1 数据集
特征:数据集的列
样本:数据集的行
特征或属性空间:特征组成的空间
特征或属性向量:特征或属性空间中的点
训练集:用来训练模型的数据,使用训练集+算法构成模型解决实际问题
测试集:用来测试模型效果的数据。训练集与测试集的数据比例通常有6:4,7:3,8:2
2 非数值型特征的转换
label encoding 标签编码
onehot encoding 独热编码
3 性能矩阵(混淆矩阵)
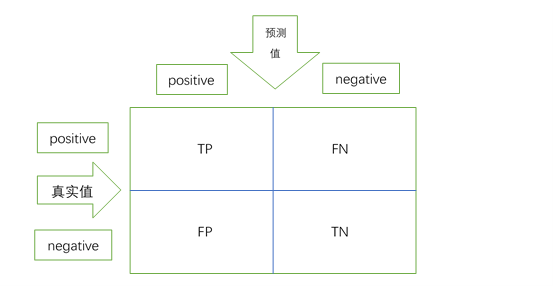
准确率:(TP+TN)/(TP+TN+FP+FN)
精确率:TP/(TP+FP)
真正率(召回率)TPR:TP/(TP+FN)
假正率FPR:FP/(FP+TN)
F1-score(F1值):2/(1/TPR+1/FPR)
4 机器学习处理问题框架
将数据集分为训练集和测试集
根据训练集训练模型
通过测试集测试模型,给出评价指标
5 机器学习分类
监督学习和非监督学习的区别在于是否有类别标签。
监督学习:
分类:标签为离散值
回归:标签为连续值
非监督学习:
聚类:通过特征之间的相似性
降维:通过机器学习算法达到降维的目的,区别于特征选择
半监督学习:
主动学习:专家给无标签数据贴标签
纯半监督学习/直推学习:将有标签特征数据和无标签特征数据放在一起,根据聚类的方式对数据进行分类,在同一类中,根据少数服从多数的原则,将无标签数据对应到多数标签。
强化学习:
主要用来解决连续决策的问题,好的表现对应正奖励,差的表现对应负奖励。
迁移学习:
小数据问题:两个关联领域,一个数据多,一个数据少,则可以在数据多的领域建立模型,用于数据少的领域。
个性化问题
6 机器学习三要素
机器学习=数据+算法+策略
机器学习=模型+算法+策略
算法:提供求解参数的方法,有解析法,数值法
策略:损失函数,损失函数越小越好,也就是损失函数的期望越小越好,期望p(x,y)不好求解,采用经验风险最小化替代。在经验风险上增加正则罚项,便是结构风险。
模型:决策函数(输出0或1),条件概率函数(按照条件进行输出)
7 如何设计机器学习系统
首先明确:
该问题是不是机器学习问题?
该问题是机器学习中的哪一类问题?监督学习、非监督学习
拿到数据后从两个方面思考问题:
从数据角度,该问题使用监督学习还是非监督学习
从业务角度,整理数据,建模
特征工程:
对特征的处理
对数据的处理
数据+选择的算法—模型
通过测试集测试模型,给定最终参数
如果有新数据,则进行预测
8 模型泛化能力
| 类别 |
欠拟合 |
过拟合 |
| 特点 |
在训练集和测试集上表现都不好 |
在训练集上表现很好,在测试集上表现不好 |
| 原因 |
1 模型过于简单 |
1 模型过于复杂 2 数据不纯 3 数据量太少 |
| 出现时间 |
训练前期 |
训练中后期 |
| 如何处理 |
1 增加多项式中的项 2 增加多项式中项的次数 3 减少正则罚项 |
1 针对模型复杂的特点,增加正则罚项 2 重新清洗数据 3 增加数据量 4 样本抽样或特征抽样 5 dropout-随机丢弃一些点 |
9 奥卡姆剃刀原则
两个泛化能力相当的模型,选择模型比较简单的那一个使用。
10 正则化
L1正则:+lambda*|w|
L2正则:+lambda*|w|^^2
11 交叉验证
简单交叉验证:将数据集切分为6:4,7:3,8:2
K则交叉验证:将数据分成k等分,将其中一份作为测试集,其余作为训练集,训练K个模型,得到平均准确率
留一验证:特殊的K则交叉验证