网络爬虫学习,仅作笔记
一 . 认识爬虫
1.1 概念
网络爬虫是一个程序,能够自动,批量,下载,保存网络资源。
网络爬虫是伪装成客户端与服务端运行数据交互的程序。
1.2相关概念
1.2.1 网络应用架构
- c / s client / server 客户端/服务端
- b / s browser 浏览器
- m / s mobile 移动端
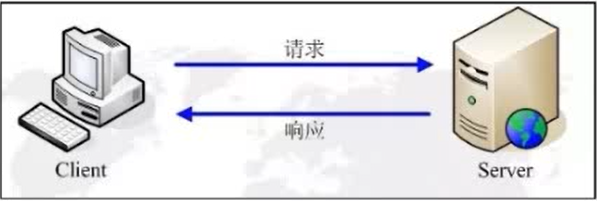
#*Client发送数据请求给Server,Server接收请求并处理返回一个包含结果的响应体给Client*#
1.2.2 http协议
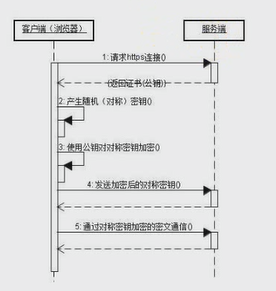
1.http协议又称为超文本传输协议.(从服务器传输数据到客户端,客户端是没有数据的,都是从服务器下载过来的)
2.http完整事务流程:
1.浏览器输入请求网址url,dns(域名解析成唯一的IP地址,找到服务器)
2.底层协议(TCP/IP连接),三次握手。
3.客户端发送HTTP请求报文。
4.服务端收到并处理请求,返回一个包含结果的响应。
5.浏览器对响应结果进行渲染和展示。
#了解http#
-http为无连接,每次只处理一个请求
-http媒体独立.(按'约定'即可传输任意类型数据)
-http无状态(静态页面,无Cookie,session,无记录)
1.2.3 请求(request)
完整报文(四部分):请求行 , 请求头 , 空行 , 请求数据/请求体


#请求方法-http协议及版本-空格换行-Host(主机):-www.??.com(域名和端口,端口已隐藏)-空格换行空格换行# Get请求不要数据
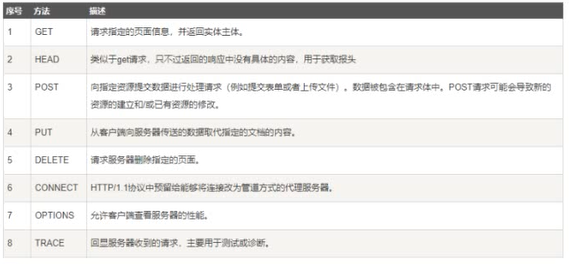
1. 请求方法
1.0版本 - get post head
1.1版本 - 如图
2. 请求头
'名称 + : + 空格 + 值 '

3. 请求体
数据为二进制,GET没有
4. 响应
状态行 , 消息报头 , 空行 , 响应正文
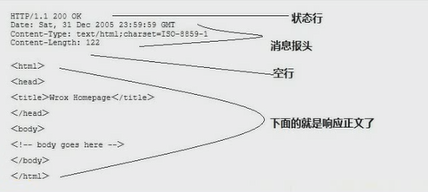
5. 响应状态码(5种类型,3位整数)

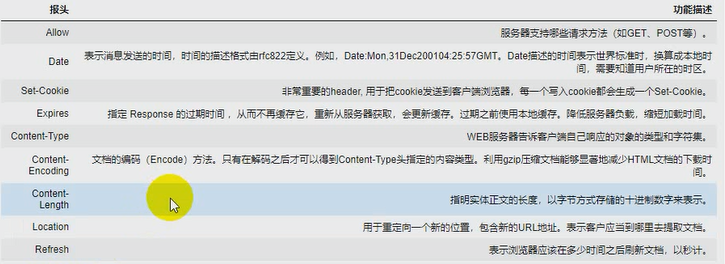
6. 响应报头
1.2.4 会话技术
cookie , session
cookie:凭证,将信息存于客户端,不安全
session:会话,基于Cookie,将信息存于服务端
#Session#
在Requests中,实现了Session(会话)功能,当我们使用Session时,能够像浏览器一样,在没有关闭浏览器时,能够保持访问状态.常用于登录之后的数据获取.
import requests session =requests.Session() session.get('http://httbin.org/cookies/set/sessioncookie/123456789') resp = session.get('http://httbin.org/cookies') print(resp.text) #设置整个headers---如果在get()方法中传入headers和cookies等数据,只有1次有效,想要整个生命周期有效,需要以下方法设置 session.headers = { 'user-agent':'my-app/0.0.1' } #增加一条headers session.headers.updatedate({'x-test':'true'})
1.2.5 网络资源
网络资源:只有通过互联网访问到的资源就叫网络资源。
1.2.6 URL
统一资源定位符,网址,唯一标识

1.2.7 https
http缺陷:发送传输数据是明文,在隐私数据方面不安全.
依托于http,ssl?TCL 协议
- ca证书
- 加密
- 标准端口:80(http) 443(https)
- ↓(密钥每次都会重新生成,无法破解)
1.3 应用领域
1.3.1 数据采集
到网络上爬取资源,双方数据交互,上网时查看互联网数据,互联网同时采集自己的信息数据.
1.3.2 搜索引擎
所有搜索引擎都是爬虫,不分日夜到互联网爬取网页头存在自己的资源里.
1.3.3 模拟操作
对于重复的操作,例如贴吧的灌水,水军,可以使用爬虫实现.
过年火车一票难求,可以实现抢票功能,让这个程序一直帮我抢票.360抢票就是爬虫实现的
二 . 开发流程
1. 分析请求流程
目的:找到目标资源的http请求。具体指标:
1. 请求方法
2. url
3. 请求头
4. 请求数据(参数)
#*工具(抓包)
fiddler,安装复杂,使用也比较复杂.对于google抓不到的,可以使用fiddler解决.
谷歌浏览器,按F12开启调试者模式(Ctrl+Shift+I)
2. 发送请求
2.1 通过soket 发送HTTP请求
from socket import socket #创建一个客户单端 client = socket() #连接服务器 client.connect(('www.baidu.com',80)) #构造http请求报文 data =b'GET / HTTP/1.0\r\nHost: www.baidu.com\r\n\r\n' #发送报文 client.send(data) #接收响应 res = b'' temp = client.recv(1024)#接收数据每次1024字节 print('*'*20) while temp: res += temp temp = client.recv(1024) print(res)#请求演示 client.close()
2.2 工具库
1. urllib python标准库,(专用于)网络请求的
2. urllib3 基于python3,牛人开发
3. requests 简单易用,牛逼
2.3 requests
简单介绍:转为人类而构建,优雅和简单的python库,也是有史以来下载次数软件python包之一,下载次数每天超过40w/次
import requests #非常简单明了,易用 resp = requests.get('https://baidu.com') #网页状态码 resp.status_code #按字典取得值 resp.headers['content-type'] #获取字符编码类型 resp.encoding #获取文本 resp.text
Requests目前基本上完全满足web请求的所有需求,以下是Requests的特性:
1. Keep-Alive & 连接池
2. 国际化域名和URL
3. 带持久Cookie的会话
4. 浏览器式的SSL认证
5. 自动内容解码
6. 基本/摘要式的身份认证
7. 优雅的key/value Cookie
8. 自动解压
9. Unicode响应体
10. HTTP(S)代理支持
11. 文件分块上传
12. 流下载
13. 连接超时
14. 分块请求
15. 支持 .netrc
Requests的安装:pip install requests ##(pip list 可查看已安装库)##
#Requests发起请求--请求方法 import requests resp = requests.get('https://baidu.com') #Post请求 resp = requests.post('http://httpbin.org/post',data={'key':'value'}) #其他请求类型 resp = requests.put('http://httpbin.org/put',data={'key':'value'}) resp = requests.delete('http://httpbin.org/delete') resp = requests.head('http://httpbin.org/get') resp = requests.options('http://httpbin.org/get') #传递URL参数 import requests params = {'key1':'value1','key2':'value2'} resp =requests.get('http://httpbin.org/get',params=params) #自定义Headers url = 'https://api.github.com/some/endpoint' headers = {'user-agent':'my-app/0.0.1'} resp = requests.get(url,headers=headers) #自定义Cookies url='http://httpbin.org/cookies' cookies={'cookies_are':'working'} resp = requests.get(url,cookies=cookies) resp.text #设置代理 proxies={ 'http':'http://10.10.1.10:3128', 'https':'http://10.10.1.10:1080' } requests.get('http://example.org',proxies=proxies) #重定向 resp = requests.get('http://github.com',allow_redirects=False) resp.status_code #禁止证书验证,默认sure resp = requests.get('http://httpbin.org/post',verify=False) #设置禁用证书出现的warning关闭方法 from requests.packages.urllib3.exceptions import InsecureRequestWarning #禁用安全请求警告 requests.packages.urllib3.disable_warnings(InsecureRequestWarning) #设置超时 requests.get('http://github.com',timeout=0.001) #响应内容 resp.text #状态码 resp.status_code #响应报头 resp.headers #服务器返回的cookies resp.cookies #url resp.url
3. 获取响应内容
利用socket下载一张图片,较麻烦,基础
#通过socket 下载一张图片 from socket import socket #创建客户端 client = socket() img_url = 'http://pic22.nipic.com/20120725/9676681_001949824394_2.jpg' #连接服务器 client.connect(('pic22.nipic.com',80)) #构建请求报文 data = b'GET /20120725/9676681_001949824394_2.jpg HTTP/1.0\r\nHost: pic22.nipic.com\r\n\r\n' #发送请求 client.send(data) #接收响应 res= b'' temp =client.recv(1024) while temp: res += temp temp =client.recv(1024) headers,img_data=res.split(b'\r\n\r\n')#自动分割字符串 #保存图片 with open(r'C:\Users\luowe\Desktop\test.jpg','wb') as f: f.write(img_data) print('完成')
利用requests下载一张图片,简单粗暴
#通过requests 下载一张图片 import requests
img_url = 'http://pic22.nipic.com/20120725/9676681_001949824394_2.jpg' #接收响应 response = requests.get(img_url) #保存图片 with open(r'C:\Users\luowe\Desktop\test.jpg','wb') as f: f.write(response.content) print('完成')
4. 解析内容
响应体:文本(text) , 二进制数据(content)
文本:html , json , (js , css)
1. html解析
2. 正则表达式
3. beautiful soup
4. xpath
#json解析--jsonpath#
5. 数据持久化
1. 写文件
2. 写数据库
三 . 重点 , 难点
1.1 数据获取(难点)
1. 请求头反爬(UA,用户代理)
2. cookie(set-cookie,较麻烦,requests直接完爆它)
3. 验证码(点触,加减,扭曲,文字,滑动,语音等)
4. 行为检测(用户点击频率,停留时间通过时间和行为来判断视为爬虫.)
5. 参数加密(MD5加密和其他加密方式)
6. 字体反爬(服务端用自己的字体对某些数据加密,解密有些困难)
1.2 爬取效率
1. 并发--多线程,多进程同时爬取
2. 异步--?
3. 分布式--爬虫会监测IP,如果同一个IP访问次数过多,服务端就会考虑封IP,爬虫分布在不同的电脑上一起爬取.
四 . 正则表达式
1.1 概念
正则表达式是对字符串操作的一种逻辑公式,就是用事先定义好的一些特定字符·及这些特定字符的组合,组成一个"规则字符串",这个'规则字符串
'用来表达对字符串的一种过滤逻辑.
1.2 特点
1. 灵活性,逻辑性和功能性非常强;
2. 可以迅速地用极简单的方式达到字符串的赋值控制;
3. 对于刚接触的人来说,比较晦涩难懂.
1.3 符号
1.普通字符(区分大小写) --->例如'testing' 能匹配testing.testing123,不能匹配Testing
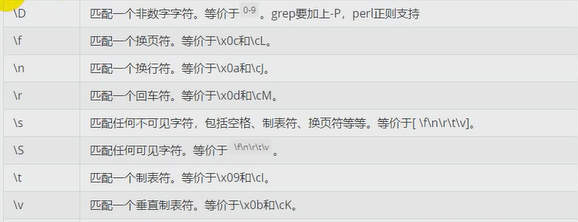
2.元字符 --->. ^ $ * + ? { } [ ] | ( ) \




1.4 Python中常用的正则表达式处理函数
re模块使Python 语言拥有全部的正则表达式功能
1. re.match 函数
re.match 尝试从字符串的起始位置匹配一个模式,如果不是起始位置匹配成功, match() 就返回none.
函数语法:
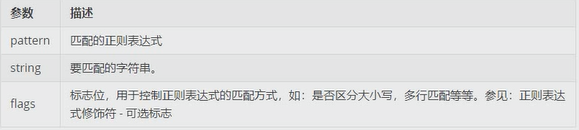
re.match(pattern , string , flags=0)

2. re.search() 方法
re.search 扫描整个字符串并返回第一个成功的匹配
函数语法:
re.search(pattern , string , flags = 0)


3. re.match 与 re.search 的区别
re.match 只匹配字符串的开始,如果字符串开始不符合正则表达式,则匹配失败,函数返回None; 而re.search 匹配整个字符串,直到找到第一个匹配.
4. 检索和替换
Python的re 模块提供了re.sub 用于替换字符串中的匹配项.
语法:
re.sub(pattern , repl , string , count=0 , flags=0)

5. re.findall 函数
在字符串中找到正则表达式所匹配的所有子串,并返回一个列表,如果没有找到匹配的,则返回空列表.
# match 和 search是只匹配一次,, findall匹配所有
语法:
re.findall(pattern , string , flags=0)

6. re.compile 函数
compile 函数用于编译正则表达式, 生成一个正则表达式( Pattern )对象, 供match() 和 search() 这两个函数使用.
语法:
re.compile(pattern[ , flags])

7. 正则表达式修饰符 - 可选标志
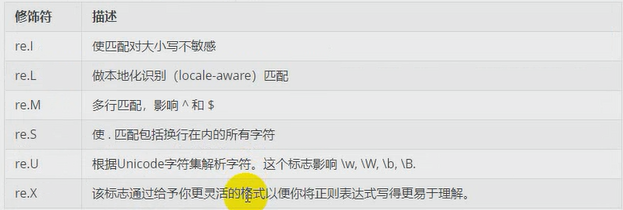
正则表达式可以包含一些可选标志修饰符来控制匹配的模式.修饰符被指定为一个可选的标志.多个标志可以通过安位 OR( | ) 它们来指定. 如re.I | re.M 被设置成I 和 M标志.
五 . 总结

六 . 使用requests抓取30张图片
import re import requests page_url='http://image.baidu.com/search/index?tn=baiduimage&ipn=r&ct=201326592&cl=2&lm=-1&st=-1&fm=result&fr=&sf=1&fmq=1571210386205_R&pv=&ic=&nc=1&z=&hd=&latest=©right=&se=1&showtab=0&fb=0&width=&height=&face=0&istype=2&ie=utf-8&sid=&word=妹子&f=3&oq=meiz&rsp=0' #下载页面的html response = requests.get(page_url) html = response.text #解析出图片的url res = re.findall(r'"thumbURL":"(.*?)"',html) #下载图片 #伪装成浏览器 headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36' ,'Referer':'image.baidu.com'} for index,url in enumerate(res): response = requests.get(url,headers=headers) #写图片 with open(r'C:\Users\luowe\Desktop\爬图\%s.jpg'%index , 'wb') as f: f.write(response.content) print(url)