# 导入模块
import pandas as pd
import numpy as np
# 构造序列
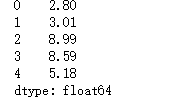
gdp1 = pd.Series([2.8,3.01,8.99,8.59,5.18])
print(gdp1)
# 取出gdp1中的第一、第四和第五个元素
print('行号风格的序列:\n',gdp1[[0,3,4]])
# 数学函数--取对数
print('通过numpy函数:\n',np.log(gdp1))
# 平均gdp
print('通过numpy函数:\n',np.mean(gdp1))
print('通过序列的方法:\n',gdp1.mean())

gdp2 = pd.Series({'北京':2.8,'上海':3.01,'广东':8.99,'江苏':8.59,'浙江':5.18})
print(gdp2)
# 取出gdp2中的第一、第四和第五个元素
print('行名称风格的序列:\n',gdp2[[0,3,4]])
# 取出gdp2中上海、江苏和浙江的GDP值
print('行名称风格的序列:\n',gdp2[['上海','江苏','浙江']])

gdp3 = pd.Series(np.array((2.8,3.01,8.99,8.59,5.18)))
print(gdp3)
# 构造数据框
df1 = pd.DataFrame([['张三',23,'男'],['李四',27,'女'],['王二',26,'女']])
print('嵌套列表构造数据框:\n',df1)

df2 = pd.DataFrame({'姓名':['张三','李四','王二'],'年龄':[23,27,26],'性别':['男','女','女']})
print('字典构造数据框:\n',df2)

df3 = pd.DataFrame(np.array([['张三',23,'男'],['李四',27,'女'],['王二',26,'女']]))
print('二维数组构造数据框:\n',df3)

# 读取文本文件中的数据
user_income = pd.read_table(r'F:\\python_Data_analysis_and_mining\\05\\data_test01.txt', sep = ',',
parse_dates={'birthday':[0,1,2]},skiprows=2, skipfooter=3,
comment='#', encoding='utf8', thousands='&')
print(user_income)

child_cloth = pd.read_excel(io = r'F:\\python_Data_analysis_and_mining\\05\\data_test02.xlsx', header = None,
names = ['Prod_Id','Prod_Name','Prod_Color','Prod_Price'], converters = {0:str})
print(child_cloth)

# 读取电子表格数据
pd.read_excel(io = r'C:\Users\Administrator\Desktop\data_test02.xlsx', header = None,
names = ['Prod_Id','Prod_Name','Prod_Color','Prod_Price'])
# 导入模块
import pymysql
# 连接MySQL数据库
conn = pymysql.connect(host='localhost', user='root', password='1q2w3e4r',
database='test', port=3306, charset='utf8')
# 读取数据
user = pd.read_sql('select * from topy', conn)
# 关闭连接
conn.close()
# 数据输出
user
# 导入第三方模块
import pymssql
# 连接SQL Server数据库
connect = pymssql.connect(server = 'localhost', user = '', password = '',
database = 'train', charset = 'utf8')
# 读取数据
data = pd.read_sql("select * from sec_buildings where direction = '朝南'", con=connect)
# 关闭连接
connect.close()
# 数据输出
data.head()
import numpy as np
import pandas as pd
# 数据类型转换及描述统计
# 数据读取
sec_cars = pd.read_table(r'F:\\python_Data_analysis_and_mining\\05\\sec_cars.csv', sep = ',')
# 预览数据的前五行
print(sec_cars.head())
# 查看数据的行列数
print('数据集的行列数:\n',sec_cars.shape)
# 查看数据集每个变量的数据类型
print('各变量的数据类型:\n',sec_cars.dtypes)
# 修改二手车上牌时间的数据类型
sec_cars.Boarding_time = pd.to_datetime(sec_cars.Boarding_time, format = '%Y年%m月')
# 预览数据的前五行
print(sec_cars.head())
# 修改二手车新车价格的数据类型
# sec_cars.New_price = sec_cars.New_price.str[:-1].astype('float')
# 重新查看各变量数据类型
print(sec_cars.dtypes)
# 数据的描述性统计
print(sec_cars.describe())
# 数据的形状特征
# 挑出所有数值型变量
num_variables = sec_cars.columns[sec_cars.dtypes !='object'][1:]
print(num_variables)
# 自定义函数,计算偏度和峰度
def skew_kurt(x):
skewness = x.skew()
kurtsis = x.kurt()
# 返回偏度值和峰度值
return pd.Series([skewness,kurtsis], index = ['Skew','Kurt'])
# 运用apply方法
print(sec_cars[num_variables].apply(func = skew_kurt, axis = 0))
# 离散型变量的统计描述
print()
print(sec_cars.describe(include = ['object']))

# 离散变量频次统计
Freq = sec_cars.Discharge.value_counts()
print(Freq)
print(sec_cars.shape)
print(sec_cars.shape[0])
Freq_ratio = Freq/sec_cars.shape[0]
print(Freq_ratio)

Freq_df = pd.DataFrame({'Freq':Freq,'Freq_ratio':Freq_ratio})
print(Freq_df.head())
# 将行索引重设为变量
Freq_df.reset_index(inplace = True)
print(Freq_df.head())

# 数据读入
df = pd.read_excel(r'F:\\python_Data_analysis_and_mining\\05\\data_test03.xlsx')
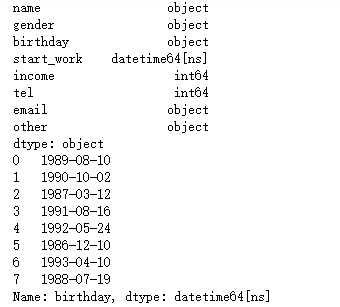
# 各变量数据类型
print(df.dtypes)
# 将birthday变量转换为日期型
df.birthday = pd.to_datetime(df.birthday, format = '%Y/%m/%d')
print(df.birthday)
# 将手机号转换为字符串
df.tel = df.tel.astype('str')
print(df.dtypes)
print(df.birthday.dt.year)
print(df.start_work.dt.year)
# 新增年龄和工龄两列
df['age'] = pd.datetime.today().year - df.birthday.dt.year
df['workage'] = pd.datetime.today().year - df.start_work.dt.year
print(df.head())
# 将手机号中间四位隐藏起来
df.tel = df.tel.apply(func = lambda x : x.replace(x[3:7], '****'))
print(df.head())
# 取出邮箱的域名
df['email_domain'] = df.email.apply(func = lambda x : x.split('@')[1])
print(df.head())
# 取出用户的专业信息
df['profession'] = df.other.str.findall('专业:(.*?),')
print(df.head())
# 去除birthday、start_work和other变量
df.drop(['birthday','start_work','other'], axis = 1, inplace = True)
print(df.head())
# 常用日期处理方法
dates = pd.to_datetime(pd.Series(['1989-8-18 13:14:55','1995-2-16']), format = '%Y-%m-%d %H:%M:%S')
print('返回日期值:\n',dates.dt.date)
print('返回季度:\n',dates.dt.quarter)
print('返回几点钟:\n',dates.dt.hour)
print('返回年中的天:\n',dates.dt.dayofyear)
print('返回年中的周:\n',dates.dt.weekofyear)
print('返回星期几的名称:\n',dates.dt.weekday_name)
print('返回月份的天数:\n',dates.dt.days_in_month)

# 数据清洗
# 数据读入
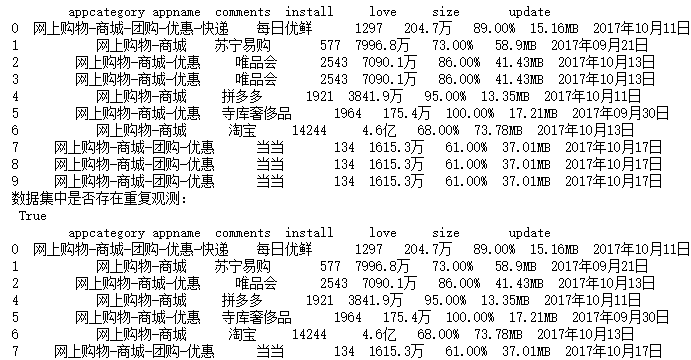
df = pd.read_excel(r'F:\\python_Data_analysis_and_mining\\05\\data_test04.xlsx')
print(df)
# 重复观测的检测
print('数据集中是否存在重复观测:\n',any(df.duplicated()))
# 删除重复项
df.drop_duplicates(inplace = True)
print(df)
# 数据读入
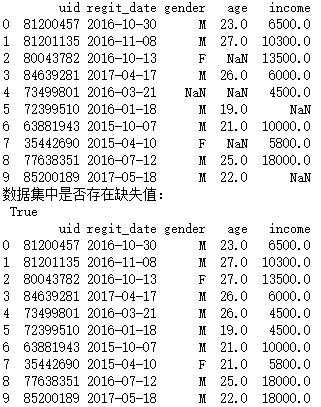
df = pd.read_excel(r'F:\\python_Data_analysis_and_mining\\05\\data_test05.xlsx')
print(df)
# 缺失观测的检测
print('数据集中是否存在缺失值:\n',any(df.isnull()))
# 删除法之记录删除
df.dropna()
# print(df)
# 删除法之变量删除
df.drop('age', axis = 1)
# print(df)
# 替换法之前向替换
df.fillna(method = 'ffill',inplace = True)
# print(df)
# 替换法之后向替换
df.fillna(method = 'bfill',inplace = True)
# print(df)
# 替换法之常数替换
df.fillna(value = 0)
# print(df)
# 替换法之统计值替换
df = df.fillna(value = {'gender':df.gender.mode()[0], 'age':df.age.mean(), 'income':df.income.median()})
print(df)
# 数据读入
sunspots = pd.read_table(r'F:\\python_Data_analysis_and_mining\05\\sunspots.csv', sep = ',')
print(sunspots.shape)
# 异常值检测之标准差法
xbar = sunspots.counts.mean()
print(xbar)
xstd = sunspots.counts.std()
print(xstd)
print('标准差法异常值上限检测:\n',any(sunspots.counts > xbar + 2 * xstd))
print('标准差法异常值下限检测:\n',any(sunspots.counts < xbar - 2 * xstd))
# 异常值检测之箱线图法
Q1 = sunspots.counts.quantile(q = 0.25)
print(Q1)
Q3 = sunspots.counts.quantile(q = 0.75)
print(Q3)
IQR = Q3 - Q1
print(IQR)
print('箱线图法异常值上限检测:\n',any(sunspots.counts > Q3 + 1.5 * IQR))
print('箱线图法异常值下限检测:\n',any(sunspots.counts < Q1 - 1.5 * IQR))

# 导入绘图模块
import matplotlib.pyplot as plt
# 设置绘图风格
plt.style.use('ggplot')
# 绘制直方图
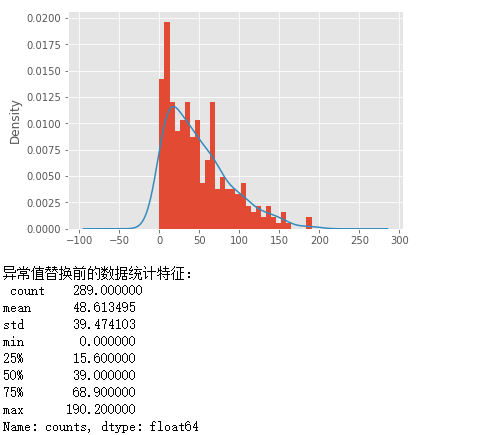
sunspots.counts.plot(kind = 'hist', bins = 30, normed = True)
# 绘制核密度图
sunspots.counts.plot(kind = 'kde')
# 图形展现
plt.show()
# 替换法处理异常值
print('异常值替换前的数据统计特征:\n',sunspots.counts.describe())
# 箱线图中的异常值判别上限
UL = Q3 + 1.5 * IQR
print('判别异常值的上限临界值:\n',UL)
# 从数据中找出低于判别上限的最大值
replace_value = sunspots.counts[sunspots.counts < UL].max()
print('用以替换异常值的数据:\n',replace_value)
# 替换超过判别上限异常值
sunspots.counts[sunspots.counts > UL] = replace_value
print('异常值替换后的数据统计特征:\n',sunspots.counts.describe())
df1 = pd.DataFrame({'name':['张三','李四','王二','丁一','李五'],
'gender':['男','女','女','女','男'],
'age':[23,26,22,25,27]}, columns = ['name','gender','age'])
print(df1)
# 取出数据集的中间三行(即所有女性),并且返回姓名和年龄两列
a = df1.iloc[1:4,[0,2]]
print(a)
b = df1.loc[1:3, ['name','age']]
print(b)
c = df1.ix[1:3,[0,2]]
print(c)
# 将员工的姓名用作行标签
df2 = df1.set_index('name')
print(df2)
# 取出数据集的中间三行
a = df2.iloc[1:4,:]
print(a)
b = df2.loc[['李四','王二','丁一'],:]
print(b)
c = df2.ix[1:4,:]
print(c)
# 使用筛选条件,取出所有男性的姓名和年龄
# df1.iloc[df1.gender == '男',]
a = df1.loc[df1.gender == '男',['name','age']]
print(a)
b = df1.ix[df1.gender == '男',['name','age']]
print(b)

# 数据读取
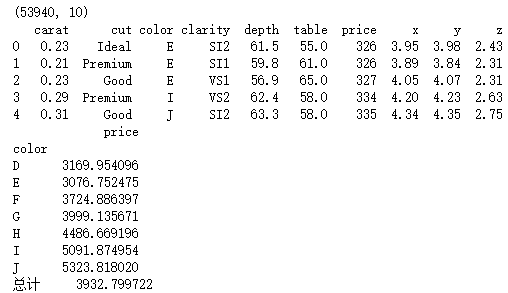
diamonds = pd.read_table(r'F:\\python_Data_analysis_and_mining\\05\\diamonds.csv', sep = ',')
print(diamonds.shape)
print(diamonds.head())
# 单个分组变量的均值统计
a = pd.pivot_table(data = diamonds, index = 'color', values = 'price', margins = True, margins_name = '总计')
print(a)
# 两个分组变量的列联表
# 导入numpy模块
import numpy as np
b = pd.pivot_table(data = diamonds, index = 'clarity', columns = 'cut', values = 'carat',
aggfunc = np.size,margins = True, margins_name = '总计')
print(b)
# 构造数据集df1和df2
df1 = pd.DataFrame({'name':['张三','李四','王二'], 'age':[21,25,22], 'gender':['男','女','男']})
print(df1)
df2 = pd.DataFrame({'name':['丁一','赵五'], 'age':[23,22], 'gender':['女','女']},)
print(df2)
# 数据集的纵向合并
a = pd.concat([df1,df2], keys = ['df1','df2'])
print(a)
# 如果df2数据集中的“姓名变量为Name”
df2 = pd.DataFrame({'Name':['丁一','赵五'], 'age':[23,22], 'gender':['女','女']})
# 数据集的纵向合并
b = pd.concat([df1,df2])
print(b)

# 构造数据集
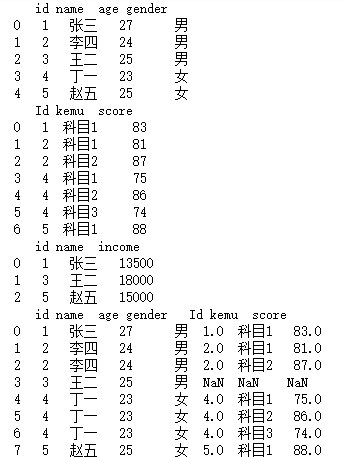
df3 = pd.DataFrame({'id':[1,2,3,4,5],'name':['张三','李四','王二','丁一','赵五'],'age':[27,24,25,23,25],'gender':['男','男','男','女','女']})
print(df3)
df4 = pd.DataFrame({'Id':[1,2,2,4,4,4,5],'kemu':['科目1','科目1','科目2','科目1','科目2','科目3','科目1'],'score':[83,81,87,75,86,74,88]})
print(df4)
df5 = pd.DataFrame({'id':[1,3,5],'name':['张三','王二','赵五'],'income':[13500,18000,15000]})
print(df5)
# 三表的数据连接
# 首先df3和df4连接
merge1 = pd.merge(left = df3, right = df4, how = 'left', left_on='id', right_on='Id')
print(merge1)
# 再将连接结果与df5连接
merge2 = pd.merge(left = merge1, right = df5, how = 'left')
print(merge2)
# 数据读取
diamonds = pd.read_table(r'F:\\python_Data_analysis_and_mining\\05\\diamonds.csv', sep = ',')
print(diamonds.shape)
print(diamonds.head())
# 通过groupby方法,指定分组变量
grouped = diamonds.groupby(by = ['color','cut'])
print(grouped)
# 对分组变量进行统计汇总
# 通过groupby方法,指定分组变量
grouped = diamonds.groupby(by = ['color','cut'])
print(grouped)
# 对分组变量进行统计汇总
result = grouped.aggregate({'color':np.size, 'carat':np.min, 'price':np.mean, 'face_width':np.max})
# 调整变量名的顺序
result = pd.DataFrame(result, columns=['color','carat','price','face_width'])
# 数据集重命名
result.rename(columns={'color':'counts','carat':'min_weight','price':'avg_price','face_width':'max_face_width'}, inplace=True)
# 将行索引变量数据框的变量
result.reset_index(inplace=True)
result
