python机器学习之使用sklearn库进行图片、文本的分类
下载与安装sklearn
sklearn是python的一个库,需要pip安装:
pip install sklearn
但是往往不能安装成功,因为sklearn依赖numpy和scipy,而大部分人的numpy都是pip直接安装但不完整版,所以一般会安装sicpy的时候会报错。
那么就有人想:我去官网下载whl文件再安装咯。可惜的是,墙内的官网下载普遍速度在10kb/s作用,往往还没下好就报错了。所以笔者这里给读者留下资源,提取码:sdwi(百度网盘再怎么丧心病狂也不至于10kb/s吧)
拿到安装包以后,把这两个文件放到自己电脑python目录的Scripts文件里面,就像这样:
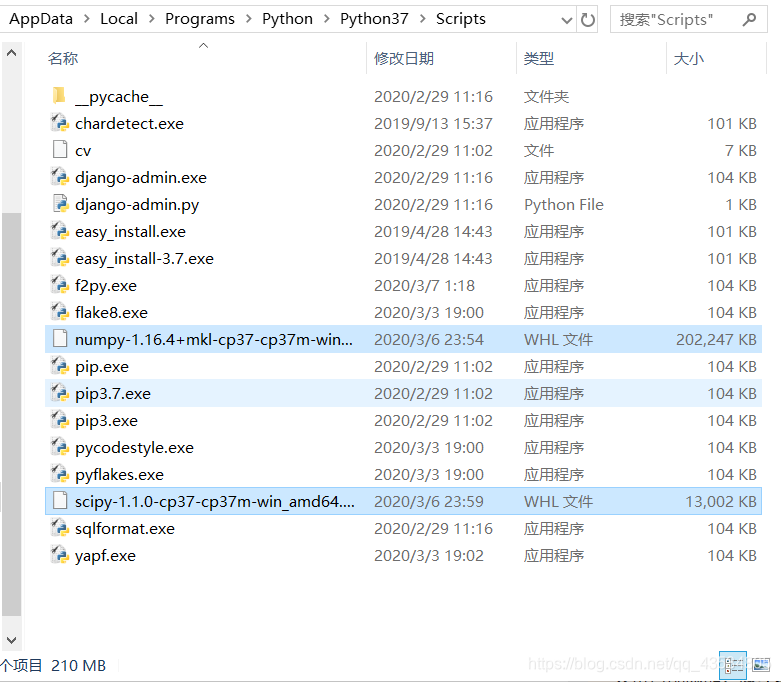 已经安装过numpy的朋友,请先卸载numpy:
已经安装过numpy的朋友,请先卸载numpy:pip uninstall numpy
然后打开cmd,一路cd到这个位置,然后:
pip install numpy-1.16.4+mkl-cp37-cp37m-win_amd64.whl
pip install scipy-1.1.0-cp37-cp37m-win_amd64.whl
具体哪个前面哪个后面我忘记了,有需要的可以试一下。
然后就可以pip install sklearn啦。
前期准备:数据集的下载
这篇文章介绍的是基于digits相关数据集的处理图像(手写字)和文本(新闻),所以最好提前下载数据集


- 下载新闻数据集
from sklearn.datasets import fetch_20newsgroups
# sample_cate 指定需要下载哪几个主题类别的新闻数据
sample_cate = ['alt.atheism', 'soc.religion.christian', 'comp.graphics', 'sci.med', 'rec.sport.baseball']
# 需要从网络上下载,受连接外网速度限制, 可能要耐心等待几分钟时间
newsgroups_train = fetch_20newsgroups(subset='train', categories=sample_cate, shuffle=True)
# 以上得到训练集,以下代码得到测试集
newsgroups_test = fetch_20newsgroups(subset='test', categories=sample_cate, shuffle=True)
把训练集放在newsgroups_train,测试集放在newsgroups_test。
手写字分类:
使用SVM,朴素贝叶斯,KNN, 使用Sklearn自带digits数据集训练识别手写体
该数据集是1797张8*8像素大小的灰度图,采用分类器进行手写体识别时,都是将每张图像看成64维的特征向量。
# The digits dataset
digits = datasets.load_digits()
print(digits.DESCR)
显示数字灰度图(需要import matplotlib.pyplot as plt)
#显示数据集中的第一个图像
plt.imshow(digits.images[0], cmap=plt.cm.gray_r, interpolation='nearest')
这个实验需要三个分类器,knn、svm、朴素贝叶斯,具体的介绍可以google,或者查看文末github库里面的word资源
接下来创建分类器:
# 创建svm分类器
svc_clf = svm.SVC(gamma=0.001)
# 创建KNN分类器
knn_clf = KNeighborsClassifier()
# 创建朴素贝叶斯分类器
nb_clf = MultinomialNB()
接下来划分数据集(news里面就不需要了,因为我们下载数据集的时候以及分好了)
# Split data into train and test subsets
# 使用train_test_split将数据集分为训练集,测试集, y_train 表示训练集中样本的类别标签, y_test表示测试集中样本的类别标签
# test_size = 0.5 表示使用一半数据进行测试, 另一半就用于训练
X_train, X_test, y_train, y_test = train_test_split(
data, digits.target, test_size=0.5, shuffle=False)
使用fit进行训练:
# 调用fit方法进行训练,传入训练集样本和样本的类别标签,进行有监督学习
svc_clf.fit(X_train, y_train)
knn_clf.fit(X_train, y_train)
nb_clf.fit(X_train, y_train)
进行预测:`
# 调用predict, 用训练得到的模型在测试集进行类别预测,得到预测的类别标签
svc_predicted = svc_clf.predict(X_test)
knn_predicted = knn_clf.predict(X_test)
nb_predicted = nb_clf.predict(X_test)`
然后开始输出:
svc_images_and_predictions = list(zip(digits.images[n_samples // 2:], svc_predicted))
knn_images_and_predictions = list(zip(digits.images[n_samples // 2:], knn_predicted))
nb_images_and_predictions = list(zip(digits.images[n_samples // 2:], nb_predicted))
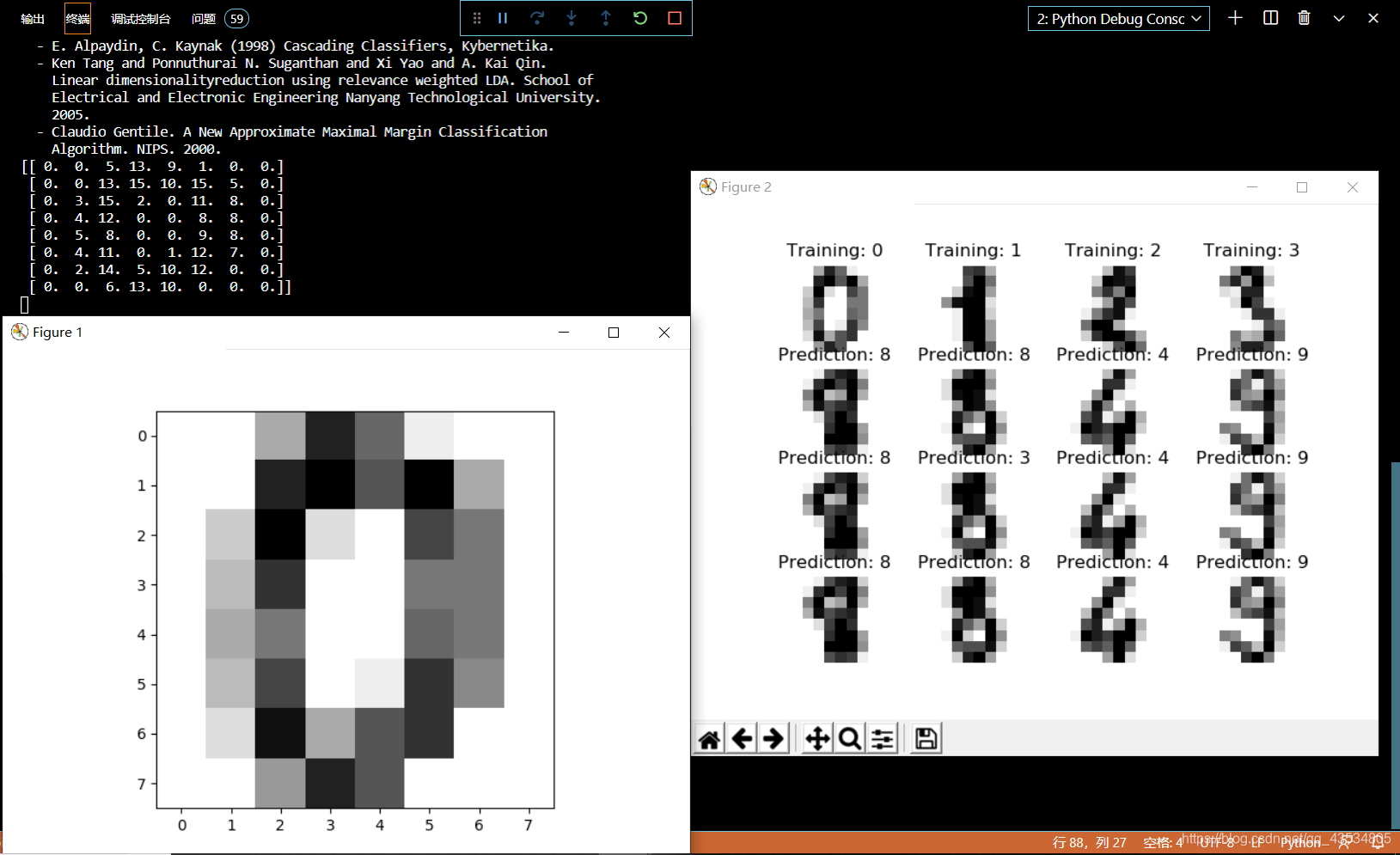
# 在图表的第二行输出svm在测试集的前四个手写体图像上的分类结果,大家可以在图上看看结果对不对
for ax, (image, svc_prediction) in zip(axes[1, :], svc_images_and_predictions[:4]):
ax.set_axis_off()
ax.imshow(image, cmap=plt.cm.gray_r, interpolation='nearest')
ax.set_title('Prediction: %i' % svc_prediction)
# 在图表的第三行输出KNN在测试集的前四个手写体图像上的分类结果,大家可以在图上看看结果对不对
# 大家应该可以发现KNN把第二列的8这个手写数字识别为3,发生错误
for ax, (image, knn_prediction) in zip(axes[2, :], knn_images_and_predictions[:4]):
ax.set_axis_off()
ax.imshow(image, cmap=plt.cm.gray_r, interpolation='nearest')
ax.set_title('Prediction: %i' % knn_prediction)
# 在图表的第四行输出朴素贝叶斯在测试集的前四个手写体图像上的分类结果,大家可以在图上看看结果对不对
for ax, (image, nb_prediction) in zip(axes[3, :], nb_images_and_predictions[:4]):
ax.set_axis_off()
ax.imshow(image, cmap=plt.cm.gray_r, interpolation='nearest')
ax.set_title('Prediction: %i' % nb_prediction)
# 绘制出图
plt.show()
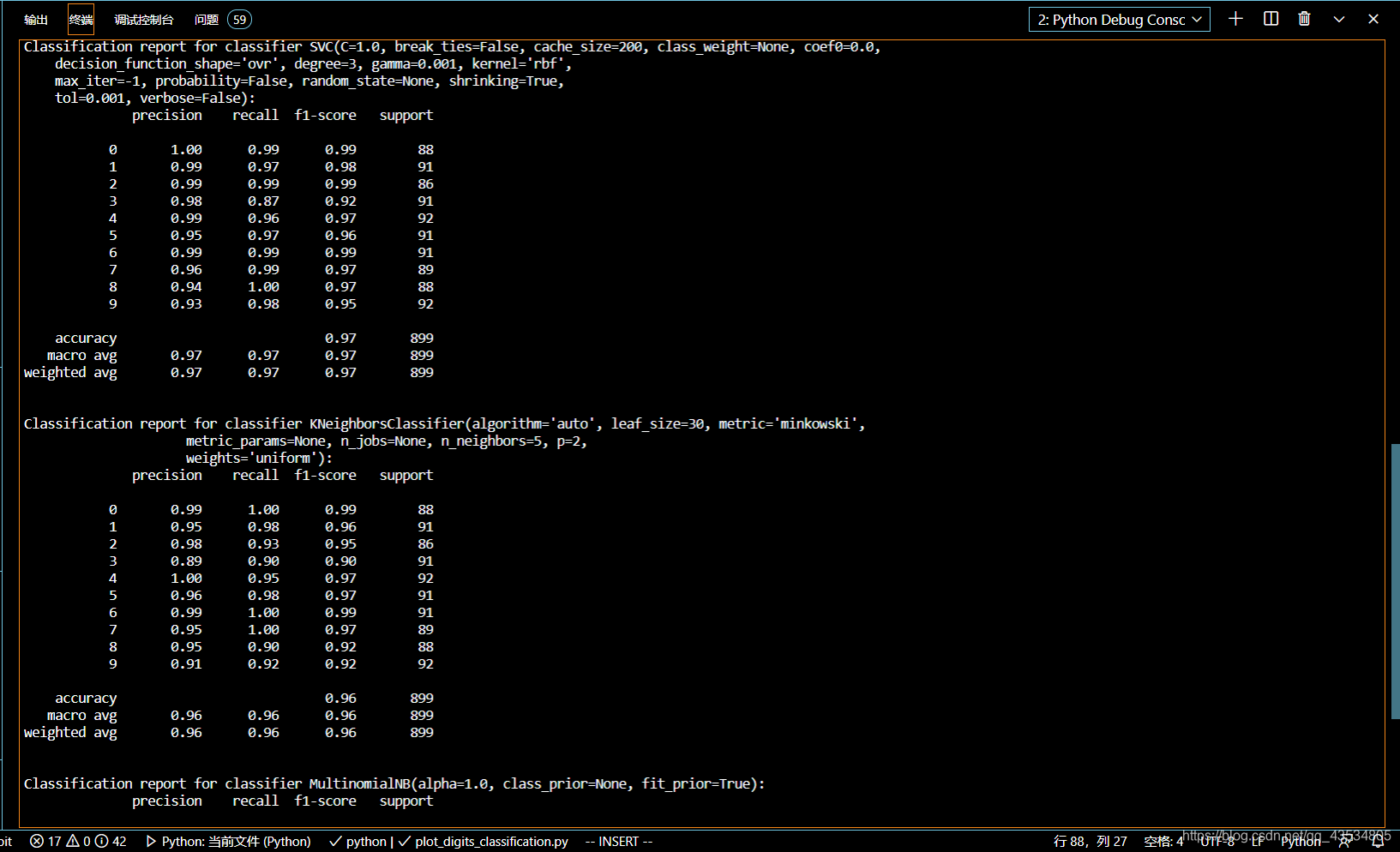
输出性能指标:
# 输出三个分类器的性能指标,大家需要了解二分类、多分类的性能评估指标主要有哪些
# 输出svm的分类性能指标
print("Classification report for classifier %s:\n%s\n"
% (svc_clf, metrics.classification_report(y_test, svc_predicted)))
# 输出KNN的分类性能指标
print("Classification report for classifier %s:\n%s\n"
% (knn_clf, metrics.classification_report(y_test, knn_predicted)))
# 输出naive bayes的分类性能指标
print("Classification report for classifier %s:\n%s\n"
% (nb_clf, metrics.classification_report(y_test, nb_predicted)))
手写字分类总体代码:github链接
运行结果:
新闻文本分类
对文本的分来较图像更为简单,因为不需要进行矩阵处理。
过程和手写字处理差不多,fit之后进行预测,然后输出性能指标
from sklearn.datasets import fetch_20newsgroups
# sample_cate 指定需要下载哪几个主题类别的新闻数据
sample_cate = ['alt.atheism', 'soc.religion.christian', 'comp.graphics', 'sci.med', 'rec.sport.baseball']
# 需要从网络上下载,受连接外网速度限制, 可能要耐心等待几分钟时间
newsgroups_train = fetch_20newsgroups(subset='train', categories=sample_cate, shuffle=True)
# 以上得到训练集,以下代码得到测试集
newsgroups_test = fetch_20newsgroups(subset='test', categories=sample_cate, shuffle=True)
print(len(newsgroups_train.data))
print(len(newsgroups_test.data))
import matplotlib.pyplot as plt
from sklearn import datasets, svm, metrics
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split
from sklearn.naive_bayes import MultinomialNB
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.feature_extraction.text import TfidfVectorizer
count_vectorizer = CountVectorizer(stop_words='english')
cv_news_train_vector = count_vectorizer.fit_transform(newsgroups_train.data)
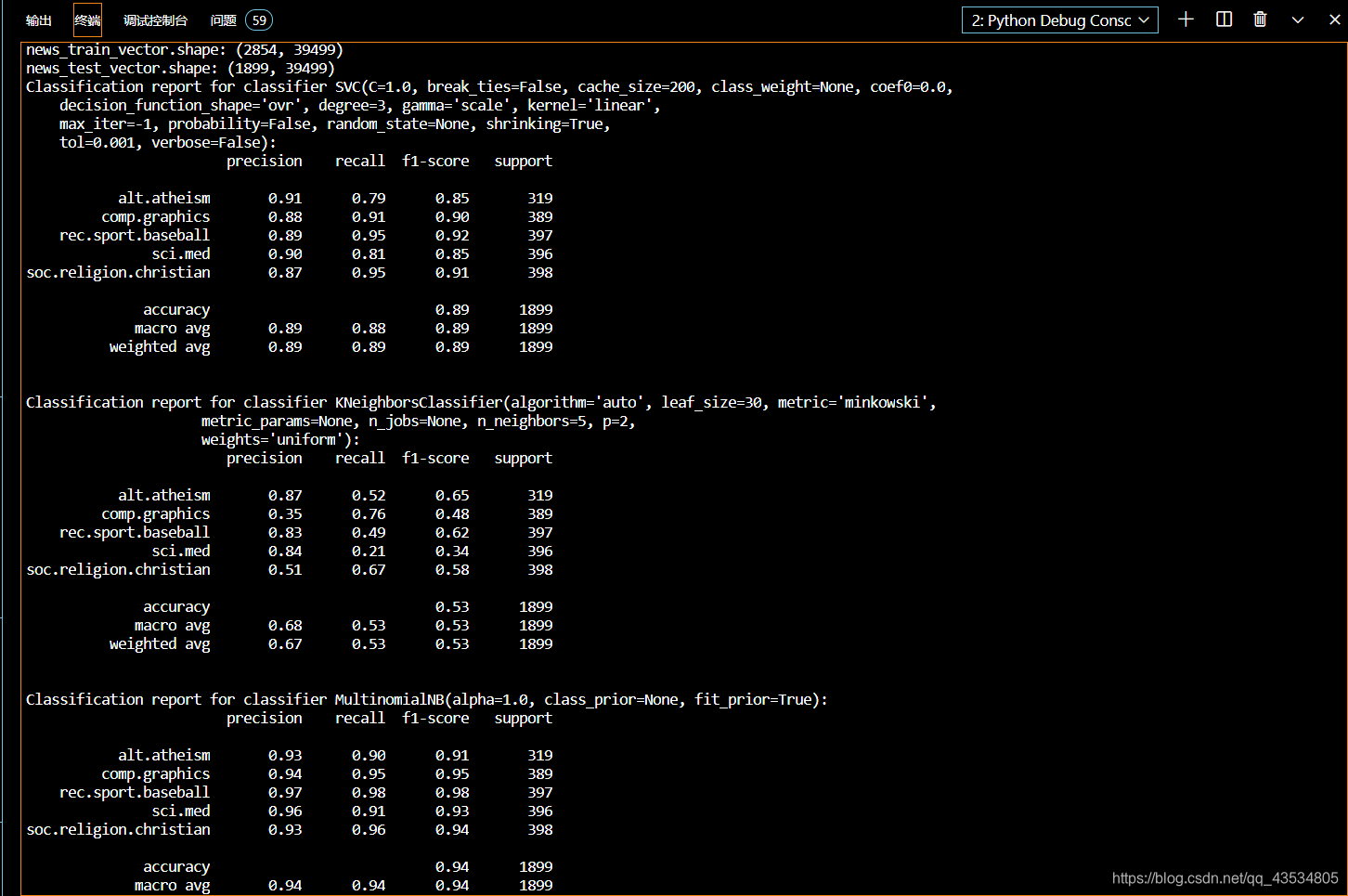
print("news_train_vector.shape:",cv_news_train_vector.shape)
cv_news_test_vector = count_vectorizer.transform(newsgroups_test.data)
print("news_test_vector.shape:",cv_news_test_vector.shape)
svc_clf = svm.SVC(kernel="linear")
svc_clf.fit(cv_news_train_vector,newsgroups_train.target)
cv_svc_predict = svc_clf.predict(cv_news_test_vector)
print("Classification report for classifier %s:\n%s\n" % (svc_clf,metrics.classification_report(newsgroups_test.target,cv_svc_predict,target_names=newsgroups_test.target_names)))
knn_clf = KNeighborsClassifier()
knn_clf.fit(cv_news_train_vector,newsgroups_train.target)
cv_knn_predict = knn_clf.predict(cv_news_test_vector)
print("Classification report for classifier %s:\n%s\n" % (knn_clf,metrics.classification_report(newsgroups_test.target,cv_knn_predict,target_names=newsgroups_test.target_names)))
nb_clf = MultinomialNB()
nb_clf.fit(cv_news_train_vector,newsgroups_train.target)
cv_nb_predict = nb_clf.predict(cv_news_test_vector)
print("Classification report for classifier %s:\n%s\n" % (nb_clf,metrics.classification_report(newsgroups_test.target,cv_nb_predict,target_names=newsgroups_test.target_names)))
###################################################################
tfidf_vectorizer = TfidfVectorizer(stop_words='english')
tfidf_news_train_vector = tfidf_vectorizer.fit_transform(newsgroups_train.data)
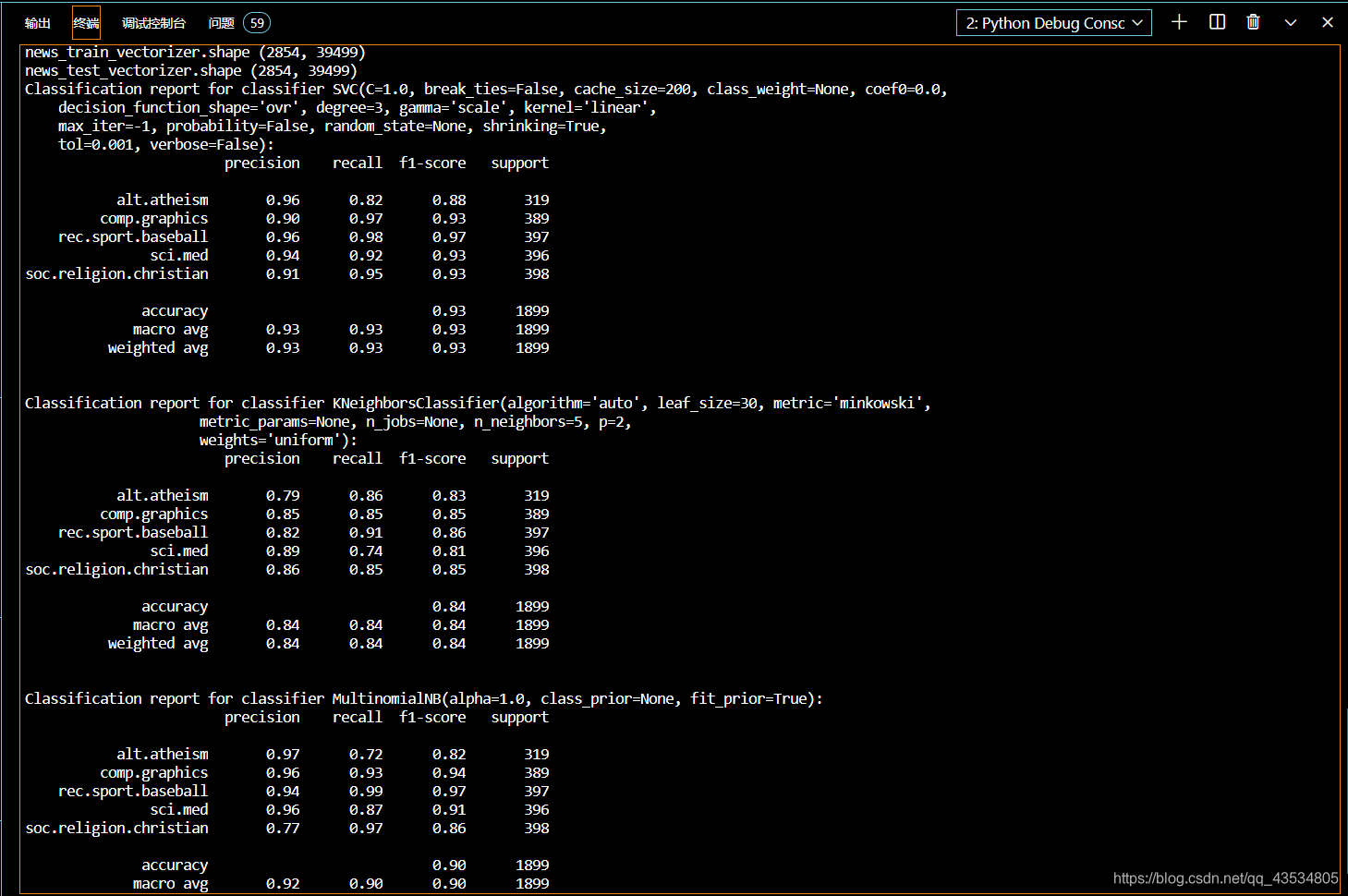
print("news_train_vectorizer.shape",tfidf_news_train_vector.shape)
tfidf_news_test_vector = tfidf_vectorizer.transform(newsgroups_test.data)
print("news_test_vectorizer.shape",tfidf_news_train_vector.shape)
svc_clf2 = svm.SVC(kernel="linear")
svc_clf2.fit(tfidf_news_train_vector,newsgroups_train.target)
tfidf_svc_predict2 = svc_clf2.predict(tfidf_news_test_vector)
print("Classification report for classifier %s:\n%s\n" % (svc_clf2,metrics.classification_report(newsgroups_test.target,tfidf_svc_predict2,target_names=newsgroups_test.target_names)))
knn_clf = KNeighborsClassifier()
knn_clf.fit(tfidf_news_train_vector,newsgroups_train.target)
tfidf_knn_predict = knn_clf.predict(tfidf_news_test_vector)
print("Classification report for classifier %s:\n%s\n" % (knn_clf,metrics.classification_report(newsgroups_test.target,tfidf_knn_predict,target_names=newsgroups_test.target_names)))
nb_clf = MultinomialNB()
nb_clf.fit(tfidf_news_train_vector,newsgroups_train.target)
tfidf_nb_predict = nb_clf.predict(tfidf_news_test_vector)
print("Classification report for classifier %s:\n%s\n" % (nb_clf,metrics.classification_report(newsgroups_test.target,tfidf_nb_predict,target_names=newsgroups_test.target_names)))
©
运行结果: