1.爬虫
最大的爬虫网站就是百度
1.浏览网站时经历的过程
浏览器(请求request)->输入URL地址(http://www.baidu.com/index.html file:///mnt ftp://172.25.254.31/pub
->http协议确定,www.baidu.com访问的域名确定 ->DNS服务器解析到IP地址
->确定要访问的网页内容 -> 将获取到的页面内容返回给浏览器(响应过程) )
2.爬取网页
基本方法
这里的timeout,意为访问超过0.02秒则报错

下面是正常爬取
获得的是百度页面的HTML信息


使用Request对象 (可以添加其他的头部信息)
有必要说明,re的存在是实例化request对象,可以自定义请求的头部信息;
urlopen 不仅可以传递url地址,也可以传递request对象;

这是对应网站的HTML信息
因为百度没有反爬虫策略,其他网站有,所以我们才伪装浏览器

反爬虫策略
模拟浏览器
Android
first: Mozilla/5.0 (Linux; Android 4.1.1; Nexus 7 Build/JRO03D) AppleWebKit/535.19 (KHTML, like Gecko) Chrome/18.0.1025.166 Safari/535.19
second: Mozilla/5.0 (Linux; U; Android 4.0.4; en-gb; GT-I9300 Build/IMM76D) AppleWebKit/534.30 (KHTML, like Gecko) Version/4.0 Mobile Safari/534.30
third:Mozilla/5.0 (Linux; U; Android 2.2; en-gb; GT-P1000 Build/FROYO) AppleWebKit/533.1 (KHTML, like Gecko) Version/4.0 Mobile Safari/533.1
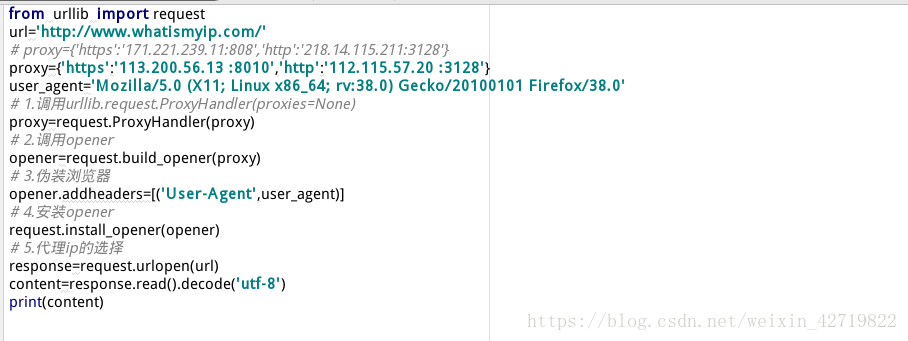
IP代理
当抓取网站时,程序的运行速度很快,如果通过爬虫去访问,一个固定的IP访问频率很高,网站如果做反爬虫策略,那么就会封掉ip;
如何解决?
——设置延迟:time.sleep( random.randint (1,5)
____使用IP代理,让其他IP代替你的IP访问
如何获取代理ip?
http://www.xicidaili.com
如何实现步骤?
1).调用 urllib.request.ProxyHandler (proxies=None); --类似理解为Request对象
2).调用Opener- - -类似于urlopen,这个是定制的
3).安装Opener
4) . 代理ip的选择
最终获得对应的网站的HTML内容
2.保存cookie信息
#cookie信息是什么?
cookie,某些网站为了辨别用户身份,只有登陆之后才能访问某个页面;
进行一个会话跟踪,将用户的相关信息包括用户名等保存到本地终端
实现步骤:
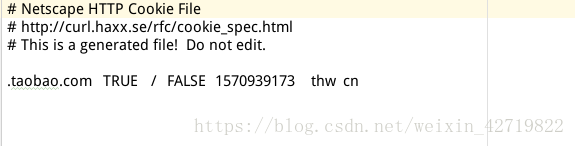
这是将cookie保存在文件中,文件名为cookie.txt
文件内容如下
读取该文件的HTML信息则添加如下,就会获得淘宝的HTML信息






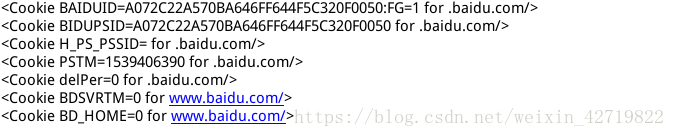
这是将cookie保存在变量中
3.urllib常见的异常处理
异常:
--------exception urllib.error.URLError
通常引起URLError的原因是:无网络连接,访问的目标服务器不存在。在这种情况下会有一个reason属性,是一个错误码,错误原因的元组。
--------exception urllib.error.HTTPError
每一个从服务器返回的HTTP响应都有一个状态码。其中,有的状态吗表示服务器不能完成相应的请求,默认的处理程序可以为我们处理一些这样的状态码(如返回是重定向,urllib2会自动为我们从重定向后的页面中获取信息)。有些状态码,urllib2模块不能帮我们处理,那么urlopen函数就会引起HTTPError异常,其中典型的就有404/401
常见的状态返回码
100-102:消息类型,这一类型的状态码,代表请求已被接受,需要继续处理。这类响应是临时响应,只包含状态行和某些可选的响应头信息,并以空行结束。
200-207:成功类型,这一类型的状态码,代表请求已成功被服务器接收、理解、并接受。其中200代表请求已成功,请求所希望的响应头或数据体将随此响应返回。出现此状态码是表示正常状态。
300-307:重定向类型,定向这类状态码代表需要客户端采取进一步的操作才能完成请求。通常,这些状态码用来重定向,后续的请求地址(重定向目标)在本次响应的 Location 域中指明。当且仅当后续的请求所使用的方法是 GET 或者 HEAD 时,用户浏览器才可以在没有用户介入的情况下自动提交所需要的后续请求。客户端应当自动监测无限循环重定向(例如:A->A,或者A->B->C->A),因为这会导致服务器和客户端大量不必要的资源消耗。按照 HTTP/1.0 版规范的建议,浏览器不应自动访问超过5次的重定向。
400-451:请求错误类型,这类的状态码代表了客户端看起来可能发生了错误,妨碍了服务器的处理。除非响应的是一个 HEAD 请求,否则服务器就应该返回一个解释当前错误状况的实体,以及这是临时的还是永久性的状况。这些状态码适用于任何请求方法。浏览器应当向用户显示任何包含在此类错误响应中的实体内容。如果错误发生时客户端正在传送数据,那么使用TCP的服务器实现应当仔细确保在关闭客户端与服务器之间的连接之前,客户端已经收到了包含错误信息的数据包。如果客户端在收到错误信息后继续向服务器发送数据,服务器的TCP栈将向客户端发送一个重置数据包,以清除该客户端所有还未识别的输入缓冲,以免这些数据被服务器上的应用程序读取并干扰后者。
first
这里我关闭了网络,所以显示连接被拒绝;属于HTTP错误
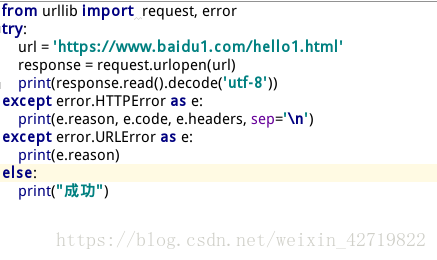
second
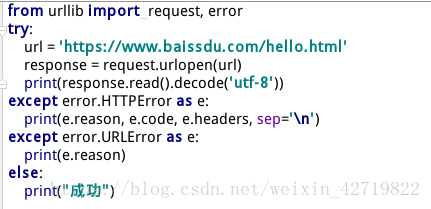
这里我访问了不存在的url地址,所以报错属于URL错误
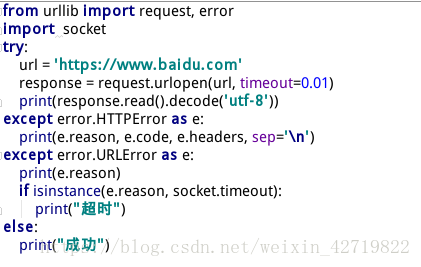
third
这里因为我设置了连接时间,超过了0.01秒就会报错,所以属于超时异常
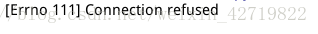


4.url解析
1.url.parse.urlparse( urlstring,scheme=’ ',allow_fragments=True)
功能:将url分为6部分,返回一个元组;
协议,服务器的地址(IP:port),文件路径,访问的页面

解析:获取使用协议和访问的ip;
通过字典编码的方式构造url地址;

5.requests模块
requests是一个http请求库,他是基于urllib3来编写的,他比urllib更加方便。
#实例引入
由图中结果我们可以看出,
status_code是返回状态码
cookies返回的是缓存对象
text则是HTML页面内容
而内容的类型是字符串


#带参数的get请求
#获取二进制数据

因为图片是二进制文件,我们用text只能获得乱码,显示图片要用content方法
这里request.text返回的是字符串的页面信息
request.content返回bytes的页面信息
这里的url1是审查元素后出现的图片地址
获得图片 ‘sss.png’ 内容如下
#高级设置
**上传文件
requests来提交Form表单,一般存在于网络的登陆,用来提交用户名和密码
而此时提交到了httpbin.org网站,在此网站可以显示提交请求的内容




#忽略证书验证
有点网站证书不合法无法访问,如下操作可以忽略证书,正常访问

#获取cookie信息


#解析json格式
json格式,借助访问淘宝网,查询输入ip所在地

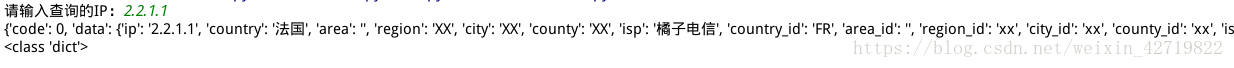
#读取已经存在的cookie信息访问网址内容(会话维持)

可以和前面cookie缓存一起用,就可以读取缓存了

#代理设置/设置超时间

