一、大数据
来源
当今社会数据量呈指数级增长,这些数据来自于用户行为监测系统、分布式系统、网络分析、传感器等。
特点(4V)
海量(Volume)、高速(Velocity)、多样(Variety)、准确(Veracity)
二、MapReduce
直观理解
MapReduce主要分为两步:映射(Map)和规约(Reduce)。
Map:负责任务分解,分解为若干个“简单的任务”来并行处理,前提是这些任务没有必然的依赖关系。python中的map函数:map(function, 列表1,列表2,...)。
Reduce:负责任务合并,把Map阶段的结果进行全局汇总。python中的reduce函数:reduce(function, 序列,初始值)。
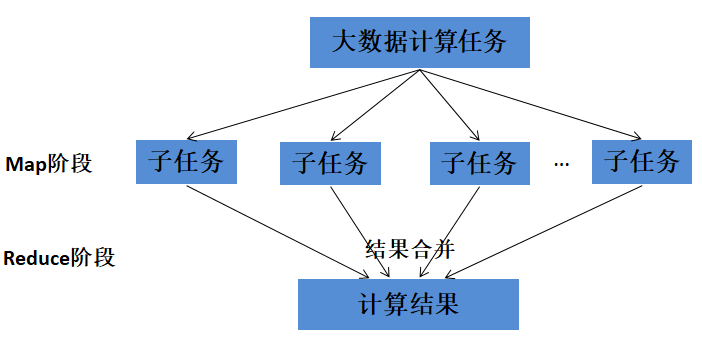
MapReduce编程模型

示例一:编写代码遍历一串列表,计算所有列表中数字之和。
例子一是单纯使用映射和规约两步。
a = [[1, 2, 1], [3, 2], [4, 9, 1, 0, 2]]
# 映射(建立sum函数和a之间映射关系)
sums = map(sum, a) # sums为生成器
'''
等价于:
sums = []
for sublist in a:
results = sum(sublist)
sums.append(results)
'''
# 规约(需要对返回结果的每一个元素应用一个函数)规约函数形式为reduce(function, sequence, initial)
def add(a, b):
return a + b
from functools import reduce
print(reduce(add, sums, 0))
"""
等价于:
initial = 0
current_result = initial
for element in sums:
current_result = add(current_result, element)
"""如何实现分布式计算?
在映射这一步把各个二级列表及函数说明分发到不同的计算机上,计算完成后,各计算机把结果返回主计算机(master)。然后master把结果发送给另一台计算机做规约。
示例二:单词统计。编写代码统计文档中的单词数量。
示例二的映射和规约都用键来调用,便于数据的区分和值的跟踪。
整体框架流程如下图所示:
(1)将原始数据转换为<k1,v1>形式。
(2) 解析后的<k1,v1>传给Map映射为中间结果形式<k2,v2>。
(3)<k2,v2>形成<k2,{v2,...}>传给Reduce,把相同k的值通过Reduce()输出形成<k3,v3>。

映射函数接收一键值对,返回键值对列表。本例中,接收的键值对:(文档编号,文档的文本内容),返回的键值对列表:(单词,单词的词频)。
def map_word_count(document_id, document):
counts = defaultdict(int)
for word in document.split():
counts[word] += 1
for word in counts:
yield (word, counts[word])shuffle操作:接收map生成器,将key值也就是word相同的单词词频append在一起,返回键值对{单词,词频列表}给reduce函数,reduce函数对词频列表进行sum操作。
def shuffle_words(results):
records = defaultdict(list)
for result in results:
for word, count in result:
records[word].append(count)
for word in records:
yield (word, records[word])规约函数:与映射函数一样,接收一键值对,返回键值对列表。输入:键为单词,值为shuffle后得到的作为键的单词在不同文档出现次数的列表。输出:键为单词,值为该单词在所有文档的出现次数之和。
def reduce_counts(word, list_of_counts):
return (word, sum(list_of_counts))调用实现:使用scikit-learn提供的来自20个新闻组的语料看下上述代码的实际效果 。
from sklearn.datasets import fetch_20newsgroups
dataset = fetch_20newsgroups(subset='train')
documents = dataset.data
# 映射
map_results = map(map_word_count, enumerate(documents), documents)
# map后的输出值
for i in map_results:
for v in i:
print(v)
shuffle_results = shuffle_words(map_results)
# shuffle后的输出值
for i in shuffle_results:
print(i)
# 规约
results_list = []
# reduce,遍历输出
for shuffle_result in shuffle_results:
result = reduce(reduce_counts, shuffle_result)
results_list.append(result)
# reduce后的输出值
for item in results_list:
print(item)数据集格式:

运行结果流程:
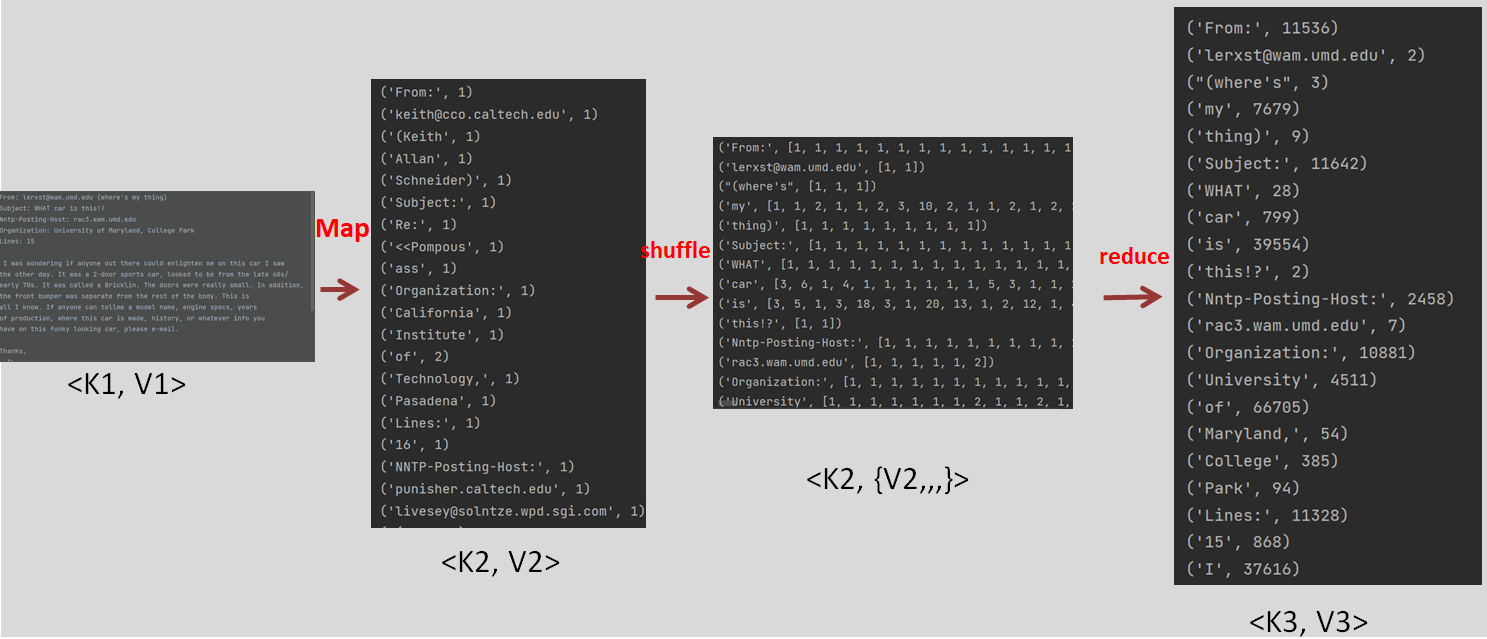
知识点:
(1)python中的生成器:是迭代器的一种,主要用yield函数创建生成器。
生成器创建:列表生成式创建和yield函数创建。
yield: return+生成器。return就是在程序中返回某个值,返回之后程序就不再往下运行了。生成器的意思就是当我们第一次调用next,遇到yield停止,下一次调用next时,从yield后面继续执行代码。
# 1.列表生成式创建()而非[]
generator_ex = (x*x for x in range(10))
# 2.yield函数创建
def fib(max):
n,a,b =0,0,1
while n < max:
yield b
a,b =b,a+b
n = n+1
return 'done'
print(fib(10))
生成器值的打印:两种方法打印生成器中的值。以上为例。一种是使用调用next计算生成器下一元素的值;另一种是使用for循环,因为generator也是可迭代对象。
生成器的生成器的值如何打印?
shuffle_results = shffule_words(map_results)
# 法一:不断调用next计算下一元素的值
for i in range(20):
print(shuffle_results.__next__())
# 法二:因为generator也是可迭代对象,使用for循环
for i in shuffle_results:
print(i)
# 打印生成器的生成器的值
for generator2 in generator1:
for value in generator2:
print(value)(2)MapReduce中的shuffle操作。
Map方法之后,Reduce方法之前的数据处理过程称之为Shuffle。一般地,shuffle操作就是把相同key的值append到一个列表,组成列表键值以给reduce使用sum等运算。具体地复杂用法见以下链接:https://blog.csdn.net/qq_43461159/article/details/123871436。
三、Hadoop MapReduce
Hadoop与MapReduce的简单关系
在hadoop的框架上采取MapReduce的模式处理海量数据。
MapReduce是一种模式。
Hadoop是一种框架,是一个实现了MapReduce模式的开源分布式并行编程框架。
Hadoop除MapReduce外其他处理大数据的工具有如下几种
(1)Hadoop分布式文件系统(Hadoop Distributed File System, HDFS):该文件系统可以将文件保存到多台计算机上,以防范硬件故障,提高带宽 。
(2)YARN:用于调度应用和管理计算机集群。
(3)Pig:用于MapReduce的高级语言。Hadoop MapReduce用Java语言实现,Pig对Java实现做 进一步封装,支持用其他语言来编写程序——包括Python。
(4)Hive:用于管理数据仓库和进行查询。
(5)HBase:对谷歌分布式数据库BigTable的一种实现。
四、应用:根据博主用词习惯判断博主性别。
加载数据集并查看某一用户所写博客的内容
访问http://u.cs.biu.ac.il/~koppel/BlogCorpus.htm网站,点击Download Corpus,下载数据集。
数据集中的每一个文件是一个博主的所有博客。文件名如下,包含博主的相关信息。依次是<博主编号,性别,年龄,行业,星座>。

我们指定一个文件名来看看:只查看post里的blog。
# 加载查看某一条数据集
filename = "./data/blogs/5114.male.25.indUnk.Scorpio.xml"
post = []
all_posts = []
with open(filename, encoding='ISO-8859-1') as inf:
post_start = False
for line in inf:
line = line.strip()
if line == "<post>":
post_start = True
elif line == "</post>":
post_start = False
all_posts.append("\n".join(post))
post = []
elif post_start:
post.append(line)
print(all_posts[0])
print(len(all_posts)) 输出结果:

抽取博客内容和性别信息
原文使用map函数抽取博客内容和性别信息。我使用普通的方法去抽取,代码如下:
我们只抽取了文件名为“51”开头的博客文件,抽取的性别和内容信息保存为csv文件,并且文件每一行为博主的性别及一篇博客的内容。(知识点1:for循环加载指定文件名,字典创建dataframe)
# 抽取博客内容和性别信息到输出文件(文件每一行为博主的性别及一篇博客的内容)。(知识点1:for循环加载指定文件名,字典创建dataframe)
# 1.抽取文件名为“51”开头的博客文件,保存到列表
path = "./data/blogs"
datanames = os.listdir(path)
filenames = []
for i in datanames:
# 抽取文件名为“51”开头的博客文件,保存到列表
if os.path.splitext(i)[0][:2] == "51":
filenames.append(i)
# 2. 抽取信息并用字典保存
# 加载“51”开头的文件名列表
gender_list = []
blog_list = []
for filename in filenames:
with open(os.path.join(path, filename), encoding='ISO-8859-1') as inf:
# 抽取性别信息
gender = filename.split('.')[1]
# 抽取博客内容
post_start = False
for line in inf:
line = line.strip()
if line == "<post>":
post_start = True
elif line == "</post>":
post_start = False
elif post_start:
if line != '':
gender_list.append(gender)
blog_list.append(line)
df = pd.DataFrame({'gender': gender_list, 'blog': blog_list})
# 将性别—博客信息保存为csv文件
df.to_csv('./data/train_gender_blogs.csv', index=False)
print(df)保存的csv文件如下:

训练朴素贝叶斯分类器
分别统计女性博主和男性博主使用每个单词的概率。对博客进行分类时,我们分别计算博客博主为女性的概率和博主为男性的概率,选取概率较大的,作为最终类别。输出结果每一行的第一个值为单词,第二值为一个字典,字典的键为性别,字典的值为给定性别使用该词的频率。
主要有两个步骤:两个步骤都使用到MapReduce模式。
1)第一步:抽取单词的概率。
Map,extract_words_mapping:接收一条博客数据,获取里面的所有单词并计算频率。
shuffle,shuffle_words,获得单词频率后,以(gender,word)为key进行分组,将key相同的频率以列表形式组合append在一起,传给后面的reduce进行sum。
Reduce,reducer_count_words:汇总每个性别使用每个单词的频率。
具体地,Map映射函数,接收一对键值对,返回一对键值对。输入键值对{博客编号,(性别,博客内容)},返回键值对{(性别,单词),频率}。
from collections import defaultdict
word_search_re = re.compile(r"[\w']+")
def extract_words_mapping(key, gender, blog):
all_words = word_search_re.findall(blog)
all_words = [word.lower() for word in all_words]
for word in all_words:
yield (gender, word), 1. / len(all_words)shuffle操作:输入map生成器,输出键值对{(性别,单词),频率列表}
def shuffle_words(results):
records = defaultdict(list)
for result in results:
for key, frequency in result:
records[key].append(frequency)
for key in records:
gender, word = key
yield (gender, word), records[(gender, word)]reduce规约函数:接收一对键值对,返回一对键值对。输入键值对:{(性别,单词),频率列表},输出键值对:{单词,(性别,频率之和)}。
def reducer_count_words(key, frequencies):
s = sum(frequencies)
gender, word = key
yield word, (gender, s)依次调用map->shuffle->reduce。
file = './data/gender_blogs.csv'
gender_blogs = pd.read_csv(file)
gender = list(gender_blogs['gender'])
blogs = list(gender_blogs['blog'])
map_results = map(extract_words_mapping, enumerate(blogs), gender, blogs)
# map生成器的值输出
for i in map_results:
for v in i:
print(v)
shuffle_results = shuffle_words(map_results)
# shuffle后的生成器值输出
for i in shuffle_results:
print(i)
results = []
for srv in shuffle_results:
result = reduce(reducer_count_words, srv)
results.append(result)
# reduce后的值输出
for i in results:
for v in i:
print(v)结果流程如下:

2)第二步:比较一个单词在男女博主所写博客出现的概率,选择概率较大的性别作为分类结果,写入输出文件。
Map:不需要
Shuffle:把每个单词在所有文章中出现频率按照性别汇集到一起,输出单词及频率字典。
Reduce:比较shuffle后的频率字典中单个单词的男女使用频率,输出概率较大的性别作为分类结果。
具体地,shuffle操作:输入是步骤1的规约结果即{word,(gender,frequencies)},输出{word,{gender1:frequencies1,gender2:frequencies2}}
def shuffle_list(results):
records = defaultdict(dict)
for result in results:
for word, (gender,s) in result:
records[word][gender] = s
for word in records:
yield word, records[word]reduce函数:输入为单词,男女使用单词的概率列表,{ {word,{gender1:frequencies1,gender2:frequencies2}}},输出为男女使用该单词概率较大的{word,max({gender1:frequencies1,gender2:frequencies2}) }。
def compare_words_reducer(word, values):
per_gender = {}
for key, value in values.items():
if(value == max(values.values())):
per_gender[key] = value
yield word, per_gender依次调用shuffle->reduce。
for srv in shuffle_results:
result = reduce(reducer_count_words, srv)
results.append(result)
# 在步骤1中的reduce之后调用shuffle函数
shffle_list_results = shuffle_list(results)
new_results = []
for slv in shffle_list_results:
# 打印步骤2shuffle后的值
# print(slv)
# 调用步骤2reduce
result = reduce(compare_words_reducer, slv)
# print(result.__next__())
# 使用for循环输出生成器的值,需要先存到列表里
new_results.append(result)
# 步骤2reduce后的值输出
# word和label列表为保存文件使用,先忽略
word = []
label = []
for i in new_results:
for v in i:
print(v)
word.append(v[0])
label.append(v[1])结果流程如图:

将分类结果保存为model.csv文件。
# 将运行朴素贝叶斯分类器所需的概率信息保存到一个csv文件里
df = pd.DataFrame({"word": word, "label": label})
df.to_csv('./data/model.csv', index=False, header=False)
# print(df)3)组装
(1)声明模型加载函数
# 声明加载模型函数
def load_model(model_filename):
model = defaultdict(lambda : defaultdict(float))
df = pd.read_csv(model_filename)
for i in range(df.shape[0]):
word = df['word'][i]
values = eval(df['label'][i])
# 在模型中,为单词和概率字典建立起映射关系
model[word] = values
return model(2)预测
# 预测函数
word_search_re = re.compile(r"[\w']+")
def nb_predict(model, document):
probabilities = defaultdict(lambda: 1)
words = word_search_re.findall(document)
# 遍历每一个单词,找出数据集中每个性别使用该单词的概率
for word in set(words):
probabilities['male'] += np.log(model[word].get('male', 1e-15))
probabilities['female'] += np.log(model[word].get('female', 1e-15))
# 根据概率对性别进行排序,以概率最高的性别作为预测结果返回
most_likely_genders = sorted(probabilities.items(), key=itemgetter(1), reverse=True)
return most_likely_genders[0][0]
(3)依次调用加载模型并进行预测
model_filename = './data/model.csv'
model = load_model(model_filename)
# print(model['slashdot']['male'])
# 预测
new_post = """ Every day should be a half day. Took the afternoon
off to hit the dentist, and while I was out I managed to get my oil
changed, too. Remember that business with my car dealership this
winter? Well, consider this the epilogue. The friendly fellas at the
Valvoline Instant Oil Change on Snelling were nice enough to notice
that my dipstick was broken, and the metal piece was too far down in
its little dipstick tube to pull out. Looks like I'm going to need a
magnet. Damn you, Kline Nissan, daaaaaaammmnnn yooouuuu.... Today
I let my boss know that I've submitted my Corps application. The news
has been greeted by everyone in the company with a level of enthusiasm
that really floors me. The back deck has finally been cleared off
by the construction company working on the place. This company, for
anyone who's interested, consists mainly of one guy who spends his
days cursing at his crew of Spanish-speaking laborers. Construction
of my deck began around the time Nixon was getting out of office.
"""
classification_result = nb_predict(model, new_post)
print(classification_result)(3)在更大的数据集上训练和测试
上述例子中,我们在以“51”开头的blog上进行了训练,并在其中复制了一条blog进行预测。
本节我们增加训练集,在以6和7开头的blog上进行测试,剩下的用来训练。
A.训练集抽取性别和博客信息
将第一步中抽取信息代码的条件用下面替换。训练集保存为train_gender_blogs.csv,然后用train_gender_blogs.csv的文件重复第一步和第二步,保存model文件,用来测试。
if os.path.splitext(i)[0][0] != "5" or os.path.splitext(i)[0][0] != "6":B.测试集抽取博客信息
path = "./data/blogs"
datanames = os.listdir(path)
filenames = []
for i in datanames:
# 抽取文件名为“6”或“7”开头的博客文件,保存到列表
if os.path.splitext(i)[0][0] == "5" or os.path.splitext(i)[0][0] == "6":
filenames.append(i)
# 2. 抽取信息并用字典保存
# 加载“6”和“7”开头的文件名列表
gender_list = []
blog_list = []
for filename in filenames:
with open(os.path.join(path, filename), encoding='ISO-8859-1') as inf:
# 抽取性别信息
gender = filename.split('.')[1]
# 抽取博客内容
post_start = False
for line in inf:
line = line.strip()
if line == "<post>":
post_start = True
elif line == "</post>":
post_start = False
elif post_start:
if line != '':
gender_list.append(gender)
blog_list.append(line)
df = pd.DataFrame({'gender': gender_list, 'blog': blog_list})
df = pd.Series(blog_list)
# 将性别—博客信息保存为csv文件
df.to_csv('./data/test_gender_blogs.csv', index=False, header=False)
# print(df)用测试集的博客信息进行预测:
# 测试函数
def nb_predict_many(model, input_filename):
df = pd.read_csv(input_filename)
for i in range(df.shape[0]):
actual_gender = df["gender"][i]
blog_post = df["blog"][i]
yield actual_gender, nb_predict(model, blog_post)
# 加载模型并在大数据集上预测
y_true = []
y_pred = []
testing_filename = './data/test_gender_blogs.csv'
for actual_gender, predicted_gender in nb_predict_many(model, testing_filename):
y_true.append(actual_gender == "female")
y_pred.append(predicted_gender == "female")
y_true = np.array(y_true, dtype="int")
y_pred = np.array(y_pred, dtype="int")
from sklearn.metrics import f1_score
print("f1={:.4f}".format(f1_score(y_true, y_pred, pos_label=None)))五、小结
为了预测博主的性别,我们从博客文章中抽取词频特征。我们用映射和规约 方法抽取博客内容和词频。抽取完成后,训练朴素贝叶斯分类器,预测博主性别 。