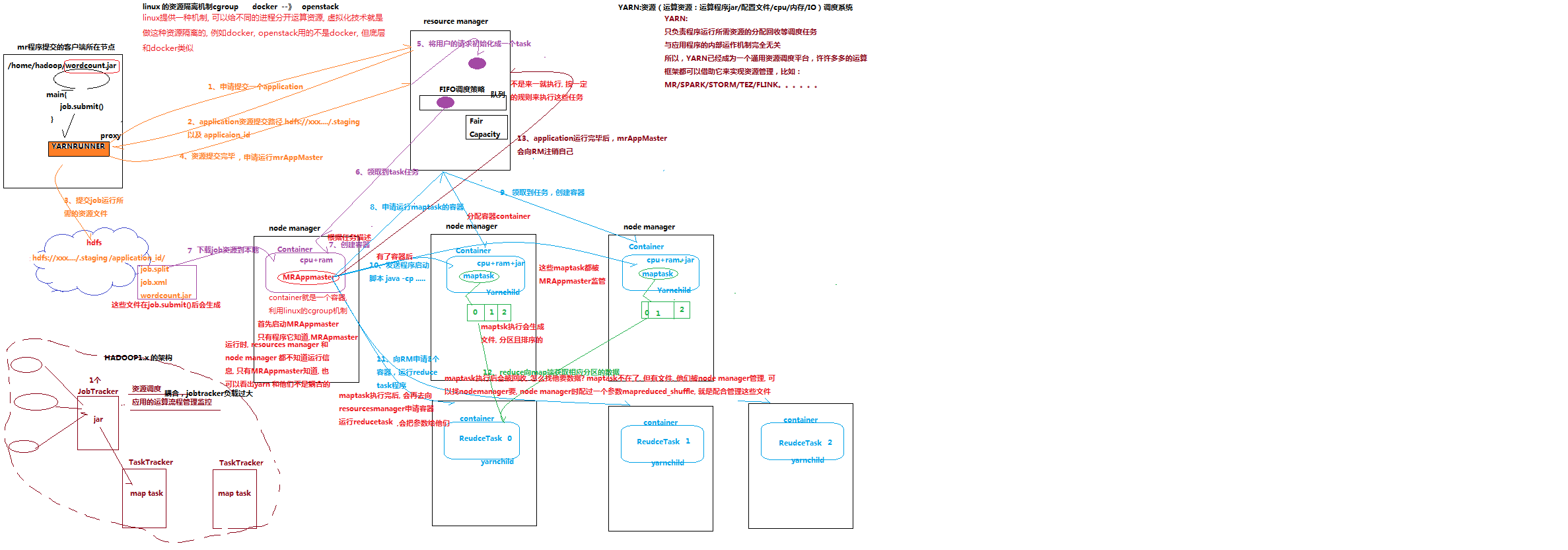
从该原理图中可以知道:在hadoop2的版本中:resource manager也就是YARNz是只负责资源的调度和回收而不参与应用程序的内部运作机制与运算,而在hadoop1的版本中,resourc manager不但要负责资源的调度和回收还要参与具体的运算。
在hadoop2中resouce manager接收用户的请求并分配地址和响应的id给用户,告诉浏览器将文件上传到分配的地址中;而 node manager会创建一个容器并下载用户上传的数据源
,但是resource manager 和node manager都是不知道具体的运算过程。只有mapmaster去执行具体的运行和运作;当maptask执行完之后,会再次向resource manager申请reducetask去执行reduce阶段,而且reducetask会将maptask执行的数据下载到reducetask上面;最后执行完毕的maptask和reducetask会有YARN进行回收。
也就是说在yarn的调度机制中重要的参与者有这几部分:第一部分就是mapreduce程序提交的客户端所在节点:这一部分主要是用来提交数据和向resource manager申请数据提交地址和id 的。第二部分就是resource manager也就是yarn主要负责node manager的调度和资源分配以及执行完之后的资源回收;第三部分就是nodemanager主要是下载用户提交的数据和创建容器用于执行任务以及向resourcemanager申请maptask的,这个容器contioner里面有一个mrappmaster就是分配虚拟机的cpu和内存以及向resourcemanager申请maptask的,只有这个mrapptasker才是具体的执行者,相当于一个公司里面的干活的;当maptask执行完后,mrapptasker会向resourcemanager申请reducetask来执行reduce的任务;最后所有的任务完成之后有yarn回收资源。