因子分析
在某种程度上可以看成是主成分分析法的推广,优势主要体现在解释选取的综合因子时更加容易
文章目录
(1) 因子分析实例
为了评价高中学生将来进入大学时的学习能力,抽了 200 200 200 名高中生进行问卷调查,共 50 50 50 个问题。所有这些问题可简单的归结为阅读理解、数学水平和艺术修养这三个方面。这就是一个因子分析模型,每一个方面就是一个因子。
(2) 因子分析前的检验
- KMO检验
- KMO 值越接近 1 1 1,意味着变量间的相关性越强,KMO 值越接近 0 0 0,意味着变量间的相关性越弱。相关性越强越适合进行因子分析。
- KMO> 0.9 0.9 0.9 非常适合进行因子分析, 0.9 0.9 0.9 >KMO> 0.8 0.8 0.8 适合进行因子分析, 0.8 0.8 0.8 >KMO> 0.7 0.7 0.7 一般, 0.7 0.7 0.7 不太适合。
- 巴特利特球性检验
- 原假设为:相关系数矩阵是一个单位矩阵 (不适合做因子分析,指标之间的相关性太差,不适合降维)。
- 备择假设为:适合做因子分析。
- 使用 SPSS 可以计算出 p p p 值。
(3) 因子分析原理
- 大小为 n × p n\times p n×p 的随机向量 x = ( x 1 , x 2 , … , x p ) T x=(x_1,x_2,\dots,x_p)^T x=(x1,x2,…,xp)T,均值为 μ = ( μ 1 , μ 2 , … , μ p ) T \mu=(\mu_1,\mu_2,\dots,\mu_p)^T μ=(μ1,μ2,…,μp)T,特殊因子向量 ϵ = ( ϵ 1 , ϵ 2 , … , ϵ p ) T \epsilon=(\epsilon_1,\epsilon_2,\dots,\epsilon_p)^T ϵ=(ϵ1,ϵ2,…,ϵp)T,公因子向量 f = ( f 1 , f 2 , … , f p ) T f=(f_1,f_2,\dots,f_p)^T f=(f1,f2,…,fp)T,载荷矩阵 A p × m = ( a i j ) p × m A_{p\times m}=(a_{ij})_{p\times m} Ap×m=(aij)p×m ,注意这里 x i , μ i , ϵ i , f i x_i,\mu_i,\epsilon_i,f_i xi,μi,ϵi,fi 都是 n × 1 n\times1 n×1 维的向量。
- 因子分析的一般模型
{ x 1 = μ 1 + a 11 f 1 + a 12 f 2 + ⋯ + a 1 m f m + ϵ 1 x 2 = μ 2 + a 21 f 1 + a 22 f 2 + ⋯ + a 2 m f m + ϵ 2 ⋮ x p = μ p + a p 1 f 1 + a p 2 f 2 + ⋯ + a p m f m + ϵ p \left\{ \begin{aligned} x_1&=\mu_1+a_{11}f_1+a_{12}f_2+\dots+a_{1m}f_m+\epsilon_1\\ x_2&=\mu_2+a_{21}f_1+a_{22}f_2+\dots+a_{2m}f_m+\epsilon_2\\ &\vdots\\ x_p&=\mu_p+a_{p1}f_1+a_{p2}f_2+\dots+a_{pm}f_m+\epsilon_p\\ \end{aligned} \right. ⎩⎪⎪⎪⎪⎪⎨⎪⎪⎪⎪⎪⎧x1x2xp=μ1+a11f1+a12f2+⋯+a1mfm+ϵ1=μ2+a21f1+a22f2+⋯+a2mfm+ϵ2⋮=μp+ap1f1+ap2f2+⋯+apmfm+ϵp
表示为矩阵的形式: x = μ + A f + ϵ x=\mu+Af+\epsilon x=μ+Af+ϵ - 对模型的相关假设
{ E ( f ) = 0 E ( ϵ ) = 0 V a r ( f ) = I V a r ( ϵ ) = D = d i a g ( σ 1 2 , σ 2 2 , … , σ p 2 ) C o v ( f , ϵ ) = 0 \left\{ \begin{aligned} &E(f)=0\\ &E(\epsilon)=0\\ &Var(f)=I\\ &Var(\epsilon)=D=diag(\sigma_1^2,\sigma_2^2,\dots,\sigma_p^2)\\ &Cov(f,\epsilon)=0\\ \end{aligned} \right. ⎩⎪⎪⎪⎪⎪⎪⎨⎪⎪⎪⎪⎪⎪⎧E(f)=0E(ϵ)=0Var(f)=IVar(ϵ)=D=diag(σ12,σ22,…,σp2)Cov(f,ϵ)=0
公因子不相关并且具有单位方差,特殊因子和公因子也不相关。 - 解释:特殊因子向量其实就像噪声,是一个无关紧要的向量,公因子向量表现的就是提取的各个公因子。
(4) 因子模型的性质
① ① ① x x x 的协方差矩阵的分解
V a r ( x ) = E [ ( x − μ ) ( x − μ ) T ] = E [ ( A f + ϵ ) ( A f + ϵ ) T ] = A E ( f f T ) A T + A E ( f ϵ T ) + E ( ϵ f T ) A T + E ( ϵ ϵ T ) = A V a r ( f ) A T + V a r ( ϵ ) = A A T + D = ∑ \begin{aligned} Var(x)&=E[(x-\mu)(x-\mu)^T]=E[(Af+\epsilon)(Af+\epsilon)^T]\\ &=AE(ff^T)A^T+AE(f\epsilon^T)+E(\epsilon f^T)A^T+E(\epsilon\epsilon^T)\\ &=AVar(f)A^T+Var(\epsilon)\\ &=AA^T+D=\sum\nolimits \\ \end{aligned} Var(x)=E[(x−μ)(x−μ)T]=E[(Af+ϵ)(Af+ϵ)T]=AE(ffT)AT+AE(fϵT)+E(ϵfT)AT+E(ϵϵT)=AVar(f)AT+Var(ϵ)=AAT+D=∑
② ② ② ⭐️因子载荷不唯一 (由于载荷的不唯一才可以通过调整载荷矩阵使解释变得更容易)
- 取 T T T 为任意一个 m × m m\times m m×m 的正交矩阵,并取 A ∗ = A T A^*=AT A∗=AT, f ∗ = T T f f^*=T^Tf f∗=TTf,将 A ∗ A^* A∗ 与 f ∗ f^* f∗ 代入相关假设之中,发现还成立,因此可以将 A A A 改为 A ∗ A^* A∗。
(5) 因子载荷矩阵的统计意义
- 原始变量 x i x_i xi 与公因子 f j f_j fj 之间的协方差
C o v ( x i , f j ) = ∑ k = 1 m a i k C o v ( f k , f j ) + C o v ( ϵ i , f j ) = a i j Cov(x_i,f_j)=\sum_{k=1}^ma_{ik}Cov(f_k,f_j)+Cov(\epsilon_i,f_j)=a_{ij} Cov(xi,fj)=k=1∑maikCov(fk,fj)+Cov(ϵi,fj)=aij
若 x x x 已经经过标准化,则 a i j = ρ ( x i , f j ) a_{ij}=\rho(x_i,f_j) aij=ρ(xi,fj) 表示 x i x_i xi 和 f j f_j fj 之间的相关系数。 - A A A 的行元素平方和 h i 2 = ∑ j = 1 m a i j 2 h_i^2=\displaystyle\sum_{j=1}^ma_{ij}^2 hi2=j=1∑maij2 ———原始变量 x i x_i xi 对公因子依赖的程度。
- 当 x x x 没有进行标准化时
σ i i = V ( x i ) = a i 1 2 V ( f 1 ) + a i 2 2 V ( f 2 ) + ⋯ + a i m 2 V ( f m ) + V ( ϵ i ) = a i 1 2 + a i 2 2 + ⋯ + a i m 2 + σ i 2 = h i 2 + σ i 2 \begin{aligned} \sigma_{ii}=V(x_i)&=a_{i1}^2V(f_1)+a_{i2}^2V(f_2)+\dots+a_{im}^2V(f_m)+V(\epsilon_i)\\ &=a_{i1}^2+a_{i2}^2+\dots+a_{im}^2+\sigma_i^2\\ &=h_i^2+\sigma_i^2 \end{aligned} σii=V(xi)=ai12V(f1)+ai22V(f2)+⋯+aim2V(fm)+V(ϵi)=ai12+ai22+⋯+aim2+σi2=hi2+σi2
其中 σ i i \sigma_{ii} σii 称为个性方差。 - 当 x x x 进行过标准化之后
1 = h i 2 + σ i 2 1=h_i^2+\sigma_i^2 1=hi2+σi2
- 当 x x x 没有进行标准化时
- A A A 的列元素平方和 g j 2 = ∑ i = 1 p a i j 2 g_j^2=\displaystyle\sum_{i=1}^pa_{ij}^2 gj2=i=1∑paij2 ———公因子 f j f_j fj 对 x x x 的贡献。
- 取 g j 2 = ∑ i = 1 p a i j 2 ( j = 1 , 2 , … , m ) g_j^2=\displaystyle\sum_{i=1}^pa_{ij}^2~~(j=1,2,\dots,m) gj2=i=1∑paij2 (j=1,2,…,m)
∑ i = 1 p V ( x i ) = ∑ i = 1 p a i 1 2 V ( f 1 ) + ∑ i = 1 p a i 2 2 V ( f 2 ) + ⋯ + ∑ i = 1 p a i m 2 V ( f m ) + ∑ i = 1 p V ( ϵ i ) = g 1 2 + g 2 2 + ⋯ + g m 2 + ∑ i = 1 p σ i 2 \begin{aligned} \sum_{i=1}^pV(x_i)&=\sum_{i=1}^pa_{i1}^2V(f_1)+\sum_{i=1}^pa_{i2}^2V(f_2)+\dots+\sum_{i=1}^pa_{im}^2V(f_m)+\sum_{i=1}^pV(\epsilon_i)\\ &=g_1^2+g_2^2+\dots+g_m^2+\sum_{i=1}^p\sigma_i^2\\ \end{aligned} i=1∑pV(xi)=i=1∑pai12V(f1)+i=1∑pai22V(f2)+⋯+i=1∑paim2V(fm)+i=1∑pV(ϵi)=g12+g22+⋯+gm2+i=1∑pσi2 - g j 2 g_j^2 gj2 是衡量公因子 f j f_j fj 重要性的一个尺度,可视为公因子 f j f_j fj 对 x x x 的贡献。
- 取 g j 2 = ∑ i = 1 p a i j 2 ( j = 1 , 2 , … , m ) g_j^2=\displaystyle\sum_{i=1}^pa_{ij}^2~~(j=1,2,\dots,m) gj2=i=1∑paij2 (j=1,2,…,m)
(6) 参数估计
- x 1 , x 2 , … , x n x_1,x_2,\dots,x_n x1,x2,…,xn 是一组 p p p 维的样本。则可以估计 μ \mu μ 和 ∑ \sum ∑ 分别为 x ‾ = 1 n ∑ i = 1 n x i \overline{x}=\dfrac{1}{n}\sum_{i=1}^nx_i x=n1i=1∑nxi
S 2 = 1 n − 1 ∑ i = 1 n ( x i − x ‾ ) ( x i − x ‾ ) T S^2=\dfrac{1}{n-1}\sum_{i=1}^n(x_i-\overline{x})(x_i-\overline{x})^T S2=n−11i=1∑n(xi−x)(xi−x)T - 还需要估计因子载荷矩阵 A A A 与个性方差矩阵 D = d i a g ( σ 1 2 , σ 2 2 , … , σ p 2 ) D=diag(\sigma_1^2,\sigma_2^2,\dots,\sigma_p^2) D=diag(σ12,σ22,…,σp2)
- 主成分法
- 最大似然法
- 主因子法
(7) 确定公共因子的个数
碎石检验:当某个特征值较前一特征值出现较大的下降,而这个特征值较小,其后面的特征值变化不大,说明添加相应于该特征值的因素只能增加很少的信息,因此只取前几几个特征值。
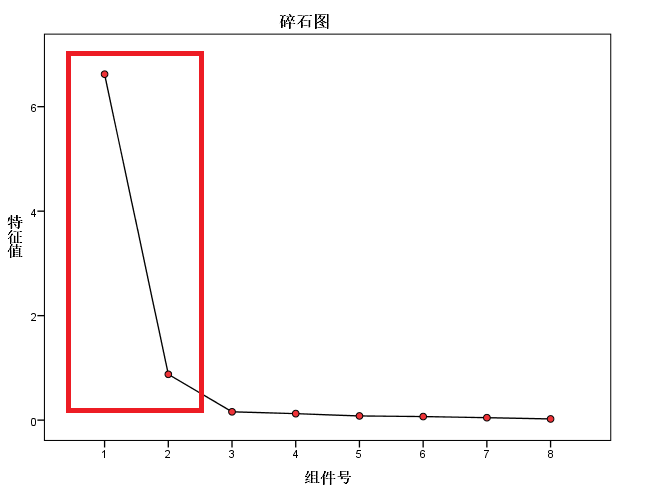
(8) 因子旋转
- 因子旋转的目的,使公共因子的载荷系数的绝对值更可能接近 0 0 0 或 1 1 1,这样可以使因子更好分析。
- 使用 SPSS。
(9) 因子得分
- 反过来将公共因子表示为原变量的线性组合。
{ f 1 = b 11 x 1 + b 12 x 2 + ⋯ + b 1 m x p f 2 = b 21 x 1 + b 22 x 2 + ⋯ + b 2 m x p ⋮ f m = b m 1 x 1 + b m 2 x 2 + ⋯ + b m p x p \left\{ \begin{aligned} f_1&=b_{11}x_1+b_{12}x_2+\dots+b_{1m}x_p\\ f_2&=b_{21}x_1+b_{22}x_2+\dots+b_{2m}x_p\\ &\vdots\\ f_m&=b_{m1}x_1+b_{m2}x_2+\dots+b_{mp}x_p\\ \end{aligned} \right. ⎩⎪⎪⎪⎪⎪⎨⎪⎪⎪⎪⎪⎧f1f2fm=b11x1+b12x2+⋯+b1mxp=b21x1+b22x2+⋯+b2mxp⋮=bm1x1+bm2x2+⋯+bmpxp
b i j b_{ij} bij 就是第 i i i 个因子的得分对应于第 j j j 个变量。 - 常用 Anderson-Rubin 方法和 Bartlett 得分。