1、网络爬虫(Web Spider)概述
又称网络蜘蛛、网络机器人,是一种按照一定的规则,自动动抓取万维网信息的程序或者脚本。
类型分类:
通用网络爬虫:尽可能原网络覆盖率,如搜索引擎(百度、雅虎和谷歌等。。。)
聚集网络爬虫:有目标性,选择性地访问万维网来爬取信息。
增量式网络爬虫:只爬取新产生的或者已经更新的页面信息。特点:耗费少,难度大
深层网络爬虫:通过提交一些关键字才能获取的Web页面,如登录或注册后访问的页面
2、应用场景
有科学研究、Web安全、产品研发、监控等领域可以做很多事情。如在数据挖掘、机器学习、图像处理等科学研究领域,如果没有数据,则可以通过爬虫从网上抓取;在Web安全方面,使用爬虫可以对网站是否存在某一漏洞进行批量验证、利用;在产品研发方面,可以采集各个商城物品价格,为用户提供商场最低价;监控方面,可以抓取、分析新浪微博的数据,从而识别邮某用户是否为水军。
3、学习爬虫前的技术准备
A、Python基础语言:基础语法、运算符、数据类型、流程控制、函数、对象模块、文件操作、多线程、网络编程
B、W3C标准:HTML、CSS、JavaScript、Xpath、JSON
C、HTTP标准:HTTP的请求过程、请求方式、状态码含义、头部信息以及Cookie状态管理
D、数据库:SQLite、MySQL、MongoDB、
4、网络爬虫的执行过程
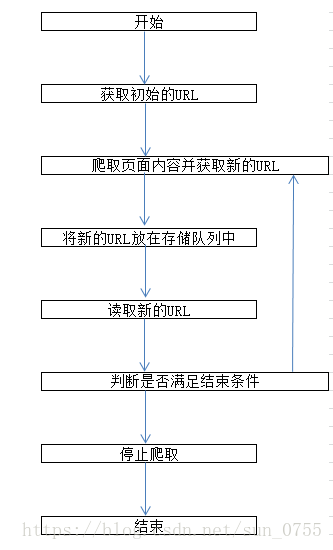
5.网络爬虫使用的技术
爬取库:urllib2(urllib3)、requests、mechanize、selenium、splinter;
urllib2(urllib3)、requests、mechanize用来获取URL对应的原始响应内容;而selenium、splinter通过加载浏览器驱动,获取浏览器渲染之后的响应内容,模拟程度更高。
数据解析库:lxml、beautifulsoup4、re、pyquery。
数据解析常用方法:xpath路径表达式、CSS选择器、正则表达式等。其中xpath路径表达式、CSS选择器主要用于提取结构化的数据,而正则表达式主要用于提取非结构化的数据。
6、常见反爬虫手段
A、基本的反爬虫手段,主要是检测请求头中的字段,比如:User-Agent、referer等。针对这种情况,只要在请求中带上对应的字段即可。所构造http请求的各个字段最好跟在浏览器中发送的完全一样,但也不是必须。
B、基于用户行为的反爬虫手段,主要是在后台对访问的IP(或User-Agent)进行统计,当超过某一设定的阈值,给予封锁。针对这种情况,可通过使用代理服务器解决,每隔几次请求,切换一下所用代理的IP地址(或通过用不用User-Agent列表解决,每次从列表里随机选择一个使用)。这样的反爬虫方法可能会误伤用户。
C、希望抓取的数据是如果通过ajax请求得到的,假如通过网络分析能够找到该ajax请求,也能分析出请求所需的具体参数,则直接模拟相应的http请求,即可从响应中得到对应的数据。这种情况,跟普通的请求没有什么区别。
D、基于java的反爬虫手段,主要是在响应数据页面之前,先返回一段带有java代码的页面,用于验证访问者有无java的执行环境,又确定使用的是不是浏览器。