5.1 数据的抽取要正确反映业务需求
1) 使用控制变量确保数据真实反映业务。
2) 注意时效性,确保抽取的数据所对应的当时业务场景,与现在的业务需求即将应用的业务场景没有明显重大的改变。
5.2 数据抽样
当总数据量过大,针对数据全集分析运算会耗费较多运算资源时,就要采取抽样措施;或者,在很多小概率、稀有事件的建模预测过程中,需要人为增加样本中“稀有事件”的浓度和在样本中的占比,比如占0.2%的信用卡用户恶意欺诈事件。
在抽样过程中需要注意:
1)样本变量的分布要与数据全集变量的分布保持一致。
2)样本中缺失值的分布(频率)要与数据全集中缺失值分布保持一致。
3)针对稀有事件抽样,样本中事件与非事件的比例被人为放大了,此时要使用加权的方法恢复新样本对全体数据集的代表性。
5.3 分析数据的规模要求
分析数据的规模,重点是考察目标变量所对应的目标事件的数量,比如实际的欺诈案例的数量(而不是样本中所有事件的数量)。一般情况下,会将样本划分为3个子样本集,训练集(Training set)、验证集(Validation set)、测试集(Testing set),有时也只划分为两个子集,即训练集和验证集。训练集的数据量大概应占到样本总数据量的40%-70%。在理想情况下,训练集的目标事件的数量应该有1000个以上,如果实际数量少于1000个,则更需要关注模型的稳定性检验。
另外,预测模型的自变量一般控制在8-20个之间。训练集的样本规模一般在自变量数量的10倍以上,并且被预测的目标事件至少是自变量数目的6-8倍。
5.4 处理缺失值和异常值
5.4.1 缺失值的常见处理方法:
1)根据数据缺失原因进行不同处理:
缺失是否具有实际意义、本身缺省、计算错误。
2)直接删除带有缺失值的数据元组:
但这容易造成数据量变小、丢失重要信息、无法对含缺失值的数据进行预测,因此此方法只适用于建模样本里缺失值比例很少,并且后期预测应用中的数据缺失值比例也少的情况。
3)直接删除有大量缺失值的变量:
比如说缺失值超过20%的变量,但需要考虑这种大规模的缺失是否有另外的商业背景含义。
4)对缺失值进行替换:
对类别型变量而言,用众数或者一个崭新的类别属性来代替缺失值;对次序性变量和区间型变量,用中间值、众数、最大最小值、平均值、用户定义的任意其他值代替。但是这种替换不能完全代表缺失值本身真实的含义,属于“不得已而为之”的策略。
5) 对缺失值进行赋值:
这种方法将通过回归模型、决策树、贝叶斯定理等去预测缺失值的最近替代值,也就是将缺失值对应的变量当作目标变量,把其他的输入变量当作自变量,为每个需要进行缺失值赋值的字段分别建立预测模型。从理论上看,这种方法最严谨,但是成本较高。
5.4.2 异常值的判断和处理
异常值通常是指一个类别型变量里某个类别值出现的次数太少,比如出现的频率只占0.1%,或者一个区间变量里某些值取值太大。如果不清理异常值,对挖掘模型的负面效果是非常大的。
对异常值的判断内容如下:
1)对于类别型变量:
若某个类别值的分布占比不到0.1%,就认为是异常值。但有些情况下,纵然某个类别值占比很少,但是如果跟目标变量里的目标事件有显著的正相关关系,那这类类别值的价值就不是简单的异常值可以代表的。
2) 对于区间型变量:
最简单的方法就是把变量取值排序,两端0.1%的甚至更多的观察值,很可能就属于异常值。或者用标准差作为衡量得尺度(比如超过正负4个标准差的数据)。
处理异常值主要的措施就是删除。
需要注意的是,对于“异常值”的处理是辩证的,多数情况下,删除异常值可以有效降低数据波动,提高模型稳定性。但是,在某些业务场景下,异常值的应用却是另一个专门的业务方向,比如之前提到的信用卡恶意欺诈事件。
5.5 数据转换
数据转换可分为以下四大类:
1)产生衍生变量:
这类衍生变量通常更具有商业意义,比如说平均值、比例等。
2)改善变量分布:
当区间型变量的原始分布严重不对称或者不光滑时,要通过各种数学转化,使自变量分布呈现正态分布,那么模型的拟合效果和预测性能会有较大提升。包括使用取对数、开平方根、取倒数、取指数等方法。
3)分箱转换:
就是将区间型变量转换为次序性变量。适用于当自变量的区间较复杂、自变量与因变量之间有明显非线性关系、自变量偏度很大时,这样可以降低自变量的复杂性,提高自变量的预测能力。
4)数据标准化:
主要目的是将数据按比例缩放,使得不同的变量经过标准化后可以有平等的分析和比较基础,比如离差标准化。缺点在于有些非线性转化如log转化、平方根、多次方转化的含义无法用清晰的商业逻辑解释,但是瑕不掩瑜。
5.6 筛选有效的输入变量
5.6.1 删除无价值变量
1)常数变量
2)缺失值比例较高变量(高达95%)
3)取值太泛的类别型变量(比如邮政编码)
5.6.2 用相关指标或方法初步筛选
最核心的方法是结合业务经验先行筛选,然后才是按照这些普遍的方法筛选:
1)皮尔逊相关系数:
如果自变量的r>0.6,则只需保留一个自变量就可以。
2)R平方:
检查R平方或者F值的显著性,或者用逐步回归方法筛选变量。
3)卡方检验:
最常见的是考察二元目标变量与类别型自变量的关联程度,关联性大的自变量就有可能是重要的自变量。
4) IV和WOE:
当目标变量是二元变量,自变量是区间型变量时,可以通过IV(Information Value)和WOE(Weight of Evidence)进行自变量的判断和取舍。需要把区间型自变量转换为类别型自变量(比如分箱处理),同时要强调目标变量必须是二元变量。
具体计算公式如下:
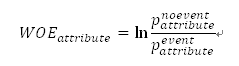
其中,
在上述公式中, 和
和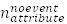 分别代表在该属性值(区间变量转化为类别变量后的类别属性值)里,样本数据所包含的预测事件和非事件的数量,
分别代表在该属性值(区间变量转化为类别变量后的类别属性值)里,样本数据所包含的预测事件和非事件的数量, 和
和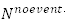
分别代表在全体样本数据里所包含的预测事件和非事件的总量。
而一个变量的总的预测能力是通过IV来表现的,它是该变量的各个属性的WOE的加权总和,IV代表了该变量区分目标变量中的事件与非事件的能力,具体计算公式如下:
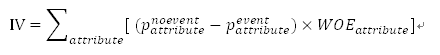
与IV有相似作用的一个变量是Gini分数,Gini分数的计算步骤如下:
i. 根据该字段里每个属性所包含的预测事件(event)和非事件(noevent)的比例,按照各属性的比例的降序进行排列。
ii. 针对排列后的每个组,分别计算该组内的事件数量 和非事件数量
iii. 计算Gini指数: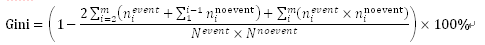
总体来说,在应用IV、WOE、Gini Score3个指标时,可以在数据挖掘中实现以下目标:
i. 通过WOE的变化来调整出最佳的分箱阈值。通常是先把一个区间型变量分成10-20个临时区间,分别计算各自的WOE值,根据WOE在各区间的变化趋势,做相应的合并。
ii. 通过IV或者Gini分数,筛选出有较高预测价值的自变量。
8.6.4 部分建模算法自身的筛选功能
包括决策树模型、回归(含线性回归和逻辑回归)。但是在使用之前先进行人为初步筛选,然后把精简后的变量交给算法去选择。
8.6.5 降维的方法
包括主成分分析和变量聚类等。
8.7 共线性问题
8.7.1识别共线性
1)相关系数
2)通过模型结论的观察,比如回归系数的标准差过大
3)主成分分析,比如第一主成分中某几个原始变量的主成分载荷系数较大且数值相近
4)根据业务经验判断,比如原本没有预测作用的变量突然变得有很强的统计性
5)对变量聚类
8.7.2 处理共线性
1)对相关变量进行取舍
2)对相关变量组合,生产一个新的综合性变量
3)尝试对相关变量进行形式上的转换,比如改变分布