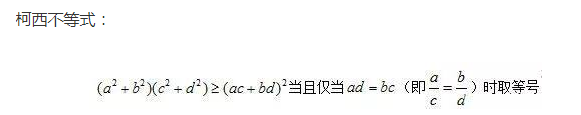无约束优化问题是机器学习中最普遍、简单的优化问题。
x
∗
=
m
i
n
x
f
(
x
)
,
x
∈
R
n
x^{*}=\underset{x}{min}f(x),x\in \mathbb{R}^n
x ∗ = x m i n f ( x ) , x ∈ R n
最常见的是梯度下降法,eg:
f
(
x
,
y
)
=
x
2
+
y
2
f(x,y) = x^2+y^2
f ( x , y ) = x 2 + y 2
P
P
P
L
L
L
P
′
{P}'
P ′
我们先定义单位长度的变化量为:
f
(
x
0
+
L
c
o
s
θ
,
y
0
+
L
s
i
n
θ
)
−
f
(
x
0
,
y
0
)
L
\frac{f(x_0+Lcos\theta, y_0+Lsin\theta) - f(x_0,y_0)}{L}
L f ( x 0 + L c o s θ , y 0 + L s i n θ ) − f ( x 0 , y 0 )
化简一下,当 L 非常小,趋于 0 的时候:
=
lim
L
→
0
f
(
x
0
+
L
c
o
s
θ
,
y
0
+
L
s
i
n
θ
)
−
f
(
x
0
+
L
c
o
s
θ
,
y
0
)
L
+
lim
L
→
0
f
(
x
0
+
L
c
o
s
θ
,
y
0
)
−
f
(
x
0
,
y
0
)
L
=
lim
L
→
0
s
i
n
θ
f
(
x
0
+
L
c
o
s
θ
,
y
0
+
L
s
i
n
θ
)
−
f
(
x
0
+
L
c
o
s
θ
,
y
0
)
L
s
i
n
θ
+
lim
L
→
0
c
o
s
θ
f
(
x
0
+
L
c
o
s
θ
,
y
0
)
−
f
(
x
0
,
y
0
)
L
c
o
s
θ
=
s
i
n
θ
f
y
′
(
x
0
+
L
c
o
s
θ
,
y
0
)
+
c
o
s
θ
f
x
′
(
x
0
,
y
0
)
(
当
L
趋
于
0
时
)
=
s
i
n
θ
f
y
′
(
x
0
,
y
0
)
+
c
o
s
θ
f
x
′
(
x
0
,
y
0
)
\begin{aligned} &= \lim_{L \to 0}\frac{f(x_0+Lcos\theta, y_0+Lsin\theta) - f(x_0 + Lcos\theta,y_0)}{L} + \lim_{L \to 0}\frac{ f(x_0 + Lcos\theta,y_0) - f(x_0,y_0)}{L}\\ & = \lim_{L \to 0}sin\theta\frac{f(x_0+Lcos\theta, y_0+Lsin\theta) - f(x_0 + Lcos\theta,y_0)}{Lsin\theta} + \lim_{L \to 0}cos\theta\frac{ f(x_0 + Lcos\theta,y_0) - f(x_0,y_0)}{Lcos\theta}\\ & = sin\theta {f_y}'(x_0+Lcos\theta,y_0) +cos\theta {f_x}'(x_0,y_0)(当 L 趋于 0 时) \\ & = sin\theta {f_y}'(x_0,y_0) +cos\theta {f_x}'(x_0,y_0) \end{aligned}
= L → 0 lim L f ( x 0 + L c o s θ , y 0 + L s i n θ ) − f ( x 0 + L c o s θ , y 0 ) + L → 0 lim L f ( x 0 + L c o s θ , y 0 ) − f ( x 0 , y 0 ) = L → 0 lim s i n θ L s i n θ f ( x 0 + L c o s θ , y 0 + L s i n θ ) − f ( x 0 + L c o s θ , y 0 ) + L → 0 lim c o s θ L c o s θ f ( x 0 + L c o s θ , y 0 ) − f ( x 0 , y 0 ) = s i n θ f y ′ ( x 0 + L c o s θ , y 0 ) + c o s θ f x ′ ( x 0 , y 0 ) ( 当 L 趋 于 0 时 ) = s i n θ f y ′ ( x 0 , y 0 ) + c o s θ f x ′ ( x 0 , y 0 )
问题转化为当
θ
\theta
θ
向量内积
m
⋅
n
=
∣
m
∣
∣
n
∣
c
o
s
θ
m \cdot n = |m||n|cos\theta
m ⋅ n = ∣ m ∣ ∣ n ∣ c o s θ
平方一下
(
m
⋅
n
)
2
=
∣
m
∣
2
∣
n
∣
2
c
o
s
2
θ
≤
∣
m
∣
2
∣
n
∣
2
(m \cdot n)^2 = |m|^2|n|^2cos^2\theta \leq |m|^2|n|^2
( m ⋅ n ) 2 = ∣ m ∣ 2 ∣ n ∣ 2 c o s 2 θ ≤ ∣ m ∣ 2 ∣ n ∣ 2
哈哈哈,这就是柯西不等式,m为 (a,b),n为 (c,d)!
如果向量 m 为
(
c
o
s
θ
,
s
i
n
θ
)
(cos\theta,sin\theta)
( c o s θ , s i n θ )
(
f
x
′
(
x
0
,
y
0
)
,
f
y
′
(
x
0
,
y
0
)
)
({f_x}'(x_0,y_0),{f_y}'(x_0,y_0))
( f x ′ ( x 0 , y 0 ) , f y ′ ( x 0 , y 0 ) )
[
c
o
s
θ
f
x
′
(
x
0
,
y
0
)
+
s
i
n
θ
f
y
′
(
x
0
,
y
0
)
]
2
≤
(
c
o
s
2
θ
+
s
i
n
2
θ
)
(
[
f
x
′
(
x
0
,
y
0
)
]
2
+
[
f
y
′
(
x
0
,
y
0
)
]
2
)
=
[
f
x
′
(
x
0
,
y
0
)
]
2
+
[
f
y
′
(
x
0
,
y
0
)
]
2
[cos\theta {f_x}'(x_0,y_0)+sin\theta {f_y}'(x_0,y_0) ]^2 \leq (cos^2\theta + sin^2\theta)([{f_x}'(x_0,y_0)]^2+[{f_y}'(x_0,y_0)]^2) = [{f_x}'(x_0,y_0)]^2+[{f_y}'(x_0,y_0)]^2
[ c o s θ f x ′ ( x 0 , y 0 ) + s i n θ f y ′ ( x 0 , y 0 ) ] 2 ≤ ( c o s 2 θ + s i n 2 θ ) ( [ f x ′ ( x 0 , y 0 ) ] 2 + [ f y ′ ( x 0 , y 0 ) ] 2 ) = [ f x ′ ( x 0 , y 0 ) ] 2 + [ f y ′ ( x 0 , y 0 ) ] 2
等号成立的条件就是两个向量的夹角为 0,也就是平行,也就是
c
o
s
θ
f
x
′
(
x
0
,
y
0
)
=
s
i
n
θ
f
y
′
(
x
0
,
y
0
)
\frac{cos\theta}{{f_x}'(x_0,y_0)} = \frac{sin\theta}{{f_y}'(x_0,y_0)}
f x ′ ( x 0 , y 0 ) c o s θ = f y ′ ( x 0 , y 0 ) s i n θ
也就是
c
o
s
θ
s
i
n
θ
=
f
x
′
(
x
0
,
y
0
)
f
y
′
(
x
0
,
y
0
)
\frac{cos\theta}{sin\theta} = \frac{{f_x}'(x_0,y_0)}{{f_y}'(x_0,y_0)}
s i n θ c o s θ = f y ′ ( x 0 , y 0 ) f x ′ ( x 0 , y 0 )
也即使单位长度的增长量最大的方向
θ
\theta
θ
a
r
c
t
a
n
f
y
′
(
x
0
,
y
0
)
f
x
′
(
x
0
,
y
0
)
arctan\frac{{f_y}'(x_0,y_0)}{{f_x}'(x_0,y_0)}
a r c t a n f x ′ ( x 0 , y 0 ) f y ′ ( x 0 , y 0 )
上面是我们从任一点出发,推导出来的函数值上升最大的方向!下面我们来看看梯度的定义:
设函数
f
(
x
,
y
)
f(x,y)
f ( x , y )
P
0
(
x
0
,
y
0
)
∈
D
P_0(x_0,y_0) \in D
P 0 ( x 0 , y 0 ) ∈ D
f
x
′
(
x
0
,
y
0
)
i
⃗
+
f
y
′
(
x
0
,
y
0
)
j
⃗
{f_x}'(x_0,y_0)\vec{i} + {f_y}'(x_0,y_0)\vec{j}
f x ′ ( x 0 , y 0 ) i
+ f y ′ ( x 0 , y 0 ) j
为函数
f
(
x
,
y
)
f(x,y)
f ( x , y )
P
0
(
x
0
,
y
0
)
P_0(x_0,y_0)
P 0 ( x 0 , y 0 )
g
r
a
d
⃗
f
(
x
0
,
y
0
)
\vec{grad}f(x_0,y_0)
g r a d
f ( x 0 , y 0 )
OK,可以看出,梯度向量的方向和我们之前推导的方向是一致的,所以梯度的方向就是函数增长最大的方向!
x
n
+
1
=
x
n
−
f
′
(
x
n
)
f
′
′
(
x
n
)
x_{n+1} = x_n-\frac{{f}'(x_n)}{{f}''(x_n)}
x n + 1 = x n − f ′ ′ ( x n ) f ′ ( x n )
解释一(导函数的切线迭代):
无约束的优化问题:
x
∗
=
m
i
n
x
f
(
x
)
,
x
∈
R
n
x^{*}=\underset{x}{min}f(x),x\in \mathbb{R}^n
x ∗ = x m i n f ( x ) , x ∈ R n
可以找极值点,令
f
′
(
x
)
=
0
{f}'(x) = 0
f ′ ( x ) = 0
x
x
x
g
=
f
′
(
x
)
g = {f}'(x)
g = f ′ ( x )
(
x
n
,
f
′
(
x
n
)
)
(x_n,{f}'(x_n))
( x n , f ′ ( x n ) )
y
−
f
′
(
x
n
)
=
f
′
′
(
x
n
)
(
x
−
x
n
)
y-{f}'(x_n) = {f}''(x_n)(x-x_n)
y − f ′ ( x n ) = f ′ ′ ( x n ) ( x − x n )
当直线方程中的
y
=
0
y = 0
y = 0
x
=
x
n
−
f
′
(
x
n
)
f
′
′
(
x
n
)
x = x_n-\frac{{f}'(x_n)}{{f}''(x_n)}
x = x n − f ′ ′ ( x n ) f ′ ( x n )
也即
x
n
+
1
=
x
n
−
f
′
(
x
n
)
f
′
′
(
x
n
)
x_{n+1} = x_n-\frac{{f}'(x_n)}{{f}''(x_n)}
x n + 1 = x n − f ′ ′ ( x n ) f ′ ( x n )
然后继续计算点
(
x
n
+
1
,
f
′
(
x
n
+
1
)
)
(x_{n+1},{f}'(x_{n+1}))
( x n + 1 , f ′ ( x n + 1 ) )
y
=
0
y = 0
y = 0
x
n
+
2
x_{n+2}
x n + 2
不断的迭代下去,如果
f
′
(
x
)
{f}'(x)
f ′ ( x )
<
1
0
−
5
<10^{-5}
< 1 0 − 5
解释二(用抛物线迭代):
x
n
x_n
x n
x
n
+
1
x_{n+1}
x n + 1
选择什么样的二次函数拟合比较合适呢?
下面先看看泰勒定理(任何可导函数,都可以写成幂函数的形式)
定义:设
f
(
x
)
f(x)
f ( x )
[
a
,
b
]
[a,b]
[ a , b ]
n
n
n
(
a
,
b
)
(a,b)
( a , b )
n
+
1
n+1
n + 1
x
0
∈
[
a
,
b
]
x_0 \in[a,b]
x 0 ∈ [ a , b ]
x
∈
[
a
,
b
]
x \in[a,b]
x ∈ [ a , b ]
ξ
\xi
ξ
x
0
x_0
x 0
x
x
x
f
(
x
)
=
f
(
x
0
)
+
f
′
(
x
0
)
1
!
(
x
−
x
0
)
+
f
′
′
(
x
0
)
2
!
(
x
−
x
0
)
2
+
.
.
.
+
f
(
n
)
(
x
0
)
n
!
(
x
−
x
0
)
n
+
R
(
n
)
f(x) = f(x_0)+\frac{{f}'(x_0)}{1!}(x-x_0)+\frac{{f}''(x_0)}{2!}(x-x_0)^2+...+\frac{{f}^{(n)}(x_0)}{n!}(x-x_0)^n+R(n)
f ( x ) = f ( x 0 ) + 1 ! f ′ ( x 0 ) ( x − x 0 ) + 2 ! f ′ ′ ( x 0 ) ( x − x 0 ) 2 + . . . + n ! f ( n ) ( x 0 ) ( x − x 0 ) n + R ( n )
其中
R
n
=
f
(
n
+
1
)
(
ξ
)
(
n
+
1
)
!
(
x
−
x
0
)
n
+
1
R_n = \frac{{f}^{(n+1)}(\xi)}{(n+1)!}(x-x_0)^{n+1}
R n = ( n + 1 ) ! f ( n + 1 ) ( ξ ) ( x − x 0 ) n + 1
n
n
n
回到我们的问题上来,
f
(
x
)
f(x)
f ( x )
f
(
x
)
=
f
(
x
n
)
+
f
′
(
x
n
)
1
!
(
x
−
x
n
)
+
f
′
′
(
x
n
)
2
!
(
x
−
x
n
)
2
+
.
.
.
=
f
′
′
(
x
n
)
2
!
x
2
+
[
f
′
(
x
n
)
−
f
′
′
(
x
n
)
2
!
2
x
n
]
x
+
f
(
x
n
)
−
f
′
(
x
n
)
x
n
+
f
′
′
(
x
n
)
2
!
x
n
2
.
.
.
=
f
′
′
(
x
n
)
2
!
x
2
+
[
f
′
(
x
n
)
−
f
′
′
(
x
n
)
x
n
]
x
+
f
(
x
n
)
−
f
′
(
x
n
)
x
n
+
f
′
′
(
x
n
)
2
!
x
n
2
.
.
.
\begin{aligned} f(x) &= f(x_n)+\frac{{f}'(x_n)}{1!}(x-x_n)+\frac{{f}''(x_n)}{2!}(x-x_n)^2+... \\ &=\frac{{f}''(x_n)}{2!}x^2+[{f}'(x_n)-\frac{{f}''(x_n)}{2!}2x_n]x+f(x_n)-{f}'(x_n)x_n+\frac{{f}''(x_n)}{2!}x_n^2...\\ &=\frac{{f}''(x_n)}{2!}x^2+[{f}'(x_n)-{f}''(x_n)x_n]x+f(x_n)-{f}'(x_n)x_n+\frac{{f}''(x_n)}{2!}x_n^2... \end{aligned}
f ( x ) = f ( x n ) + 1 ! f ′ ( x n ) ( x − x n ) + 2 ! f ′ ′ ( x n ) ( x − x n ) 2 + . . . = 2 ! f ′ ′ ( x n ) x 2 + [ f ′ ( x n ) − 2 ! f ′ ′ ( x n ) 2 x n ] x + f ( x n ) − f ′ ( x n ) x n + 2 ! f ′ ′ ( x n ) x n 2 . . . = 2 ! f ′ ′ ( x n ) x 2 + [ f ′ ( x n ) − f ′ ′ ( x n ) x n ] x + f ( x n ) − f ′ ( x n ) x n + 2 ! f ′ ′ ( x n ) x n 2 . . .
此时我们就可以用上面的抛物线来近似
f
(
x
)
f(x)
f ( x )
x
=
−
b
2
a
x =-\frac{b}{2a}
x = − 2 a b
a
a
a
b
b
b
x
=
−
f
′
(
x
n
)
−
f
′
′
(
x
n
)
x
n
2
×
f
′
′
(
x
n
)
2
!
=
f
′
′
(
x
n
)
x
n
−
f
′
(
x
n
)
f
′
′
(
x
n
)
=
x
n
−
f
′
(
x
n
)
f
′
′
(
x
n
)
\begin{aligned} x &= -\frac{{f}'(x_n)-{f}''(x_n)x_n}{2\times\frac{{f}''(x_n)}{2!}} \\ & = \frac{{f}''(x_n)x_n-{f}'(x_n)}{{f}''(x_n)} \\ & = x_n-\frac{{f}'(x_n)}{{f}''(x_n)} \\ \end{aligned}
x = − 2 × 2 ! f ′ ′ ( x n ) f ′ ( x n ) − f ′ ′ ( x n ) x n = f ′ ′ ( x n ) f ′ ′ ( x n ) x n − f ′ ( x n ) = x n − f ′ ′ ( x n ) f ′ ( x n )
x
n
+
1
=
x
n
−
f
′
(
x
n
)
f
′
′
(
x
n
)
x_{n+1} = x_n-\frac{{f}'(x_n)}{{f}''(x_n)}
x n + 1 = x n − f ′ ′ ( x n ) f ′ ( x n )
注意,如果
f
(
x
)
f(x)
f ( x )
x
∗
x^*
x ∗
上面
x
x
x
x
x
x
m
m
m
x
(
n
)
=
(
x
1
(
n
)
,
x
2
(
n
)
,
.
.
.
x
m
(
n
)
)
x^{(n)} = (x_1^{(n)},x_2^{(n)},...x_m^{(n)})
x ( n ) = ( x 1 ( n ) , x 2 ( n ) , . . . x m ( n ) )
▽
f
=
[
∂
f
∂
x
1
∂
f
∂
x
2
.
.
.
∂
f
∂
x
m
]
\bigtriangledown f = \begin{bmatrix} \frac{\partial f}{\partial x_1}\\ \frac{\partial f}{\partial x_2}\\ ...\\ \frac{\partial f}{\partial x_m} \end{bmatrix}
▽ f = ⎣ ⎢ ⎢ ⎢ ⎡ ∂ x 1 ∂ f ∂ x 2 ∂ f . . . ∂ x m ∂ f ⎦ ⎥ ⎥ ⎥ ⎤
为
f
f
f
g
g
g
▽
2
f
=
[
∂
2
f
∂
x
1
2
∂
2
f
∂
x
1
∂
x
2
.
.
.
∂
2
f
∂
x
1
∂
x
m
∂
2
f
∂
x
2
∂
x
1
∂
2
f
∂
x
2
2
.
.
.
∂
2
f
∂
x
2
∂
x
m
.
.
.
.
.
.
.
.
.
.
.
.
∂
2
f
∂
x
m
∂
x
1
∂
2
f
∂
x
m
∂
x
2
.
.
.
∂
2
f
∂
x
m
2
]
\bigtriangledown ^2f = \begin{bmatrix} \frac{\partial ^2f}{\partial x_1^2} & \frac{\partial ^2f}{\partial x_1 \partial x_2} & ... & \frac{\partial ^2f}{\partial x_1 \partial x_m}\\ \frac{\partial ^2f}{\partial x_2 \partial x_1} & \frac{\partial ^2f}{\partial x_2^2}& ... & \frac{\partial ^2f}{\partial x_2 \partial x_m}\\ ... & ... & ...& ...\\ \frac{\partial ^2f}{\partial x_m \partial x_1} & \frac{\partial ^2f}{\partial x_m \partial x_2} & ... & \frac{\partial ^2f}{\partial x_m^2} \end{bmatrix}
▽ 2 f = ⎣ ⎢ ⎢ ⎢ ⎢ ⎡ ∂ x 1 2 ∂ 2 f ∂ x 2 ∂ x 1 ∂ 2 f . . . ∂ x m ∂ x 1 ∂ 2 f ∂ x 1 ∂ x 2 ∂ 2 f ∂ x 2 2 ∂ 2 f . . . ∂ x m ∂ x 2 ∂ 2 f . . . . . . . . . . . . ∂ x 1 ∂ x m ∂ 2 f ∂ x 2 ∂ x m ∂ 2 f . . . ∂ x m 2 ∂ 2 f ⎦ ⎥ ⎥ ⎥ ⎥ ⎤
为 Hesse 矩阵,即为
H
H
H
所以,牛顿法可以表示成如下形式:
x
(
n
+
1
)
=
x
(
n
)
−
g
n
H
n
=
x
(
n
)
−
H
n
−
1
g
n
\begin{aligned} x^{(n+1)} &= x^{(n)}-\frac{g_n}{H_n}\\ & = x^{(n)}-H_n^{-1}g_n \end{aligned}
x ( n + 1 ) = x ( n ) − H n g n = x ( n ) − H n − 1 g n 牛顿法与拟牛顿法学习笔记(一)牛顿法
梯下降是一次收敛
∣
∣
x
n
+
1
−
x
∗
∣
∣
<
k
∣
∣
x
n
−
x
∗
∣
∣
,
k
∈
(
0
,
1
)
||x_{n+1}-x^*||<k||x_{n}-x^*||,k \in (0,1)
∣ ∣ x n + 1 − x ∗ ∣ ∣ < k ∣ ∣ x n − x ∗ ∣ ∣ , k ∈ ( 0 , 1 )
牛顿法二次收敛
∣
∣
x
n
+
1
−
x
∗
∣
∣
<
k
∣
∣
x
n
−
x
∗
∣
∣
2
,
k
∈
(
0
,
1
)
||x_{n+1}-x^*||<k||x_{n}-x^*||^2,k \in (0,1)
∣ ∣ x n + 1 − x ∗ ∣ ∣ < k ∣ ∣ x n − x ∗ ∣ ∣ 2 , k ∈ ( 0 , 1 )
速度快,但也有缺陷要在比较接近最优点的时候才能收敛,否则可发散,这一点很好的弥补了梯度下降法步长不好的时候在最优点的时候震荡的问题.
牛顿法与拟牛顿法学习笔记(一)牛顿法
设置了步长
λ
\lambda
λ
d
k
d_k
d k
λ
k
=
a
r
g
m
i
n
λ
∈
R
f
(
x
k
+
λ
k
d
k
)
\lambda_k = arg \underset{\lambda \in \mathbb{R}}{min}f(x_k+\lambda_k d_k)
λ k = a r g λ ∈ R m i n f ( x k + λ k d k )
参考 牛顿法与拟牛顿法学习笔记(二)拟牛顿条件
Hesse 矩阵可能没有逆,也可能比较难求,拟牛顿法 提出,用不含二阶导数的矩阵
U
k
U_k
U k
H
k
−
1
H_k^{-1}
H k − 1
−
U
k
g
k
-U_kg_k
− U k g k
U
k
U_k
U k
常见的拟牛顿法有
但是不能随便近似,需要理论的指导,拟牛顿条件 就是近似需要满足的条件。
迭代
k
+
1
k+1
k + 1
x
k
+
1
x_{k+1}
x k + 1
f
(
x
)
f(x)
f ( x )
x
k
+
1
x_{k+1}
x k + 1
f
(
x
)
≈
f
(
x
k
+
1
)
+
▽
f
(
x
k
+
1
)
1
!
(
x
−
x
k
+
1
)
+
▽
2
f
(
x
k
+
1
)
2
!
(
x
−
x
k
+
1
)
2
f(x) \approx f(x_{k+1})+\frac{\bigtriangledown f(x_{k+1})}{1!}(x-x_{k+1})+\frac{\bigtriangledown ^2f(x_{k+1})}{2!}(x-x_{k+1})^2
f ( x ) ≈ f ( x k + 1 ) + 1 ! ▽ f ( x k + 1 ) ( x − x k + 1 ) + 2 ! ▽ 2 f ( x k + 1 ) ( x − x k + 1 ) 2
两边同时求梯度:
▽
f
(
x
)
≈
▽
f
(
x
k
+
1
)
+
▽
2
f
(
x
k
+
1
)
1
!
(
x
−
x
k
+
1
)
\bigtriangledown f(x) \approx \bigtriangledown f(x_{k+1})+\frac{\bigtriangledown ^2f(x_{k+1})}{1!}(x-x_{k+1})
▽ f ( x ) ≈ ▽ f ( x k + 1 ) + 1 ! ▽ 2 f ( x k + 1 ) ( x − x k + 1 )
也即
▽
f
(
x
)
≈
g
k
+
1
+
H
k
+
1
(
x
−
x
k
+
1
)
\bigtriangledown f(x) \approx g_{k+1}+H_{k+1}(x-x_{k+1})
▽ f ( x ) ≈ g k + 1 + H k + 1 ( x − x k + 1 )
令
x
x
x
x
k
x_k
x k
g
k
≈
g
k
+
1
+
H
k
+
1
(
x
k
−
x
k
+
1
)
g_k \approx g_{k+1}+H_{k+1}(x_k-x_{k+1})
g k ≈ g k + 1 + H k + 1 ( x k − x k + 1 )
g
k
−
g
k
+
1
≈
H
k
+
1
(
x
k
−
x
k
+
1
)
g_k - g_{k+1} \approx H_{k+1}(x_k-x_{k+1})
g k − g k + 1 ≈ H k + 1 ( x k − x k + 1 )
或者
x
k
−
x
k
+
1
≈
H
k
+
1
−
1
(
g
k
−
g
k
+
1
)
x_k-x_{k+1}\approx H_{k+1}^{-1}(g_k - g_{k+1} )
x k − x k + 1 ≈ H k + 1 − 1 ( g k − g k + 1 )
对 Hesse 矩阵做了约束,这就是拟牛顿条件
我们令
B
≈
H
B \approx H
B ≈ H
D
≈
H
−
1
D \approx H^{-1}
D ≈ H − 1
s
k
=
x
k
+
1
−
x
k
s_k = x_{k+1}-x_k
s k = x k + 1 − x k
y
k
=
g
k
+
1
−
g
k
y_k = g_{k+1}-g_k
y k = g k + 1 − g k 拟牛顿条件 可以简化表示为
y
k
≈
B
k
+
1
⋅
s
k
y_k \approx B_{k+1}\cdot s_k
y k ≈ B k + 1 ⋅ s k
或者
s
k
≈
D
k
+
1
⋅
y
k
s_k \approx D_{k+1}\cdot y_k
s k ≈ D k + 1 ⋅ y k
x
∗
=
m
i
n
x
f
(
x
)
,
x
∈
R
n
s
.
t
.
g
(
x
)
=
0
x^{*}=\underset{x}{min}f(x),x\in \mathbb{R}^n \\ s.t. g(x)=0
x ∗ = x m i n f ( x ) , x ∈ R n s . t . g ( x ) = 0
以二维为例子
f
(
x
,
y
)
f(x,y)
f ( x , y )
g
(
x
,
y
)
=
0
g(x,y)=0
g ( x , y ) = 0 最优的点一定是
g
(
x
,
y
)
g(x,y)
g ( x , y )
f
(
x
,
y
)
f(x,y)
f ( x , y )
如果相交,
f
(
x
,
y
)
=
d
f(x,y)=d
f ( x , y ) = d
g
(
x
,
y
)
=
0
g(x,y)=0
g ( x , y ) = 0
(
x
,
y
)
(x,y)
( x , y )
g
(
x
,
y
)
=
0
g(x,y)=0
g ( x , y ) = 0
f
(
x
,
y
)
≤
d
f(x,y)\leq d
f ( x , y ) ≤ d
f
(
x
,
y
)
=
d
2
f(x,y)=d_2
f ( x , y ) = d 2
g
(
x
,
y
)
=
0
g(x,y)=0
g ( x , y ) = 0
此时呢
{
▽
f
(
x
,
y
)
=
−
λ
▽
g
(
x
,
y
)
g
(
x
,
y
)
=
0
\left\{\begin{matrix} \bigtriangledown f(x,y) = -\lambda \bigtriangledown g(x,y) \\ g(x,y) = 0 \end{matrix}\right.
{ ▽ f ( x , y ) = − λ ▽ g ( x , y ) g ( x , y ) = 0
整合一下:
L
(
x
,
y
,
λ
)
=
f
(
x
,
y
)
+
λ
g
(
x
,
y
)
L(x,y,\lambda) = f(x,y) + \lambda g(x,y)
L ( x , y , λ ) = f ( x , y ) + λ g ( x , y )
这就是耳熟能详的拉格朗日函数 !你会发现,两边同时求梯度,令梯度为 0,对
λ
\lambda
λ
我们再回过头去看看拉格朗日乘数法
求函数
f
(
x
,
y
)
f(x,y)
f ( x , y )
g
(
x
,
y
)
=
0
g(x,y)=0
g ( x , y ) = 0
解决此类问题的一般方法是拉格朗日乘数法:
L
(
x
,
y
,
λ
)
=
f
(
x
,
y
)
+
λ
g
(
x
,
y
)
L(x,y,\lambda) = f(x,y) + \lambda g(x,y)
L ( x , y , λ ) = f ( x , y ) + λ g ( x , y )
{
∂
L
∂
x
=
∂
f
∂
x
+
λ
∂
g
∂
x
=
0
,
∂
L
∂
y
=
∂
f
∂
y
+
λ
∂
g
∂
y
=
0
,
∂
L
∂
λ
=
g
(
x
,
y
)
=
0
,
\left\{\begin{matrix} \frac{\partial L}{\partial x} = \frac{\partial f}{\partial x}+ \lambda \frac{\partial g}{\partial x} = 0,\\ \frac{\partial L}{\partial y} = \frac{\partial f}{\partial y}+ \lambda \frac{\partial g}{\partial y} = 0,\\ \frac{\partial L}{\partial \lambda} = g(x,y)=0, \end{matrix}\right.
⎩ ⎨ ⎧ ∂ x ∂ L = ∂ x ∂ f + λ ∂ x ∂ g = 0 , ∂ y ∂ L = ∂ y ∂ f + λ ∂ y ∂ g = 0 , ∂ λ ∂ L = g ( x , y ) = 0 ,
所有满足此方程组的解
(
x
,
y
,
λ
)
(x,y,\lambda)
( x , y , λ )
(
x
,
y
)
(x,y)
( x , y )
f
(
x
,
y
)
f(x,y)
f ( x , y )
g
(
x
,
y
)
=
0
g(x,y)=0
g ( x , y ) = 0
和我们推导出来的没有差异(梯度就是偏导的构成的向量) ,哈哈,只是我们使用的时候和推导的逻辑是反过来,
推导的时候,先有求偏导的形式,然后才构造出来拉格朗日函数,
f
(
x
,
y
)
f(x,y)
f ( x , y )
f
(
x
,
y
)
f(x,y)
f ( x , y )
g
(
x
,
y
)
=
0
g(x,y) = 0
g ( x , y ) = 0
整合一下
{
L
(
x
,
y
,
μ
)
=
f
(
x
,
y
)
+
μ
g
(
x
,
y
)
μ
≥
0
μ
g
(
x
∗
,
y
∗
)
=
0
\left\{\begin{matrix} L(x,y,\mu) = f(x,y) + \mu g(x,y)\\ \mu \geq 0\\ \mu g(x^*,y^*) = 0 \end{matrix}\right.
⎩ ⎨ ⎧ L ( x , y , μ ) = f ( x , y ) + μ g ( x , y ) μ ≥ 0 μ g ( x ∗ , y ∗ ) = 0
当
μ
=
0
\mu = 0
μ = 0
g
(
x
,
y
)
≤
0
g(x,y) \leq 0
g ( x , y ) ≤ 0
当
μ
≥
0
\mu\geq 0
μ ≥ 0
g
(
x
,
y
)
=
0
g(x,y) =0
g ( x , y ) = 0
下面加上等式和不等式约束,看看完整的 KKT 条件的定义
非线性优化中的 KKT 条件该如何理解? - 马同学的回答 - 知乎
我们也可以换一个角度来分析 KKT 条件
广义 Lagrangian 可以定义为:
L
(
x
,
λ
,
μ
)
=
f
(
x
)
+
∑
i
λ
i
g
(
i
)
(
x
)
+
∑
j
μ
j
h
(
j
)
(
x
)
L(x,\lambda,\mu) =f(x) + \sum_i\lambda_ig^{(i)}(x) + \sum_j\mu_jh^{(j)}(x)
L ( x , λ , μ ) = f ( x ) + i ∑ λ i g ( i ) ( x ) + j ∑ μ j h ( j ) ( x )
带约束的优化问题等价为:
m
i
n
x
m
a
x
λ
m
a
x
μ
,
μ
≥
0
L
(
x
,
λ
,
μ
)
\underset{x}{min}\ \underset{\lambda }{max}\ \underset{\mu,\mu \geq0}{max} \ L(x,\lambda ,\mu )
x m i n λ m a x μ , μ ≥ 0 m a x L ( x , λ , μ )
如果
h
(
j
)
<
0
h^{(j)}<0
h ( j ) < 0
μ
≥
0
\mu \geq 0
μ ≥ 0
μ
\mu
μ
求下列非线性规划问题的 K-T 点:
m
i
n
f
(
x
)
=
2
x
1
2
+
2
x
1
x
2
+
x
2
2
−
10
x
1
−
10
x
2
;
min f(x) = 2x_1^2+2x_1x_2+x_2^2-10x_1-10x_2;
m i n f ( x ) = 2 x 1 2 + 2 x 1 x 2 + x 2 2 − 1 0 x 1 − 1 0 x 2 ;
s
.
t
.
{
x
1
2
+
x
2
2
≤
5
,
3
x
1
+
x
2
≤
6.
s.t.\left\{\begin{matrix} x_1^2+x_2^2 \leq 5,\\ 3x_{1}+x_{2}\leq 6. \end{matrix}\right.
s . t . { x 1 2 + x 2 2 ≤ 5 , 3 x 1 + x 2 ≤ 6 .
解:
h
1
(
x
1
,
x
2
)
=
x
1
2
+
x
2
2
−
5
≤
0
h_1(x_1,x_2) = x_1^2+x_2^2 -5 \leq 0
h 1 ( x 1 , x 2 ) = x 1 2 + x 2 2 − 5 ≤ 0
h
2
(
x
1
,
x
2
)
=
3
x
1
+
x
2
−
6
≤
0
h_2(x_1,x_2) = 3x_{1}+x_{2} - 6 \leq 0
h 2 ( x 1 , x 2 ) = 3 x 1 + x 2 − 6 ≤ 0
拉格朗日函数
L
(
x
1
,
x
2
,
μ
1
,
μ
2
)
=
f
(
x
1
,
x
2
)
+
μ
1
h
1
(
x
1
,
x
2
)
+
μ
2
h
2
(
x
1
,
x
2
)
L(x_1,x_2,\mu_1,\mu_2) =f(x_1,x_2) + \mu_1h_1(x_1,x_2) + \mu_2h_2(x_1,x_2)
L ( x 1 , x 2 , μ 1 , μ 2 ) = f ( x 1 , x 2 ) + μ 1 h 1 ( x 1 , x 2 ) + μ 2 h 2 ( x 1 , x 2 )
▽
f
(
x
1
,
x
2
)
=
[
4
x
1
+
2
x
2
−
10
2
x
1
+
2
x
2
−
10
]
\bigtriangledown f(x_1,x_2) = \begin{bmatrix} 4x_1+2x_2-10\\ 2x_1+2x_2-10 \end{bmatrix}
▽ f ( x 1 , x 2 ) = [ 4 x 1 + 2 x 2 − 1 0 2 x 1 + 2 x 2 − 1 0 ]
▽
h
1
(
x
1
,
x
2
)
=
[
2
x
1
2
x
2
]
\bigtriangledown h_1(x_1,x_2) = \begin{bmatrix} 2x_1\\ 2x_2 \end{bmatrix}
▽ h 1 ( x 1 , x 2 ) = [ 2 x 1 2 x 2 ]
▽
h
2
(
x
1
,
x
2
)
=
[
3
1
]
\bigtriangledown h_2(x_1,x_2) = \begin{bmatrix} 3\\ 1 \end{bmatrix}
▽ h 2 ( x 1 , x 2 ) = [ 3 1 ]
KKT 条件
{
4
x
1
+
2
x
2
−
10
+
2
μ
1
x
1
+
3
μ
2
=
0
2
x
1
+
2
x
2
−
10
+
2
μ
1
x
2
+
μ
2
=
0
x
1
2
+
x
2
2
−
5
≤
0
3
x
1
+
x
2
−
6
≤
0
μ
1
≥
0
μ
2
≥
0
μ
1
(
x
1
2
+
x
2
2
−
5
)
=
0
μ
2
(
3
x
1
+
x
2
−
6
)
=
0
\left\{\begin{matrix} 4x_1+2x_2-10 + 2\mu_1x_1 + 3\mu_2 = 0\\ 2x_1+2x_2-10 + 2\mu_1x_2 + \mu_2 = 0\\ x_1^2+x_2^2 -5 \leq 0\\ 3x_{1}+x_{2} - 6 \leq 0\\ \mu_1 \geq 0\\ \mu_2 \geq 0\\ \mu_1(x_1^2+x_2^2 -5) = 0\\ \mu_2(3x_{1}+x_{2} - 6) = 0 \end{matrix}\right.
⎩ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎨ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎧ 4 x 1 + 2 x 2 − 1 0 + 2 μ 1 x 1 + 3 μ 2 = 0 2 x 1 + 2 x 2 − 1 0 + 2 μ 1 x 2 + μ 2 = 0 x 1 2 + x 2 2 − 5 ≤ 0 3 x 1 + x 2 − 6 ≤ 0 μ 1 ≥ 0 μ 2 ≥ 0 μ 1 ( x 1 2 + x 2 2 − 5 ) = 0 μ 2 ( 3 x 1 + x 2 − 6 ) = 0
这种题目,解无定法,观察得之(可以从如下情况考虑)
变量的对称性:
x
1
=
−
x
2
x_1 = -x_2
x 1 = − x 2
特殊取值试探法:
μ
=
0
\mu = 0
μ = 0
将
∂
L
∂
x
1
\frac{\partial L}{\partial x_1}
∂ x 1 ∂ L
∂
L
∂
x
2
\frac{\partial L}{\partial x_2}
∂ x 2 ∂ L
μ
\mu
μ
∂
L
∂
μ
\frac{\partial L}{\partial \mu}
∂ μ ∂ L
本题求解的最终结果为:
{
x
1
∗
=
1
x
2
∗
=
2
μ
1
=
1
μ
2
=
0
\left\{\begin{matrix} x_1^* = 1\\ x_2^* = 2\\ \mu_1 = 1\\ \mu_2 = 0 \end{matrix}\right.
⎩ ⎪ ⎪ ⎨ ⎪ ⎪ ⎧ x 1 ∗ = 1 x 2 ∗ = 2 μ 1 = 1 μ 2 = 0
也就是第一个约束
h
1
(
x
1
,
x
2
)
h_1(x_1,x_2)
h 1 ( x 1 , x 2 )
h
2
(
x
1
,
x
2
)
h_2(x_1,x_2)
h 2 ( x 1 , x 2 )
我们把
(
x
1
∗
,
x
2
∗
)
(x_1^*,x_2^*)
( x 1 ∗ , x 2 ∗ )
h
1
(
x
1
,
x
2
)
h_1(x_1,x_2)
h 1 ( x 1 , x 2 )
h
2
(
x
1
,
x
2
)
h_2(x_1,x_2)
h 2 ( x 1 , x 2 )
h
1
(
x
1
∗
,
x
2
∗
)
=
0
h
2
(
x
1
∗
,
x
2
∗
)
=
−
1
h_1(x_1^*,x_2^*) = 0 \\ h_2(x_1^*,x_2^*) = -1
h 1 ( x 1 ∗ , x 2 ∗ ) = 0 h 2 ( x 1 ∗ , x 2 ∗ ) = − 1
确实
h
1
h_1
h 1
μ
1
≥
0
\mu_1 \geq 0
μ 1 ≥ 0
h
2
h_2
h 2
μ
2
=
0
\mu_2 = 0
μ 2 = 0