原文链接:Face Image Illumination Processing Based on Generative Adversarial Nets
摘要:众所周知,光照的变化会严重影响二维人脸分析算法的性能,如人脸标记和人脸识别。不幸的是,在大多数实际应用中,照明条件通常是不受控制和不可预测的。为了解决这个问题,已经有很多方法被开发出来,但是效果很差,特别是对于光线条件极端的图像。此外,传统的光照处理方法大多只在灰度图像上显示,对人脸图像的对齐要求非常严格,在实际应用中应用有限。本文提出了一种基于生成对抗性网络(GAN)的人脸图像光照处理问题,并将其作为一种风格转换任务进行重构。关键的见解是在不知道它们的真实分布的情况下,使用GAN在两个域之间的强大映射能力。在这种新视野下,我们开发了一种新的多尺度对偶判别网络,并利用多尺度对偶学习来进行视觉逼真的光照处理。我们提倡利用传统方法的洞见,在图像质量评价中加入重构学习和两项新的损失项,以加强除生成图像细节外的所有其他光照的保护。在CMU Multi-PIE和FRGC数据集上的实验表明,该方法可以获得良好的光照归一化结果,并保持了良好的视觉质量。
网络架构:
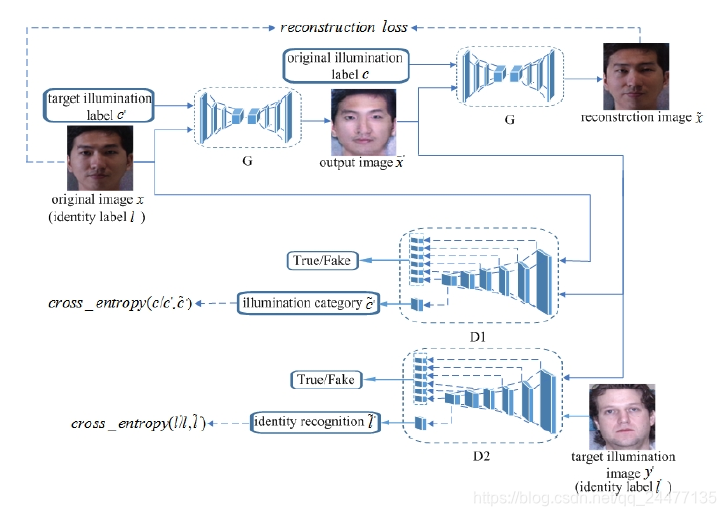
对于该网络架构的理解:首先,有一个生成器G和两个判别器D。生成器的输入是原始人脸图像x,以及目标的光照强度c',通过G生成一张目标光照的人脸图像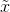
损失函数:
1、判别器损失函数
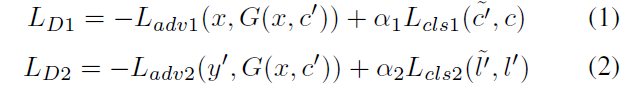
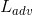
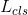
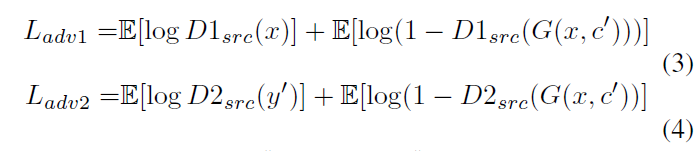

其中,α1和α2是权重参数。为判别器输出的为真实图像的概率。G希望式(3)、(4)最小化,而D1和D2希望他们最大化。在式(5)、(6)中,
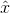
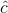
2、生成器损失函数
基础损失:

将',身份判别为
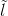
重构损失:

为了进一步保证翻译后的图像在只改变输入中与光照相关的部分的同时保留输入图像的内容,弥补训练数据的不足,论文对生成器应用了循环一致性损失,定义为式(8)。可以看出该损失计算的就是网络架构图最上面的那部分。作者们说他们首先采用了L1正则化作为重构损失。
SSIM(结构相似度)损失:

其中ux、uy分别表示图像X和Y的均值,σX、σY分别表示图像X和Y的方差,σXY表示图像X和Y的协方差,即
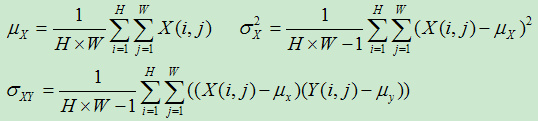
(图片来自:https://www.cnblogs.com/vincent2012/archive/2012/10/13/2723152.html)
c1、c2、c3为常数,为了避免分母为0的情况,通常取c1=(k1*L)^2, c2=(k2*L)^2, c3=c2/2, 一般地k1=0.01, k2=0.03, L 是像素值范围,论文中为1.式(9)、(10)、(11)组合在一起有:
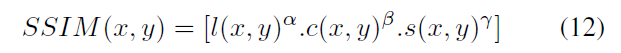
取α, β, γ为1,则
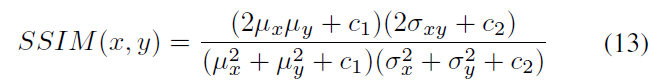
SSIM越接近1,两个图像之间越相似。最终用于训练的SSIM损失为:

PSNR(Peak signal-to-noise ratio)峰值信噪比损失:
首先彩色图像3通道的的均方误差为:

PSNR为:
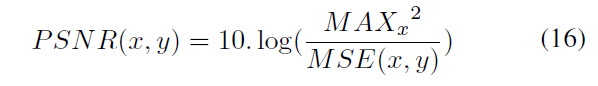
其中MAXx为x中像素的最大值,论文中为1.最终的PSNR损失为:
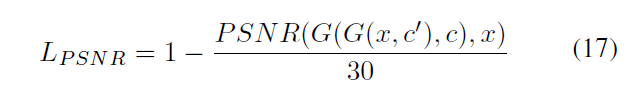
30为作者们的经验值,取正则化PSNR的值。
最终,G的损失函数为:

其中,α3=10和α4=5
训练算法:

其中Kd = 5, Kg = 1, T= 1000。 在前500次迭代中,G和D的学习率都是0.0001,后面逐渐线性衰减至0.λgp = 10。另外,为了性能更优,作者们把式(3)、(4)利用WGAN的改进方法替换为:

因为没有源代码,所以更多的细节无法知道。
实验效果图:




想说的:
国内的论文都很少提供代码,所以不能学到更细节的东西。而且论文里面的网络架构给的并不是很明确,生成网络如何实现、判别器网络如何实现?和CycleGAN或者patchsGAN有什么区别都不得而知。
感觉这个就是CycleGAN的一个扩展与应用,不同域之间的转换映射,这个是多个域到一个域,还可以一个域到多个域。