李宏毅机器学习课程笔记7:Transfer Learning、SVM、Structured Learning - Introduction
这篇文章是学习本课程第19-21课所做的笔记和自己的理解。
Lecture 19: Transfer Learning
迁移学习要解决的问题是:假设现在手上有与task不直接相关的data,这些data能否帮助我们完成task呢?
比如现在要做猫狗的分类器,所谓不直接相关的data就可能是
- Similar domain, different tasks(如,大象与老虎的图片,与猫狗图片的分布是相像的)
- Different domain, same task(如,猫狗的卡通图片,与猫狗图片的分布是不像的)
为什么要考虑迁移学习呢?因为我们只有很少的数据是符合任务处理要求的(Target Data),但是类似的数据(Source Data)却有很多。例如,我们的任务是辨识台语,我们只有很少台语数据,但是我们有很多其它语言的数据。
按Target Data与Source Data是labelled还是unlabelled,迁移学习可以分为四类:
- Target Data: labelled, Source Data: labelled ——最常见的是Model Fine-tuning,此外还有Multitask Learning
- Target Data: labelled, Source Data: unlabelled——Self-taught learning
- Target Data: unlabelled, Source Data: labelled——Domain-adversarial training, Zero-shot learning
- Target Data: unlabelled, Source Data: unlabelled——Self-taught Clustering
Model Fine-tuning

具体解释一下图中的Example, Target data可能是某人说的三句话,而Source data可能有上万小时。
图中的Idea是非常直觉的,先用Source data训练出一个模型,把训练结果作为初始值,再用Target data来Fine-tune 模型。可能存在的问题是,由于target data可能会很少,所以就算用source data训练出的模型很好,再用target data做fine-tune的时候可能会过拟合。避免这个问题就需要技巧。
技巧之一便是Conservative Training.

Conservative Training的意思就是,为了避免target data 在 fine-tune 模型时造成过拟合,要增加约束,即增加正则化项,让同一笔data经fine-tune前后两个模型的output越接近越好,或两个模型的参数越接近越好。
技巧之二便是Layer Transfer.

(左上图)Layer Transfer的意思是,把Source data 训练好的模型中的某些layer直接copy过来,用target data 训练剩下的layer。这样的好处是,target data 只需要训练较少的参数,避免了过拟合。
(右上图)在不同的task上,需要被transfer的layer往往是不一样的。比如在语音识别上,通常copy最后几层,重新训练前几层。这是因为语音识别神经网络前几层是识别语者的发音方式,后几层是识别,后几层与语者没有关系。在图像识别上,通常copy前面几层,重新训练后面几层。这是因为图像识别神经网络的前几层是识别有没有基本的几何结构,因此可以transfer,而后几层往往学到的比较抽象,无法transfer。所以,哪些layer要被transfer是case by case的。
(左下图)Image在Layer Transfer上的实验,出自Bengio在NIPS2014的paper。把ImageNet分成Source、Target两部分,横轴代表Layer Transfer时copy几个layer(0个代表没有Layer Transfer,是Baseline),纵轴是Top-1 accuracy. 曲线4表明,前面几个layer是可以共用的。曲线5表明,Layer Transfer + Fine-tuning 在所有case下,Top-1 accuracy均有提高。这一结果的惊人之处在于,这里的target data已经非常多(ImageNet的一半),但是再加上Source data(ImageNet的另一半)仍然有所帮助。曲线2表示,如果用target domain训练出一个模型,fix住前几个layer,再用target domain训练后几个layer,结果可能坏掉。曲线3表明,在曲线2基础上fine-tune,结果会恢复。
(右下图)红色线是左下图中的曲线4。黄色线表示,如果source和target比较没有关系(比如把所有自然界的图片当做source,所有人工的图片当做target),那么transfer效果会掉很多,但只copy前几个layer影响是比较小的。绿色线表示,如果前几个layer的参数是random的,结果会烂掉。
Multitask Learning
Multitask Learning 与 Fine-tuning 的区别在于, Fine-tuning 在意的是在target domain上做得好不好,不介意fine-tune 之后在source domain 上结果坏掉。而在Multitask Learning 中,要同时在意在target domain与source domain上做得好不好。

左边的网络,如果两个task有共通性,则可以共用前面几个layer(用source+target一起训练)。如果两个task连input都不能share,可以各经过几层layer,把输入变换到同一个domain上,中间某几层可以是share的。

Multitask Learning的一个成功例子是多语言的语音识别,可训练一个模型同时识别多国语言,几乎所有语言都可以transfer(有人做过实验,多国语言两两transfer,每个case都有进步,哪怕语言之间不是很像)。前几个layer共用参数,后几个layer不同。翻译上也可以类似,如中翻英、中翻日可以同时训练。

蓝线表示,没有transfer learning时汉语识别结果。黄线表示,用欧洲语言做Transfer learning,帮助训练汉语识别网络的前几层,在相同汉语训练数据下,错误率要低。所以在这里Multitask Learning的好处是,只需要更少的数据,就可以达到同样好的效果。
Progressive Neural Network
如果两个task很不相关,却又做了transfer,效果可能是负面的。有人提出了Progressive Neural Network,使得两个task即使无关,做transfer效果也不会比不做更差。

训练好第一个模型后,第一个模型的参数就fix住。训练第n个模型时,每个隐层都借用前n-1个模型的隐层输出。
Domain-adversarial training

适合Target Data: unlabelled, Source Data: labelled的情况,将source data视作training data,将target data视作testing data。问题在于二者之间是mismatch的,在source data上训练出来的模型如何才能在mismatch的target data上也work呢?

(左上图)如果对mismatch的问题视而不见,那么结果会烂掉。NN前面几层可以看做在抽feature,我们会发现不同domain 的feature完全不一样:蓝色点MNIST, 红色点MNIST-M(均为t-SNE降维后)。后面几层可看做在做分类,虽然可以把蓝色点分得很好,但是对红色点却无能为力。
(右上图)所以,希望feature extractor可以把domain的特性去除掉,把不同domain的feature都混在一起(Domain-adversarial training)。做法是在feature extractor(Generator)后面接一个domain classifier(Discriminator),它的架构类似GAN,不过在GAN中Generator要产生一张Image来骗过Discriminator,这件事很难;而在Domain-adversarial training中要骗过domain classifier很简单(不管什么input, feature extractor的output都是0,就轻易骗过domain classifier了)。所以只训练domain classifier是不够的,要给feature extractor增加任务难度。
(左下图)feature extractor不仅要骗过domain classifier,还要让label predictor做得好。不只把domain的特性消掉,对这个任务来讲还要保留digit的特性。三个部分组成一个大网络,各个部分目的不同(“各怀鬼胎”,feature extractor要“陷害”队友domain classifier)。
(右下图)feature extractor要如何“陷害”队友domain classifier呢?只要加一个gradient reversal layer就行。Backpropagation时feature extractor做与domain classifier的要求相反的事情,domain classifier要某个值上升,feature extractor就让那个值下降。由于domain classifier看不到input image,所以最后会输掉,无法分辨feature extractor抽出的feature来自哪个domain。但是domain classifier应该要奋力挣扎,否则不能把feature extractor逼到极限,不能把domain information去除掉。

paper中给出的实验结果。
source only指的是,只用source data训练模型,然后测试target data。这种方法的效果是比较差的。
proposed approach指的是Domain-adversarial training, 效果有很好的提高。
train on target指的是,直接拿target domain 的 data 训练,是performance的up-bound.
Zero-shot Learning
适合Target Data: unlabelled, Source Data: labelled的情况,将source data视作training data,将target data视作testing data。但二者是不同的task。例如,source data中有猫狗的图片,没有羊驼的图片,而target data中是羊驼的图片。那训练出的模型能认出羊驼吗?语音上常遇到Zero-shot Learning的问题,若把每个word都当做一个class,那么training的时候与testing的时候就可能会看到不同的词汇。解决办法是,不去识别一段声音属于哪个word,而是识别一段声音属于哪个音素(音标),然后根据人的知识建立一个音标和词汇关系的词典。

(左上图)在图像上,做法是把图像的类用attributes表示,如图中的database,attributes要足够丰富以使每个类有独一无二的attributes。在training时,不直接识别图像所属类别,而是识别图像具备什么attributes。
(右上图)在testing的时候,就算来了一张没见过的类中的image,输出是attributes,查表就知道与output attributes最接近的类。
(左下图)有时attributes维度很高,可以做attribute embedding. 把training data中每张image都变成embedding space上的一个点,把所有attributes也都变成embedding space上的一个点。图中的g” role=”presentation” style=”position: relative;”>gg)
(右下图)如果没有database、不知道每个class对应的attributes怎么办呢?可以借用word embedding, 把attributes换成 word vector.

上面的目标函数是有问题的,因为它只考虑了同一个pair在embedding之后尽可能接近,没有考虑不同pair在embedding之后尽可能拉开,所以可能会把所有的xn,yn” role=”presentation” style=”position: relative;”>xn,ynxn,yn 都投到同一点。应改成下面的目标函数。

Zero-shot Learning的一个更简单方法,叫Convex Combination of Semantic Embedding, 不需要training.
Self-taught learning, Self-taught Clustering
- Target Data: labelled, Source Data: unlabelled——Self-taught learning
Target Data: unlabelled, Source Data: unlabelled——Self-taught Clustering
Self-taught learning的意思是,如果现在source data够多,那么可以学习一个feature extractor(在原始Self-taught learning的paper中,feature extractor是sparse coding, 现在可以用autoencoder),然后用这个feature extractor在target data上抽feature.

Lecture 20: Support Vector Machine (SVM)
SVM有两大特色:Hinge Loss和Kernel Method
Hinge Loss
先复习一下Binary Classification.

左图中的δ()” role=”presentation” style=”position: relative;”>δ()δ() 是指示函数,不可微分。
右图中横轴是y^f(x)” role=”presentation” style=”position: relative;”>y^f(x)y^f(x) 越大,损失函数越小。可微分的损失函数可以自己选,比如蓝线、绿线、红线……

(左上图)Square Loss(红色线),是不合理的(y^f(x)” role=”presentation” style=”position: relative;”>y^f(x)y^f(x) 很大时,损失函数很大)。
(右上图)Sigmoid + Square Loss(蓝色线)。对l(f(xn),y^n)” role=”presentation” style=”position: relative;”>l(f(xn),y^n)l(f(xn),y^n) ,可以理解公式的合理性。逻辑回归时不会用square loss,因为它的performance不好,而是用cross entropy.
(左下图)Sigmoid + cross entropy(绿色线)。指的是σ(f(x)),1−σ(f(x))” role=”presentation” style=”position: relative;”>σ(f(x)),1−σ(f(x))σ(f(x)),1−σ(f(x)) 很负时,应该朝正方向调整,但对蓝色线来讲调整没有回报,而对绿色线调整有回报。
(右下图)Hinge Loss(紫色线).损失函数l(f(xn),y^n)” role=”presentation” style=”position: relative;”>l(f(xn),y^n)l(f(xn),y^n) 从1变成2时,前者loss不降,后者loss下降(“好还要更好”)。实践中相差不多,Hinge Loss可能会微胜Sigmoid + cross entropy。Hinge loss的好处是不害怕outlier, 学习出的结果比较鲁棒,下面讲kernel时会明显看到这一点。
Linear SVM

Linear SVM的function是linear的,如图中公式所示,当f(x)>0” role=”presentation” style=”position: relative;”>f(x)>0f(x)>0 时,x属于class 2。
Linear SVM的loss function是hinge loss + 正则项,由于hinge loss和正则项都是convex的,所以loss function整体也是convex的。曲线有棱棱角角也是可微分的。
Linear SVM与Logistic regression 区别只在于损失函数不同,前者的损失函数是hinge loss,后者的损失函数是cross entropy。
事实上,function (model) 没必要必须是linear的,不过若是linear的则有好的特质;若不是linear的也可以用gradient descent来训练,所以SVM可以有deep的版本(见图中的参考paper). 在DL中把cross entropy改成hinge loss,其实做的就是deep SVM。

SVM是可以用gradient descent来训练的。
图中红色方框等于xin” role=”presentation” style=”position: relative;”>xnixin.

将l(f(xn),y^n)” role=”presentation” style=”position: relative;”>l(f(xn),y^n)l(f(xn),y^n) 。
上下两个方框本是不等价的(上面可以推出下面,但是下面不能推出上面),但是加上“Minimizing loss function L”之后二者就等价了。下面就是常见的SVM的约束,εn” role=”presentation” style=”position: relative;”>εnεn 是松弛因子(不能是负的,否则就不是松弛了)。这是一个二次规划问题(quadratic programming problem),可代入QP solver求解或用gradient descent求解。
Kernel Method
Dual Representation

要学Kernel Method, 先要了解Dual Representation,Dual Representation指的是:最小化损失函数的权重参数w∗” role=”presentation” style=”position: relative;”>w∗w∗ 的线性组合。一般用拉格朗日乘子法解释这一结论,这里从另外的角度解释。
之前说过,Linear SVM可以用gradient descent来更新参数,根据前面得到的公式,每次更新权重都加上xn” role=”presentation” style=”position: relative;”>xnxn 是支持向量。这样的好处是模型比较鲁棒:不是支持向量的数据点,就算去掉也不会对结果有影响,outlier只要不是支持向量,就不会对结果有影响。反观logistic regression(用cross entropy作损失函数),它在更新参数时的权重就不sparse,所以每笔data都对结果有影响。

把w” role=”presentation” style=”position: relative;”>ww 的线性组合,最大的好处是可以使用Kernel trick.
根据w=Xα” role=”presentation” style=”position: relative;”>w=Xαw=Xα 之间的内积即可。
可以把内积(xn·x)” role=”presentation” style=”position: relative;”>(xn⋅x)(xn·x).
这样,整体损失函数可以改写为图中的式子,我们不需要知道x” role=”presentation” style=”position: relative;”>xx 即可,这就叫Kernel trick. Kernel trick不只可用于SVM,也可用于logistic regression, linear regression等。(图中”project”应改为”product”)
Kernel trick

有时需要做特征变换,而直接计算核函数会比“特征变换+计算内积”快。

RBF Kernel, x与z越像,则K(x,z)” role=”presentation” style=”position: relative;”>K(x,z)K(x,z) 越大。它是两个无穷维特征向量的内积。将核函数展开并使用泰勒级数,可见核函数是无穷项之和,每项都可写成内积形式,将与x,z有关的向量分别串起来,得到两个无穷维的向量,这两个向量的内积就是RBF核函数。由于使用了无穷维的特征,在用RBF核函数时要小心overfitting(可能在training data 上得到很好的performance, 而在testing data 上得到很糟的performance)。
Sigmoid Kernel. (图中αn,α1,α2” role=”presentation” style=”position: relative;”>αn,α1,α2αn,α1,α2 ). sigmoid kernel可看做一个单隐层网络,neuron个数就是支持向量个数,neuron权重就是支持向量各维度的数值。

不是所有的f(x,z)” role=”presentation” style=”position: relative;”>f(x,z)f(x,z), Mercer’s theorem 告诉我们哪些可以。
SVM related methods:
- Support Vector Regression (SVR) [Bishop, Chapter 7.1.4]
- Ranking SVM [Alpaydin, Chapter 13.11]
- One-Class SVM [Alpaydin, Chapter 13.11]
比较Deep Learning 与 SVM:
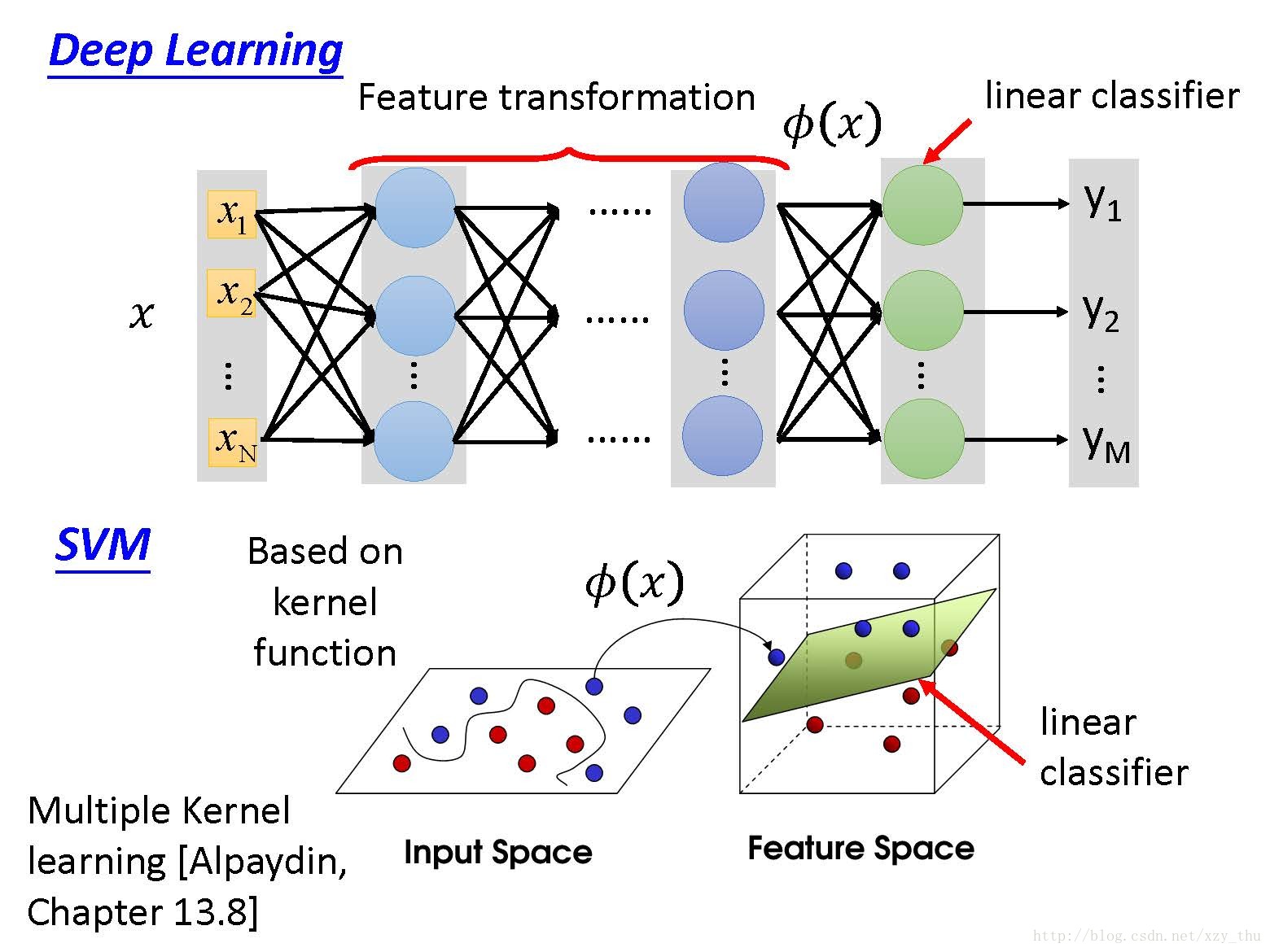
SVM的kernel是learnable的,见图中的reference。可以learn不同kernel组合时的权重。
Lecture 21: Structured Learning - Introduction
Structured Learning

目前为止,我们学到的SVM, DL等的输入输出都是向量,而有时我们希望输入输出是带有结构的,比如sequence, list, tree, bounding box…… Structured Learning有很多应用(见图)。
Unified Framework
Structured Learning虽然听起来很难,但是它有一个统一的框架。

训练时,找一个函数F:X×Y→R” role=”presentation” style=”position: relative;”>F:X×Y→RF:X×Y→R, X,Y是 input structured objects, R 是 real number, 衡量 x,y 有多匹配。
测试时,对给定的x” role=”presentation” style=”position: relative;”>xx.
Deep Learning 与 Structured Learning 是有关系的,GAN 就是实践这一 Framework 的方法。

可以从联合概率分布的角度来理解Structured Learning的Unified Framework.
其实,Graphical Model就是Structured Learning的一种,把F(x,y)” role=”presentation” style=”position: relative;”>F(x,y)F(x,y) 换成了概率。Believe Network, Markov random field等都是找一个evaluate function (概率)。
用概率的缺点:1、有的场景下谈概率是很奇怪的,比如搜索;2、normalization到1是麻烦且不必要的。
用概率的优点:Meaningful
Yann Lecun 提出的Energy-based Model,讲的也是Structured Learning.
Three Problems
在这个Framework中,要解三个问题。

GAN是解决这三个问题的曙光。

这三个问题,可以和HMM联系起来,也可以和DNN联系起来。
HMM的三个问题,就是general的Structured Learning的三个问题。
DNN是Structured Learning的特例,例如在手写数字识别中,训练时input x,y” role=”presentation” style=”position: relative;”>x,yx,y . 测试时,由于分类只有十类,可以穷举,用cross entropy的话,看哪个digit对应的维度的值最大。
李宏毅机器学习课程笔记
李宏毅机器学习课程笔记1:Regression、Error、Gradient Descent
李宏毅机器学习课程笔记2:Classification、Logistic Regression、Brief Introduction of Deep Learning
李宏毅机器学习课程笔记3:Backpropagation、”Hello world” of Deep Learning、Tips for Training DNN
李宏毅机器学习课程笔记4:CNN、Why Deep、Semi-supervised
李宏毅机器学习课程笔记5:Unsupervised Learning - Linear Methods、Word Embedding、Neighbor Embedding
李宏毅机器学习课程笔记6:Unsupervised Learning - Auto-encoder、PixelRNN、VAE、GAN
李宏毅机器学习课程笔记7:Transfer Learning、SVM、Structured Learning - Introduction
李宏毅机器学习课程笔记8:Structured Learning - Linear Model、Structured SVM、Sequence Labeling
李宏毅机器学习课程笔记9:Recurrent Neural Network
李宏毅机器学习课程笔记10:Ensemble、Deep Reinforcement Learning
文章转载: https://blog.csdn.net/xzy_thu/article/details/71921263