y def distance(self , p2): return ((self.x-p2.x)**2 + (self.y-p2.y)**2)**0.5 def print_point(self): print('%s,%s'%(self.x,self.y)) pp1=Point(1,2) pp2=Point(3,5) Point.distance(pp1,pp2) #函数式调用方法,一般不这么用 Point.print_point(pp1) #对象的方式调用 pp1.print_point()
2. 网页解析
Web浏览器的作用是读取HTML文档,并以网页的形式显示出它们,浏览器不会显示HTML标签, 而是使用标签来解释页面的内容.
2.1 http解析库 BeautifulSoup4
BeautifulSoup 是一个可以从 html 或xml 文件中提取数据的Python库, 它的使用方式对于正则来说更加的简单方便, 常常能够节省我们大量的时间.
3.BeautifulSoup4
BeautifulSoup 是一个可以从html或xml文件中提取数据的Python库 ,它的使用方式相对于正则来说更加的简单方便,能够节省大量时间.
#规定格式 from bs4 import BeautifulSoup import requests zxc_url = 'http://image.baidu.com/search/index?tn=baiduimage&ipn=r&ct=201326592&cl=2&lm=-1&st=-1&fm=result&fr=&sf=1&fmq=1571316186692_R&pv=&ic=&nc=1&z=&hd=&latest=©right=&se=1&showtab=0&fb=0&width=&height=&face=0&istype=2&ie=utf-8&sid=&word=赵小臭' response =requests.get(zxc_url) response.encoding='utf-8' zxc = response.text #解析html soup = BeautifulSoup(zxc) #取标签 soup.head #取标签带属性 soup.p['class'] #查所有标签 soup.find_all('a')
解析器:

节点对象:
1.tag ---tag就是标签的意思, tag还有许多的方法和属性
>>>soup = BeautifulSoup('<b class="boldest">Extremely boldd</b>') >>>tag = soup.b >>>type(tag) <class 'bs4.element.Tag'>
2.name ---每一个tag对象都有name属性,为标签的名字
>>>tag.name 'b'
3.Attributes ---在html中, tag可能有多个属性, 所以tag属性的取值跟字典相同.#如果某个tag属性有多个值,那么返回的则是列表格式.['?','??']#
>>>tag['class'] 'boldest'
>>>soup = BeautifulSoup('<p class="body strikeout"></p>')
>>>soup.p['class']
["body","strikeout"]
4.get_text() ---通过get_text() 方法可以获取某个tag 下所有的文本内容.
soup.body.get_text() ##暂不演示###```(懒得打字)
5.NavigableString ---NavigableString 可以遍历字符串,一般被标签包裹在其中的文本就是NavigableString 格式.
>>>soup = BeautifulSoup('<p>No longer bold</p>') >>>soup.p.string 'No longer bold' >>>type(soup.p.string) bs4.element.NavigableString
4.Tag与遍历文档树
tag 对象可以说是BeautifulSoup 中最为重要的对象,通过beautifulSoup来提取数据基本都围绕着这个对象来进行操作.
contents和children:
通过contents 可以获取某个节点的所有的子节点,包括里面的NavigableString对象,获取的是列表格式.###[<title>?</title>]###
而通过children同样的是获取某个节点的所有子节点,返回的是一个迭代器,这种方式会比列表格式更加节省内存.###<title>?</title>###
>>>soup.head.contents [<title>The Dormouse;s story</title>] >>>tags = soup.head.children >>>tags <list_iterator at 0x110f76940> >>> for tag in tags: >>> print(tag) <title>The Dormouse's story</title>
descendants:
上面的contents和children获取是某个节点的直接子节点,而无法获得子孙节点,通过descendants可以获得所有子孙节点,返回的结果跟children一样,需要迭代或者转类型使用.
>>>len(list(soup.body.descendants)) 19 >>>len(list(soup.body.children)) 6
string 和 strings:
string 获取1个字符串, strings 获取所有字符串,返回的是列表类型.
>>>soup.title.string "The Dormouse's story" >>>list(soup.body.strings) ["","","",""....]##多个,懒得打字##
父节点parent 和parents:
parent 获取某个节点的父节点,也就是包裹当前节点的节点
parents 获取当前节点递归到顶层的所有父辈元素
>>>soup.b.parent <p class="title"><b>The Dormouse's story</b></p> >>>[i.name for i in soup.b.parents] ['p','body','html','[document]']
兄弟节点: 是指父节点相同的节点.
next_sibling 和 previous_sibling(加s同上取所有):
next_sibling是获取当前节点的下一个兄弟节点,previous_sibling 是获取当前节点的上一个兄弟节点.
##兄弟节点中排第一个的节点没有上一个节点(previous),最后一个节点没有下一个节点(next)##
>>>soup.head.next_sibling '\n' >>>soup.body.previous_sibling '\n'
find_all(): find_all()方法基本所有节点对象都调用.
1. 通过name搜索
>>>soup.find_all('b')
[<b>The Dormouse's story</b>]
>>>soup.find_all(["a","b"])
[<b>...</b>,<a>...</a>....]#懒得打字#
2. 通过属性搜索
>>>soup.find_all(attrs={'class':'sister'})
[<a class="sister">.......</a>,<a class="sister">......</a>,.....]
3. 限制查找范围为子节点
>>>soup.html.find_all('title') [<title>The Dormouse's story</title>] #recursive 参数设置为False,可以将搜索范围限制在直接子节点中 >>>soup.html.find_all("title", recursive=False) []
5. XPath
XPath 是一门在XML文档中查找信息的语言,XPath可用来在XML文档中对元素和属性进行遍历.相比于BeautifulSoup, XPath在提取数据时会更有效率.
XPath 使用路径表达式来选取XML文档中的节点或节点集,节点是通过沿着路径(path)或者步(steps)来选取的.
from lxml import etree page = etree.HTML(html_doc) #返回HTML节点 #html_doc 是html页面
选取节点:
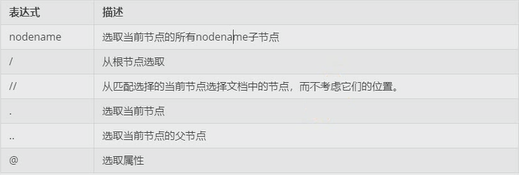
1. 查找当前节点的所有子节点
print(page.xpath('head')) [<Element head at 0x7fd65143ef88>]
2. 从跟节点进行查找
print(page.xpath('/html'))
3. 从整个文档中查找,不考虑位置
print(page.xpath('//book'))
4. 选取当前节点的父节点
print(page.xpath('//book')[0].xpath('..'))
5. 选取当前节点名为category属性的所有值
print(page.xpath('//book')[0].xpath('@category'))
----------------------------------------------------------------------------------------------------------------

选取未知节点:
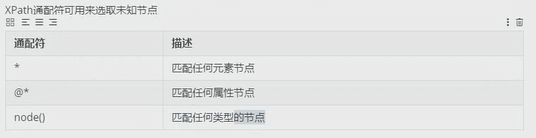
获取节点中的文本:
1. 用text()获取某个节点下的文本
print(page.xpath('//book[1]/author/text()'))
2. 用string()获取某个节点下所有的文本
print(page.xpath('string(//book[1])'))
MAX.小说爬取案例1:
利用requests+re爬取一篇小说
#爬取一篇小说 #导入相应库 import requests import re #小说主页的url 地址 novel_url='http://www.quanshuwang.com/book/0/567' #1. 下载小说的信息 response = requests.get(novel_url) #2. 设置html编码 response.encoding='gbk' novel_html=response.text #3. 解析小说的名称 novel_title = re.findall(r'class="article_title">(.*?)<',novel_html)[0] #4. 解析章节名称 和 url #[(url1,第一章),(url2,第二章)......] re.S 可匹配不可监测字符,空,换行,取章节DIV div_html = re.findall(r'class="clearfix dirconone">(.*?)</DIV>',novel_html,re.S)[0] chapter_info= re.findall(r'<a href="(.*?)" title="(.*?)">',div_html) #下载每一章的内容,存为一个txt文档 with open(r'C:\Users\luowe\Desktop\%s.txt'%novel_title , 'w' , encoding='utf-8') as f: #chapter_info是列表,[(1,2),(3,4)....]格式,url接收第一个(1),title接收第二个(2) for chapter_url ,chapter_title in chapter_info: #在文档中写入标题,并换行 f.write(chapter_title+'\n') #下载章节内容,打开了新url response = requests.get(chapter_url) response.encoding='gbk' #设置编码,防止乱码 #接收页面html,并解析 novel_html = response.text #因为内容中有回车换行,所有要加re.S验证,返回的列表,只取第一个[0] novel_content = re.findall(r'style5\(\);</script>(.*?)<script',novel_html, re.S)[0] #清洗数据 novel_content = novel_content.replace(' ',' ') #去空格 novel_content = novel_content.replace('<br />',' ') #去标签 novel_content = novel_content.replace('\r\n','') #去空去换行 #写入文档,每写入一章,换一行 f.write( novel_content + '\n') print(chapter_title, chapter_url)
MAX.小说爬取案例2:
利用BeautifulSoup爬取一篇小说
#爬取一篇小说 #导入相应库 import requests from bs4 import BeautifulSoup as be #小说主页的url 地址 novel_url='http://www.quanshuwang.com/book/9/9006' #1. 下载小说的信息 response = requests.get(novel_url) #2. 设置html编码 response.encoding='gbk' novel_html=response.text #3. 利用BeautifulSoup解析网页,,小说的名称 novel_soup = be(novel_html, 'lxml') novel_title_a = novel_soup.find_all('a',attrs={'class':'article_title'})[0] novel_title=novel_title_a.string #4. 解析出所有的章节a标签 div = novel_soup.find_all('div',attrs={"class":"chapterNum"})[0] chapter_tag_a = div.find_all('a') #5. 构造 章节信息 chapter_info=[] for tag_a in chapter_tag_a: chapter_info.append((tag_a['href'],tag_a.string)) #6. 去下载每一章的内容,存为一个txt文档 with open(r'C:\Users\luowe\Desktop\%s.txt'% novel_title,'w' , encoding='utf-8') as f: #6.1 循环下载每一章的内容,并写入到text文档中 for chap_url, chap_title in chapter_info: #6.2 在文档中写入章节标题 f.write(chap_title + '\n') #6.3 下载章节的内容 chap_response = requests.get(chap_url) chap_response.encoding='gbk' chap_html=chap_response.text #6.4 解析小说内容 chap_soup =be(chap_html,'lxml') chap_text=''.join(chap_soup.find(attrs={'id':'content'}).strings) #6.5 清洗数据 chap_text = chap_text.replace(' ','') chap_text = chap_text.replace('<br />','') chap_text = chap_text.replace('\r\n','') chap_text = chap_text.replace('style5();','') #6.6 写入文档 f.write(chap_text + '\n') print(chap_title,chap_url)
MAX. 小说爬取案例3:
利用xpath爬取一篇小说
#爬取一篇小说 #导入相应库 import requests import re from lxml import etree #小说主页的url 地址 novel_url='http://www.quanshuwang.com/book/0/437' #1. 下载小说的信息 response = requests.get(novel_url) #2. 设置html编码 response.encoding='gbk' novel_html=response.text #3. 利用XPath解析网页 page = etree.HTML(novel_html) #4. 解析小说的名称 chapter_title = page.xpath('//a[@class="article_title"]/text()')[0] #4. 解析章节标签 chapter_tag_a = page.xpath('//div[@class="chapterNum"]//li/a') #5. 构造章节信息 chapter_info = [] for tag_a in chapter_tag_a: chapter_info.append((tag_a.xpath('@href')[0],tag_a.xpath('text()')[0])) #6. 下载每一章的内容,存为一个txt文档 with open(r'C:\Users\luowe\Desktop\%s.txt'%chapter_title , 'w' , encoding='utf-8') as f: #6.1 循环下载每一章节内容,写入text文档中 for chapter_url ,chapter_title in chapter_info: #6.2 在文档中写入标题,并换行 f.write(chapter_title+'\n') #6.3 下载章节的详细内容 response = requests.get(chapter_url) response.encoding='gbk' #设置编码,防止乱码 novel_html = response.text #6.4 解析小说内容 chapter_page = etree.HTML(novel_html) novel_content = chapter_page.xpath('string(//div[@id="content"])') #6.5 清洗数据 novel_content = novel_content.replace(' ',' ') #去空格 novel_content = novel_content.replace('<br />',' ') #去标签 novel_content = novel_content.replace('\r\n','') #去空去换行 #6.6 写入文档,每写入一章,换一行 f.write( novel_content + '\n') print(chapter_title, chapter_url)