Container
Container就是一个yarn的java进程,在Mapreduce中的AM,MapTask,ReduceTask都作为Container在Yarn的框架上执行,你可以在RM的网页上[8088端口]看到Container的状态。
基础
Yarn的ResourceManger(简称RM)通过逻辑上的队列分配内存,CPU等资源给application,默认情况下RM允许最大AM申请Container资源为8192MB("yarn.scheduler.maximum-allocation-mb"),默认情况下的最小分配资源为1024M("yarn.scheduler.minimum-allocation-mb"),AM只能以增量("yarn.scheduler.minimum-allocation-mb")和不会超过("yarn.scheduler.maximum-allocation-mb")的值去向RM申请资源,AM负责将("mapreduce.map.memory.mb")和("mapreduce.reduce.memory.mb")的值规整到能被("yarn.scheduler.minimum-allocation-mb")整除,RM会拒绝申请内存超过8192MB和不能被1024MB整除的资源请求[内存增量]。
1 yarn-site.xml设置
yarn进行资源管理的时候:以contain作为最小单位来进行资源分配的。
事实上Hadoop所有设置都可以写在同一个xml中,但是为了自己查看方便,模块化,所以分开写。
yarn-site.xml主要设置yarn的基本配置,以yarn开头的配置项。修改后必须重启集群生效。
mapred-site.xml主要设置mapreduxe任务的配置项。修改后不需重启集群。
1.1 NM设置(NodeManager)
NM的内存资源配置,主要是通过下面两个参数进行的(这两个值是Yarn平台特性,应在yarn-sit.xml中配置) :
yarn.nodemanager.resource.memory-mb 默认8GB
yarn.nodemanager.vmem-pmem-ratio 默认2.1
说明:第一个参数:该结点向操作系统申请的内存总量,RM中的两个值不能超过此值。此数值可以用于计算container最大数目,即:用此值除以RM中的最小容器内存。第二个:虚拟内存率,是占task所用内存的百分比,默认值为2.1倍。如报错虚拟内存溢出,则提高该值。
注意:第一个参数默认大小是8G,即使计算机内存不足8G也会按着8G内存来使用,所有计算机内存小于8GB应该调低这个值。
1.2 RM设置(ResourceManager)
RM的内存资源配置,主要是通过下面的两个参数进行的(这两个值是Yarn平台特性,应在yarn-sit.xml中配置):
yarn.scheduler.minimum-allocation-mb 默认1GB
yarn.scheduler.maximum-allocation-mb 默认8GB
说明:单个容器可申请的最小与最大内存,应用在运行申请内存时不能超过最大值,应用申请小于最小值则会分配最小值,从这个角度看,最小值有点像操作系统中的页。最小值还有另外一种用途,用来计算一个节点的最大container数目。注:这两个值一经设定不能动态改变(此处所说的动态改变是指需要重启集群生效)。
2 mapred-site.xml设置
2.1 AM设置(ApplicationManager)
AM内存配置相关参数,此处以MapReduce为例进行说明(这两个值是AM特性,应在mapred-site.xml中配置),如下:
mapreduce.map.memory.mb 默认
mapreduce.reduce.memory.mb 默认
说明:单个Map/Reduce task 申请的内存大小,其值应该在RM中的最大和最小container值之间。如果没有配置则通过如下简单公式获得:
max(MIN_CONTAINER_SIZE, (Total Available RAM) / containers))
一般reduce内存大小应该是map的2倍。注:这两个值可以在应用启动时通过参数改变,可以动态调整;
2.2 AM JVM设置
AM中其它与内存相关的参数,还有JVM相关的参数,这些参数可以通过,如下选项配置:
mapreduce.map.java.opts 默认
mapreduce.reduce.java.opts 默认
说明:这两个参主要是为需要运行JVM程序(java、scala等)准备的,通过这两个设置可以向JVM中传递参数的,与内存有关的是,-Xmx,-Xms等选项。此数值大小,应该在AM中的map.mb和reduce.mb之间。
2.3 总结
AM为Map/Reduce task向RM申请资源,RM按照min和max、资源增量的值为task分配一个固定大小的container供task使用。RM可以分配下去的资源总量受到NM配置的值限制。
3 注意
在hadoop2及以上版本中,map和reduce task 是运行在container中的。mapreduce.{map|reduce}.memory.mb 被yarn用来设置container的内存大小。如果container的内存超限,会被yarn杀死。在container中,为了执行map和reduce task,yarn会在contaner中启动一个jvm来执行task任务。mapreduce.{map|reduce}.java.opts用来设置container启动的jvm相关参数,通过设置Xmx来设置map 或者reduce task的最大堆内存。
理论上,{map|reduce}.java.opts设置的最大堆内存要比{map|reduce}.memory.mb小。一般设置为一般设置为0.75倍的memory.mb即可;因为在yarn container这种模式下,JVM进程跑在container中,需要为java code等非JVM的内存使用预留些空间。
运行中的设置方法例如:xml中也可设置
hadoop jar -Dmapreduce.reduce.memory.mb=4096 -Dmapreduce.map.java.opts=-Xmx3276
4 常见内存溢出报错&解决
默认情况下,yarn.nodemanager.vmem-pmem-ratio被设置为2.1,这意味着,每个map或者task任务只能使用2.1倍("mapreduce.reduce.memory.mb") or ("mapreduce.map.memory.mb") 大小的虚拟内存,如果使用的量超出则会被nm杀掉。
例如:日志中常见报错:
1、Container xxx is running beyond physical memory limits
2、java heap space
3、Error: GC overhead limit exceeded
报错1:Current usage: 1.1gb of 2.0gb physical memory used; 4.6gb of 4.2gb virtual memory used. Killing container.[即虚拟内存溢出];
方法一:提高yarn.nodemanager.vmem-pmem-ratio = 5或者更高;[推荐]
方法二:yarn.nodemanager.vmem-check-enabled =false ;关闭虚拟内存检查;不推荐
方法三:提高物理内存分配,相应的虚拟内存自然就多了,但是这样不是最优
报错2:Current usage: 2.1gb of 2.0gb physical memory used; 3.6gb of 4.2gb virtual memory used. Killing container.[即物理内存溢出];
方法一:mapreduce.map.memory.mb = 3GB以上,然后测试这个map/reduce task需要使用多少内存才够用,提高这个值直到不报错为止。
方法二:提高yarn.scheduler.minimum-allocation-mb = 3GB以上,同理[不推荐]
5 内存分配增量/规整因子/incrementMemory
为了易于管理资源和调度资源,Hadoop YARN内置了资源规整化算法,它规定了最小可申请资源量、最大可申请资源量和资源规整化因子,规整化因子是用来规整化应用程序资源的,应用程序申请的资源如果不是该因子的整数倍,则将被修改为最小的整数倍对应的值,公式为ceil(a/b)*b,其中a是应用程序申请的资源,b为规整化因子。对于规整化因子,不同调度器不同,具体如下:
FIFO和Capacity Scheduler,规整化因子等于最小可申请资源量,不可单独配置。
Fair Scheduler:规整化因子通过参数yarn.scheduler.increment-allocation-mb和yarn.scheduler.increment-allocation-vcores设置,默认是1024和1。
通过以上介绍可知,应用程序申请到资源量可能大于资源申请的资源量,比如YARN的最小可申请资源内存量为1024,规整因子是1024,如果一个应用程序申请1500内存,则会得到2048内存,如果规整因子是512,则得到1536内存。
如下图:map container的内存("mapreduce.map.memory.mb")被设置为1536mb 。但是AM会为其申请了2048m的内存,因为am的最小分配单位/增量(yarn.scheduler.minimum-allocation-mb)被设置为1024,也就是以1GB为单位往上加。这是一种逻辑上的分配,这个值被NodeManager用来监控该进程内存资源的使用率,如果mapTask的堆内存使用率超过了2048MB,NM将会把这个task给杀掉。
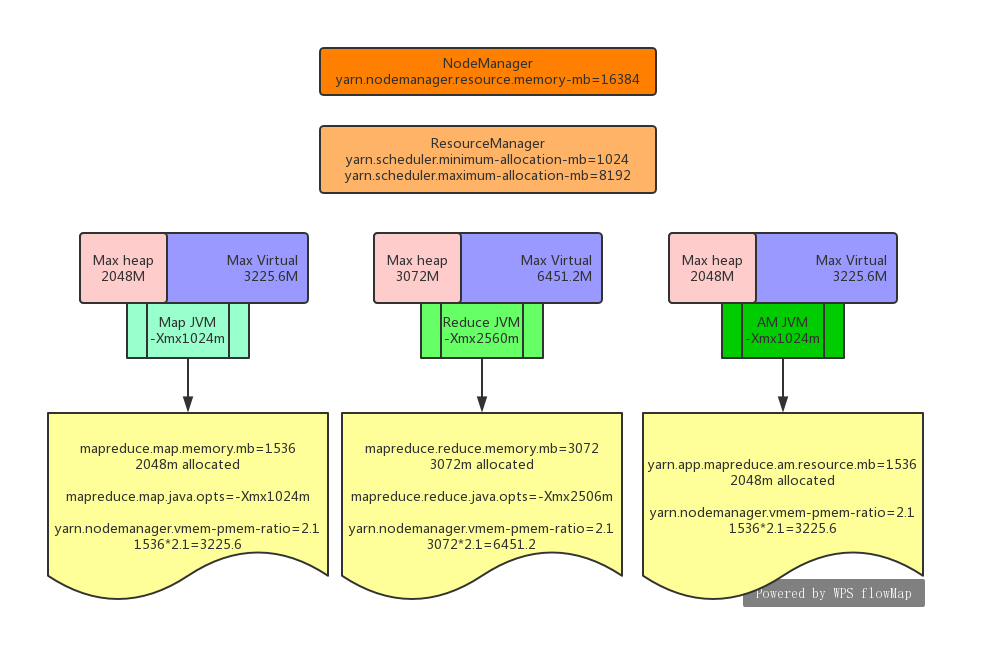
从上面的图可以看出map,reduce,AM container的JVM,"JVM"矩形代表服务进程,"Max heap","Max virtual"矩形代表NodeManager对JVM进程的最大内存和虚拟内存的限制。
-------------------------------------------------------------------------------------------------
对于56G内存的NM来说,如果全部跑map则56/3大约跑18个container
大概了解完以上的参数之后,mapreduce.map.java.opts和mapreduce.map.memory.mb参数之间,有什么联系呢?
通过上面的分析,我们知道如果一个yarn的container超除了heap设置的大小,这个task将会失败,我们可以根据哪种类型的container失败去相应增大mapreduce.{map|reduce}.memory.mb去解决问题。 但同时带来的问题是集群并行跑的container的数量少了,所以适当的调整内存参数对集群的利用率的提升尤为重要。
------------------------------------------------------------------------------------------------------------
未完待续......