Hadoop数据压缩
开源的7zip、rar;减少数据量IO(网络传输、磁盘读写) ;压缩默认是关闭;
压缩策略

运算密集型大量需CPU,IO密集型是大量用磁盘;
存储数据主要用的Gzip,Linux和hadoop都支持,使用方便;
Snappy一般用在Map输入,Reduce输出的时候启用;
Gzip压缩| 常用的,用在头| 尾数据

tar.gz输入的数据不能太大,不然一个MapTask处理的数据太多
Bzip

Snappy
主要用在shuffle阶段;如在Map最后的输出阶段


压缩位置
头、中间的shuffle、尾部

压缩的配置
输入端:放一个压缩文件它能自动识别,不需要配置;
mapreduce.map.output.compress(在mapred-site.xml中配置) false mapper输出 这个参数设为true启用压缩
mapreduce.map.output.compress.codec(在mapred-site.xml中配置) org.apache.hadoop.io.compress.DefaultCodec mapper输出 企业多使用LZO或Snappy编解码器在此阶段压缩数据
编码格式可写gzip格式,默认用的snappy但现hadoop不支持
mapreduce.output.fileoutputformat.compress(在mapred-site.xml中配置) false reducer输出 这个参数设为true启用压缩
自定义压缩和解压
public class TestCompress {
public static void main(String[] args) throws IOException {
compress("F://web.log", BZip2Codec.class); //压缩
//decompress("F://web.log.bz2"); //解压缩
} //传入一个压缩类,通过这个类反射进来一个实例codec,通过实例把流包装起来
private static void compress(String path, Class<? extends CompressionCodec> codecClass) throws IOException {
CompressionCodec codec = ReflectionUtils.newInstance(codecClass, new Configuration());
String extension = codec.getDefaultExtension(); //压缩格式为默认的扩展名,默认的为.bz2;与上边的BZip2Codec.class对应的
/*public String getDefaultExtension() {
return ".bz2";
}*/
//开流
FileInputStream fis = new FileInputStream(path);
FileOutputStream fos = new FileOutputStream(path + extension);//加个扩展名
CompressionOutputStream cos = codec.createOutputStream(fos); //包装流,创建输出流的压缩流
//流要对口
IOUtils.copyBytes(fis, cos, 1024);
IOUtils.closeStream(fis);
IOUtils.closeStream(cos);
}
private static void decompress(String path) throws IOException {
CompressionCodecFactory codecFactory = new CompressionCodecFactory(new Configuration());
//工厂模式,通过文件名path,getCodec返回一个具体的类,这叫工厂模式,在编码写代码的时候很好用;没工厂模式就要不断的判断if或switch
CompressionCodec codec = codecFactory.getCodec(new Path(path));
FileInputStream fis = new FileInputStream(path);
FileOutputStream fos = new FileOutputStream("F://1.log");
CompressionInputStream cis = codec.createInputStream(fis); //输出的就不是压缩的了
//谁被压缩就包谁,这里得是cis
IOUtils.copyBytes(cis, fos, 1024);
IOUtils.closeStream(cis);
IOUtils.closeStream(fis);
}
}
① Map输出端采用压缩也就是在shuffle阶段的配置:
在Driver.java
Configuration configuration = new Configuration();
// 开启map端输出压缩
configuration.setBoolean("mapreduce.map.output.compress", true);
// 设置map端输出压缩方式
configuration.setClass("mapreduce.map.output.compress.codec", BZip2Codec.class, CompressionCodec.class);
//在工作中不能采用Bzip压缩,文件大点 2M/S的速度,会很慢!!
//1.获取一个任务实例; 获取配置信息和封装任务
Job job = Job.getInstance(configuration); //new Configuration()
--->结果看不出什么区别的
INFO [org.apache.hadoop.io.compress.CodecPool] - Got brand-new compressor [.bz2] ##在shuffle阶段采用压缩
② 输入端的压缩不需配置,可自动识别
[org.apache.hadoop.io.compress.CodecPool] - Got brand-new decompressor [.bz2]
③ 在Reduce输出端采用压缩的设置
// 设置reduce端输出压缩开启
FileOutputFormat.setCompressOutput(job, true);
// 设置压缩的方式
FileOutputFormat.setOutputCompressorClass(job, BZip2Codec.class);
//6.提交任务
boolean b = job.waitForCompletion(true);
--->最后的结果是part-r-00000.bz2格式的
Yarn资源调度器
Yarn资源池;形如cpu和内存;
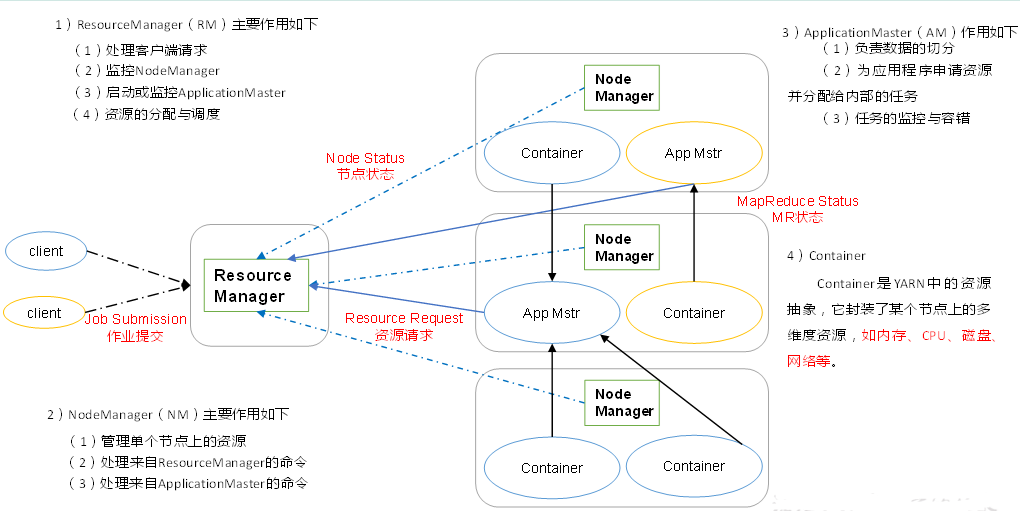
1、YARN架构
RM、NM不关心Job的运行情况;RM只关心客户端的申请、Task和Task的调度;
NM只听命令(RM、AM)
Job的整个运行是由ApplicationMaster(AM)负责
MapTask、ReduceTask、ApplicationMaster都是运行在Container内部
2、YARN的工作运行机制
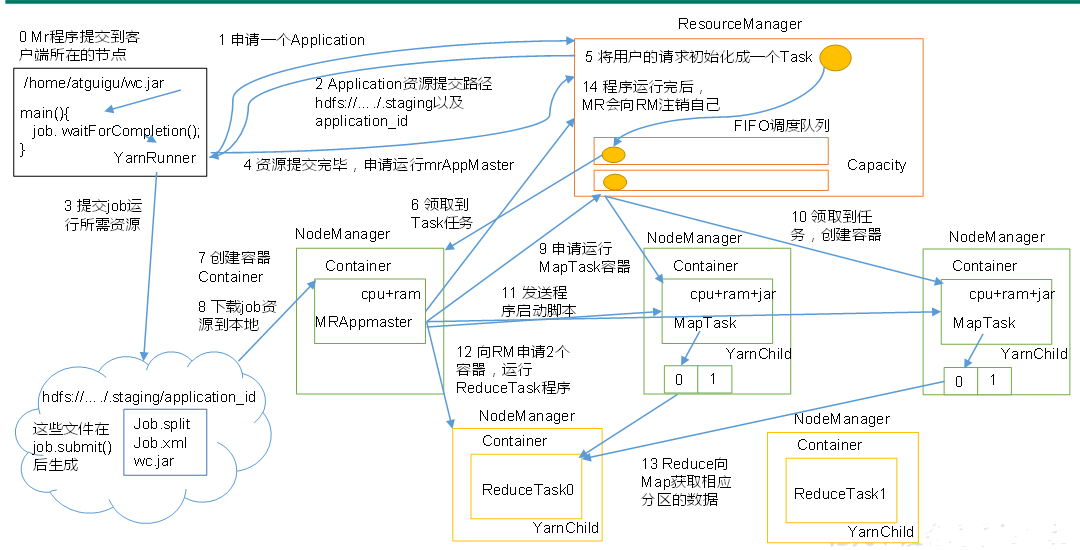
提交作业
Client调用job.waitForCompletion方法让整个集群提交MapReduce作业任务;
Client----->向ResourceManager申请一个Application,RM给Client返回该job资源的提交路径和作业id即application_id告诉这个任务是几号;
---->Client--Drever就会把资源(Job.split、Job.xml、wc.jar)提交到指定的资源提交路径--HDFS上的临时文件夹
---Client资源提交完---->向ResourceManager申请运行MrAppMaster;
作业初始化
------>RM将用户请求包装成一个Task----->把Task添加到容量调度队列里 ----->某一个空闲的NodeManager(领取到Task即Job任务)
---->该NM创建Container并产生且运行MrAppMaster(这个任务才真正执行) ----->把Client提交的资源下载到本地,
任务分配
MrAppMaster根据切片的数量向RM申请MapTask容器任务资源 --->RM把它包装成Task添加到队列---->RM将运行MapTask这个任务分配给另外两个NodeManager,另外两个NodeManager分别领取任务并创建Container容器。
任务运行
NM分别启动MapTask(程序启动代码是由MrAppmaster发送给各个NM来启动相应MapTask),MapTask对数据分区排序 ---- >执行完之后输出文件(一个MapTask输出一个分区且内部有序的文件),执行完之后它们的Container就会被回收;
MrAppmaster等待所有的MapTask运行完毕之后,进一步根据分区文件的数量 job设置的数量向RM申请相应的ReduceTask容器 ---->ReduceTask向MapTask获取相应分区数据,把相应数据下载到本地开始执行,它执行完后它的Container被回收;
---->把最后结果写到HDFS中;----最后程序执行完之后MrAppMaster向RM注销自己,Container被回收;
进度和状态更新
YARN中的任务将其进度和状态(包括counter)返回给应用管理器, 客户端每秒(通过mapreduce.client.progressmonitor.pollinterval设置)向应用管理器请求进度更新, 展示给用户。
作业完成
除了向应用管理器请求作业进度外, 客户端每5秒都会通过调用waitForCompletion()来检查作业是否完成。时间间隔可以通过mapreduce.client.completion.pollinterval来设置。作业完成之后, 应用管理器和Container会清理工作状态。作业的信息会被作业历史服务器存储以备之后用户核查。
3、 资源调度器
Hadoop作业调度器主要有三种:FIFO、Capacity Scheduler和Fair Scheduler。Hadoop2.7.2默认的资源调度器是Capacity Scheduler。
1.先进先出调度器(FIFO)

存在的问题:如果有紧急的任务,却要等到前面的先执行完;
2.容量调度器(Capacity Scheduler)

存在的问题:如果queueC很闲,它所占据的资源不会给queueA和queueB;
3.公平调度器(Fair Scheduler)
可插拔(任务可来可不来,可以运行各种任务(如MapReduce| spark等任务))式分层队列
缺额:按照所需要的资源数量来分配资源;
如果queueB中有任务了,而A和C是空闲的,则A和C中的资源会都给queueB(占据集群所有资源),如果C有其他任务了,会从B中抢资源过来;
多级队列叠加:queueB中还可以再分queueD和queueE各占50%,相当于各占整个集群的25%;如果某个任务优先级比较低就可以把它放到队列的深层级处(按队列的层级来管理任务的优先级—公平);
每个队列所占据的资源不是死的,取决于任务的紧迫度;根据任务公平的按比例分配资源;
http://hadoop.apache.org/docs/stable/hadoop-yarn/hadoop-yarn-site/FairScheduler.html
4、 任务的推测执行
1.作业完成时间取决于最慢的任务完成时间
一个作业由若干个Map任务和Reduce任务构成。因硬件老化、软件Bug等,某些任务可能运行非常慢。
思考:系统中有99%的Map任务都完成了,只有少数几个Map老是进度很慢,完不成,怎么办?
2.推测执行机制
发现拖后腿的任务,比如某个任务运行速度远慢于任务平均速度。为拖后腿任务启动一个备份任务,同时运行。谁先运行完,则采用谁的结果。
3.执行推测任务的前提条件
(1)每个Task只能有一个备份任务
(2)当前Job已完成的Task必须不小于0.05(5%)
(3)开启推测执行参数设置。mapred-site.xml文件中默认是打开的。
4.不能启用推测执行机制情况
(1)任务间存在严重的负载倾斜;(数据量大,再启动一个也是没用的)
(2)特殊任务,比如任务向数据库中写数据。(两个Task写同样的,会产生冲突)
算法原理

Hadoop企业优化

看什么导致的Map运行时间过长;加快Map、开启Map| Reduce共存;
小文件过多可使用combineTextFormat、打Ha包、最好不弄小文件;
压缩以后文件不可分块会导致map阶段过长;
Spill溢出次数过多,把环形缓冲区改大;Merge合并,如要合并20个文件,先合并前10个,然后把合并的放到文件末尾,剩下11个文件,再取前10个合并,剩2个,再把它俩合并;较少merger次数,一次多合并几个文件;
MapReduce优化方法
MapReduce优化方法主要从六个方面考虑:数据输入、Map阶段、Reduce阶段、IO传输、数据倾斜问题和常用的调优参数。
1.数据输入:

处理小文件慢:处理小文件的计算开销< 建立虚拟机JVM的开销,一次MapTask就要建立一次JVM;JVM重用,一个MapTask运行完一个数据不会立刻被杀掉,再运行一段其他数据,因为同一个任务的Map阶段都是一样的,处理2条数据分配资源只分配一次,规避了资源分配>>事务处理的时间;
2.Map阶段

io.sort.mb、sort.spill.percent 由100M,0.8 --->500M,0.95
开多少个线程取决于磁盘的能力
3.Reduce阶段


4. IO传输

5.数据倾斜


spark采用的方法是缩放key的粒度;
HDFS小文件优化方法
HDFS小文件弊端
HDFS上每个文件都要在NameNode上建立一个索引,这个索引的大小约为150byte,这样当小文件比较多的时候,就会产生很多的索引文件,一方面会大量占用NameNode的内存空间,另一方面就是索引文件过大使得索引速度变慢。
HDFS小文件解决方案
小文件的优化无非以下几种方式:
(1)在数据采集的时候,就将小文件或小批数据合成大文件再上传HDFS。
(2)在业务处理之前,在HDFS上使用MapReduce程序对小文件进行合并。
(3)在MapReduce处理时,可采用CombineTextInputFormat提高效率。


JVM重用内存不会立即释放,JVM中内存靠GC回收但它并不能保证内存100%回收。