python爬虫
python爬虫使用的基本库之一:requests
首先,需要安装:pip install requests
安装之后就可以使用了
我们大多数情况下会使用requests.get(),或者requests.post(),来获得我们所需要的网页内容。
requests.get()是通过get请求来获得网页,requests.post()是通过post请求来获得网页内容的,需要传额外的参数哦!具体视你所需要的爬去的网页来确定。
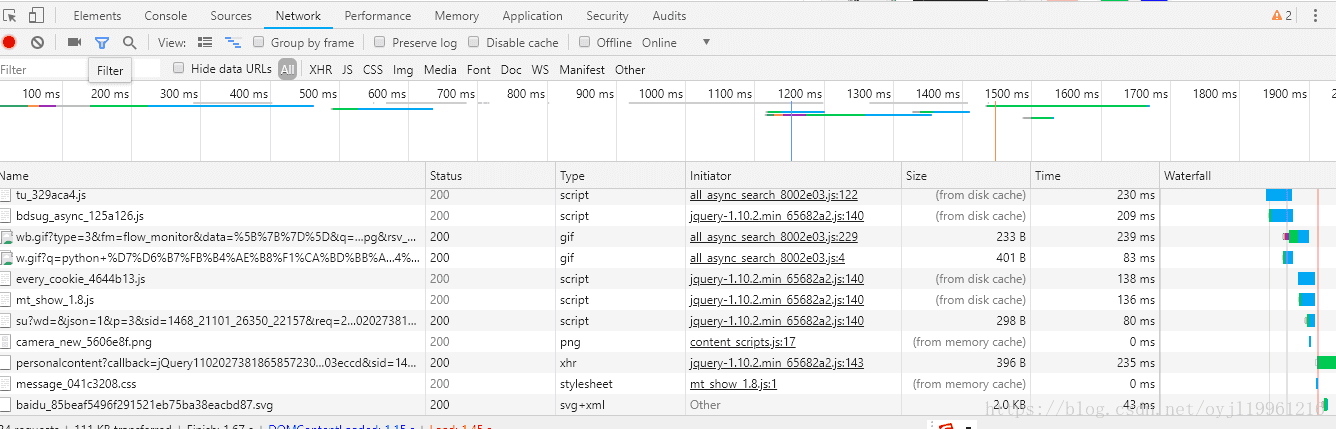
此外,许多网页都有反爬虫机制,今天我们使用最简单的方法来规避一些反爬虫——就是设定User-Agent,这个可以通过浏览器来获得,打开一个网页,右键单击,点击检查元素,然后刷新网页,在network一栏中随意选择一条信息,如下图:
右边会出现一些信息,选择headers,在里面寻找User-Agent,复制粘贴到程序中即可,在请求时传入,下面是一个下载百度贴吧的小爬虫
import requests
class TiebaSpider:
def __init__(self,tieba_name_crawl):
"""
完成初始化
:param tieba_name_crawl:
"""
self.tieba_name = tieba_name_crawl
self.url_base = "http://tieba.baidu.com/f?kw=" + tieba_name_crawl + "&ie=utf-8&pn={}"
self.headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.62 Safari/537.36"}
def make_url_lists(self):
"""
生成下载列表
:return: 下载列表
"""
return [self.url_base.format(i) for i in range(1,5)]
def download_url(self,url_str):
"""
使用requests get 方法下载指定页面,并返回页面结果
:param url_str: 下载链接
:return: 下载结果
"""
result = requests.get(url_str,headers=self.headers)
return result
def save_result(self,result,page_num):
"""
存储下载的内容
:param result: 下载链接
:param page_num: 对应的页码
:return:
"""
with open('tieba{}.html'.format(page_num), 'wb') as f:
f.write(result.content)
return 'ok'
if __name__ == '__main__':
tieba = TiebaSpider('lol')
url_strs = tieba.make_url_lists()
for i in range(4):
result = tieba.download_url(url_str=url_strs[i])
page_num = i+1
tieba.save_result(result,page_num= page_num)