4.1 如何有效地优化模型
4.1.1 从业务思路上优化
1) 有没有更加明显且直观的规则、指标可以代替复杂的建模?
2) 有没有一些明显的业务逻辑(业务假设)在前期的建模阶段被疏忽了呢?
3) 通过前期的初步建模和数据熟悉,是否有新的发现,甚至能颠覆之前的业务推测(直觉)?
4) 目标变量的定义是否稳定(在不同时间点抽样验证)?
4.1.2从建模的技术思路上优化
1) 不同建模算法比较
2) 不同的抽样方法比较
3) 有没有必要通个关细分群体来分别建模
4.2 模型效果评价的主要指标体系
本节将重点介绍目标变量是二元变量的分类(预测)模型的评价指标
4.2.1 评价模型准确多和精度的系列指标
先明确以下四个基本定义:
| 预测的类别 |
|||
| 1 |
0 |
||
| 实际的类别 |
1 |
TP |
FN |
| 0 |
FP |
TN |
|
由此延伸出下列评价指标
1) 正确率: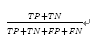
2) 错误率:
3) 灵敏性:
4) 特效性:
5) 精度: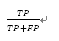
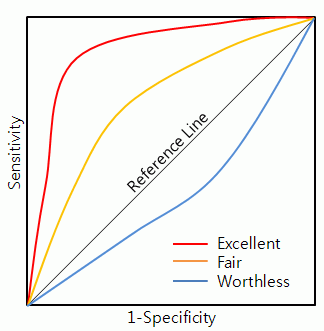
4.2.2 ROC曲线
ROC曲线是一种有效比较两个二元分类模型的可视工具,它显示了给定模型的灵敏性真正率和假正率之间的比较评定。真正率的增加是以假正率的增加为代价的,ROC曲线下面的面积就是比较模型准确度的指标和依据,面积大的模型对应的模型准确度要高,也就是要择优应用的模型,面积越接近0.5,对应的模型的准确率就越低。
要绘制ROC曲线,首先要对模型所做的判断即对于的数据做排序,把经过模型判断后的观察值预测为正(1)的概率从高到低进行排序,ROC曲线的纵轴表示真正率,ROC曲线的横轴表示假正率。具体绘制时,从左下角开始,此时真正率和假正率都为0,按照刚才概率从高到低的顺序,依次针对每个观察值实际的“正”或“负”绘制,如果它是真正的“正”(预测正确),则ROC曲线向上移动并绘制一个点;如果它是真正的“负”,则ROC曲线向右移动一个点。
4.2.3 KS值
如果KS值越大,表示模型能够将正(1)、负(0)客户区分开来的程度越大,模型预测的准确率也越高。通常来讲,KS大于0.2就表示模型有较好的预测准确性了。
KS曲线绘制步骤如下:
1) 将测试集里所有观察对象经过模型打分预测为正(1)的对象按概率从高到低排序。
2) 分别计算每个概率分数所对应的实际上为正(1)、负(0)的观察对象累计值,以及它们分别占全体总数,实际正(1)、负(0)的总数量的百分比。
3) 将这两种累计的百分比与评分分数绘制在同一张图上,得到KS曲线,如下图:
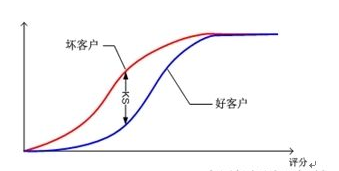
4) 各分数对应下的累计的、真正的正(1)观察对象的百分比与累计的、真正的负(0)观察对象的百分比之差的最大值就是KS值。
4.2.4 lift值
我们知道,二元预测模型在具体的业务场景中,都有一个random rate,所谓random rate,是指在不使用模型的时候,基于已有业务效果的正比例,也就是不使用模型之前“正”的实际观察对象在总体观察对象中的占比。如果经过建模,有一个不错的模型,那么这个模型就可以比较有效地锁定群体了,所谓有效,是指在预测概率的数值从高到低的排序中,排名靠前的观察值中,真正的“正”观察值在累计的总观察值里的占比应该是高于random rate的。

从上述lift公式中,引出了在模型评估中常用的两个评价指标,分别是响应率(%response)和捕获率(%captured response)。首先要把经过模型预测后为正(1)的观察对象按照预测概率从高到低排序,然后对这些观察对象按照均等的数量划分为10个区间,每个区间里观察对象的数量一致,这样各个区间可以被命名为排序最高的前10%的对象排序最高的前20%对象等。
响应率是指按上述概率分数排序后的某区间段或累计区间观察对象中,实际属于正(1)的观察对象占该区间或该累计区间总体观察对象数量的百分比。很明显,响应率越高说明该区间预测准确率越高。
捕获率是指上述排序区间的观察对象中,实际属于正(1)的观察对象占全体观察对象中属于正(1)的总数的百分比,同样是越高越好。