Hadoop2之YARN介绍
一、简介
Hadoop2.x主要由HDFS、YARN和MapReduce三部分组成,其架构图如图1.1所示。
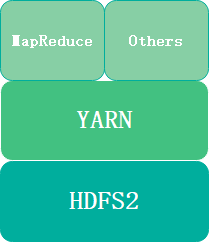
图1.1Hadoop三大组件架构图
YARN是一个独立的分布式资源管理与调度系统,可以为上层的应用提供统一的资源管理和调度。
其中ResourceManager是负责所有资源的监控、分配和管理;ApplicationMaster负责每一个具体的作业的管理器;NodeManager是每台机器的一个节点管理器,Container是由RM抽象出来的资源(节点、内存、CPU)的封装,关系图如图1.2所示。
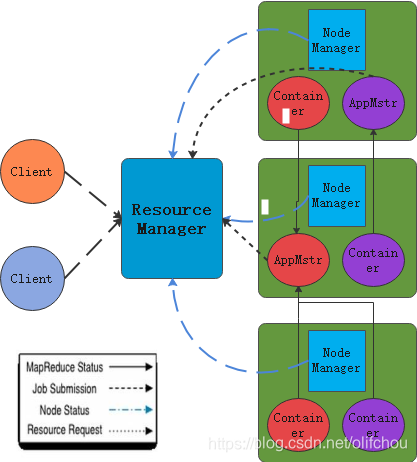
图1.2各组件关系图
二、ResourceManager
ResourceManager(RM)代替了集群管理器,主要由ApplicationManager和Scheduler两部分组成,
- ApplicationManager
ApplicationManager主要负责:
(1)、接收任务提交(Job-submissions);
(2)、协商第一个container来执行应用程序的ApplicationMaster;
(3)、为失败的ApplicationMaster Container提供重启服务。
附:ApplicationManager主要维护了已提交的应用的集合,在任务提交后,他首先校验application所需要的资源同时回绝掉自己没有充分资源去运行的application,此外,ApplicationManager也维护了一个先进先出的缓存来存储已完成的application,当缓存满后,有新的任务完成要存入缓存时,最老的已完成的application将会移出。 - Scheduler
Scheduler主要负责向各个运行中的应用程序(Application)分配合适的资源(familiar constraints of capacities, queues etc),不负责应用程序的监控和状态追踪,不保证对失败的task进行重启
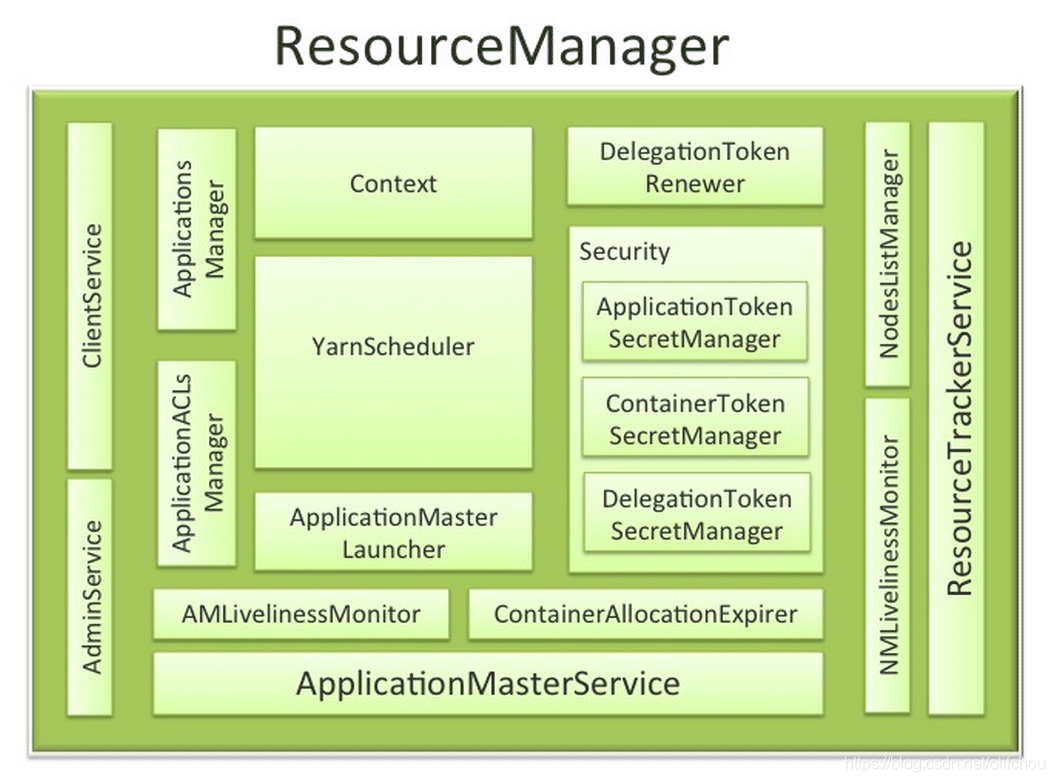
图2.1 ResourceManager内部结构图(来源于StackOverflow)
三、NodeManager
NodeManager(NM)代替了Hadoop 1.x中的TaskTracker,NM属于Slave进程,与TaskTracker类似,相当于是机器框架的封装,其主要工作如下:
- NM处理RM分配的任务请求;
- NM接收并处理来自ApplicationMaster的Container启动、停止等各种请求;
- 负责启动应用程序的Container(执行应用程序的容器),并监控资源的使用情况,通过心跳向RM进行汇报;
总的来看,NM就是单节点上进行资源管理和任务管理。
四、ApplicationMaster
ApplicaitonMaster是应用程序的Master,每一个应用对应一个AM(每一个Job都有一个AM,以一个普通的Container身份运行在RM以外的机器上),在用户提交一个应用程序时,一个AM的轻量型进程实例会启动,AM协调应用程序内的所有任务的执行。
- AM负责一个Job生命周期内的所有工作,类似旧的JobTracker;
- 与RM协商资源,与scheduler协商合适的Container;
- 与NM协同工作,与Scheduler协商合适的Container,并进行对Container监控。
五、Application Manager
应用程序管理器负责管理整个系统中的所有应用程序,包括应用程序的提交、与Scheduler协调资源启动AM、监控AM运行状态及失败时重启AM、跟踪分给的Container的进度与状态。
六、Container
Container是任务运行环境的抽象封装,主要描述任务的运行资源(节点、内存与CPU)、启动命令和运行环境,本质上其只是使用NM上指定资源的权利,AM必须向NM提供更多的信息来启动Container。
七、YARN运行过程
- step1——clients向Resource Manager提交一个任务(Job-submissions);
- step2——Resource Manager中的Application Manager处理clients的任务提交请求,然后Resource Manager向Scheduler协商第一个container资源来运行Application Master实例;
- step3——Application Master根据实际需要向Resource Manager中的Scheduler请求更多的Container资源;
- step4——Application Master通过获取到的Container资源执行分布式计算。
八、Yarn的容错能力
- Resource Manager
RM可通过Zookeeper来实现HA高可用集群,主节点提供服务,从节点实时同步主的信息,当主挂掉,从节点将接替主节点的角色。 - NodeManager
NM与RM之间进行心跳检验,一旦挂掉,RM将立马通知AM,AM将会进行相关处理。 - ApplicationMaster
一般由ResourceManager进行恢复,同时会恢复至故障任务的状态。
九、Yarn调度器
-
FIFO Scheduler
按照提交的顺序进行处理,优点:最简单,缺点:大应用占用所有的集群资源,不适合共享集合。
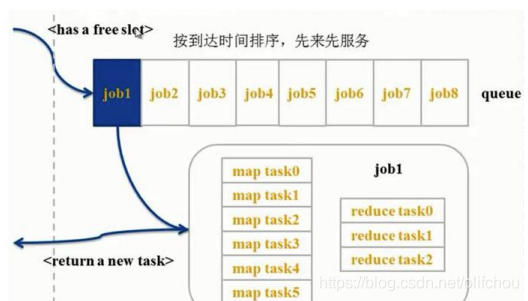
图9.1 FIFO调度器 -
Capacity Scheduler
有一个专有队列运转小任务,预先会占用一定集群资源,缺点:大任务执行时间落后于FIFO。

图9.2 Capacity 调度器 -
Fair Scheduler
用户之间所占资源平分,用户提交的job所占资源平分用户所获得的资源,好处:不需要独占,动态调整,公平共享。
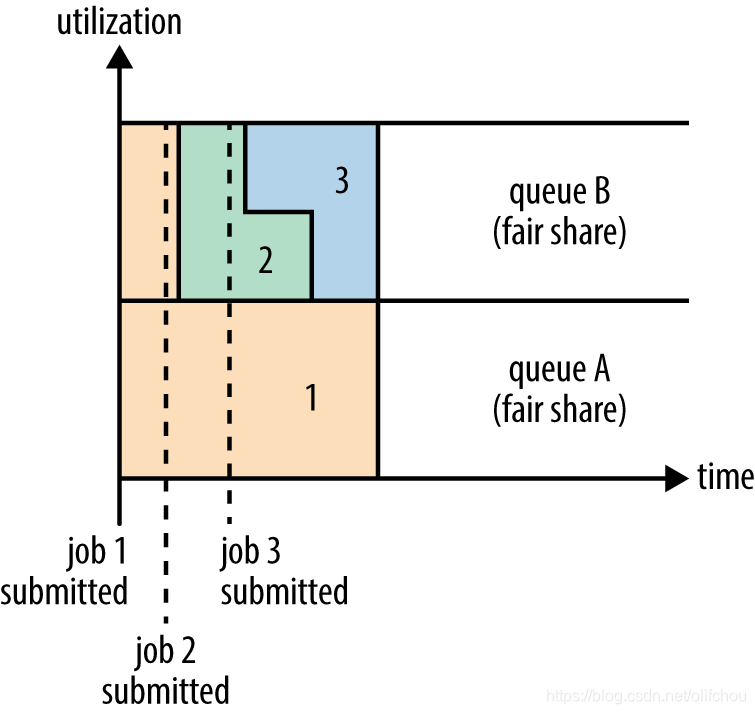
图9.3 fairs 调度器
十、结语
有关知识点与图片来源于网络,如有侵权请私信告知。
此外,不足之处,敬请指正!
