并查集
并查集我个人认为一种用来处理某些特殊数据结构的算法,其优点在于程序简短,能够快速简洁的表达出点与点,数于数之间的关系。
这种算法有两个操作,合并与查询
- 合并:能够高时效的将某一些符合题目要求的数据合并在一个集合中
- 查询:能够高时效的查询某个指定数据是否存在于某个集合之中,或者是计算满足题目要求的集合数量
那么这个算法是如何运作的呢?
接下来我们看几道例题
例题1.亲戚
这是一道十分简单的并查集入门题,这里用来讲述并查集的运作思路。
根据题意,如果B是A的亲戚,C是B的亲戚,那么ABC三个人互为亲戚,也就是说ABC三个节点可以被放置在同一个集合当中,为了方便表述,我们可以认为这是一颗树,A是根,B是A的子节点,C是B的子节点。
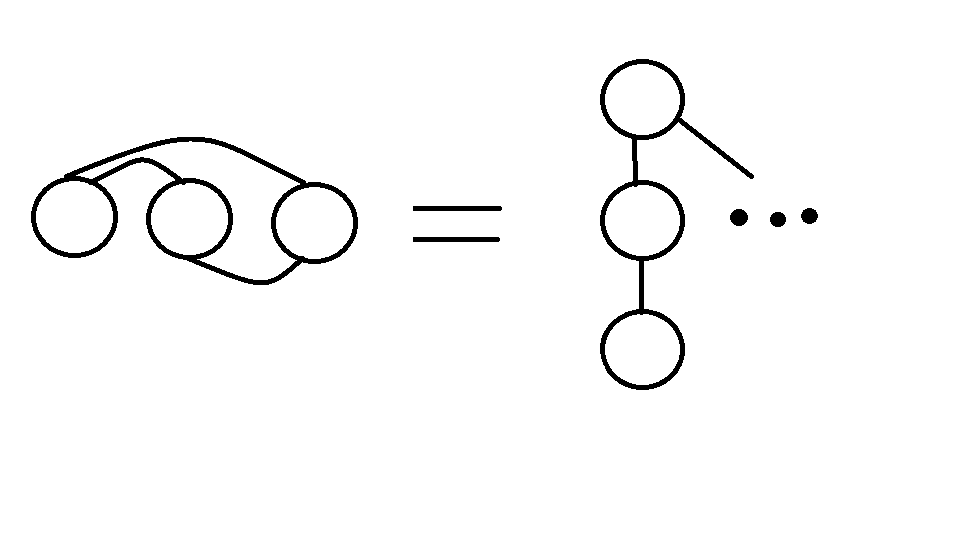
由此,我们便可以利用并查集,将有亲戚关系的两个节点,进行建边,即将两个有亲戚关系的节点所处的集合进行合并,在查询时,只要利用一个递归,不停向上询问,直到问到自己的根节点,如根节点相同,便是有亲戚关系。
但是,还有一个问题,如此下来某个点都向上询问一遍,将会耗费大量的时间,那么何来高时效之说呢?
这里我们需要对并查集做一个优化,使其能更快的计算出自己的根节点,我称之为缩点,将所有有关系的点都进行直接挂靠,也就是说,构造出一颗深度为2的树,如图。
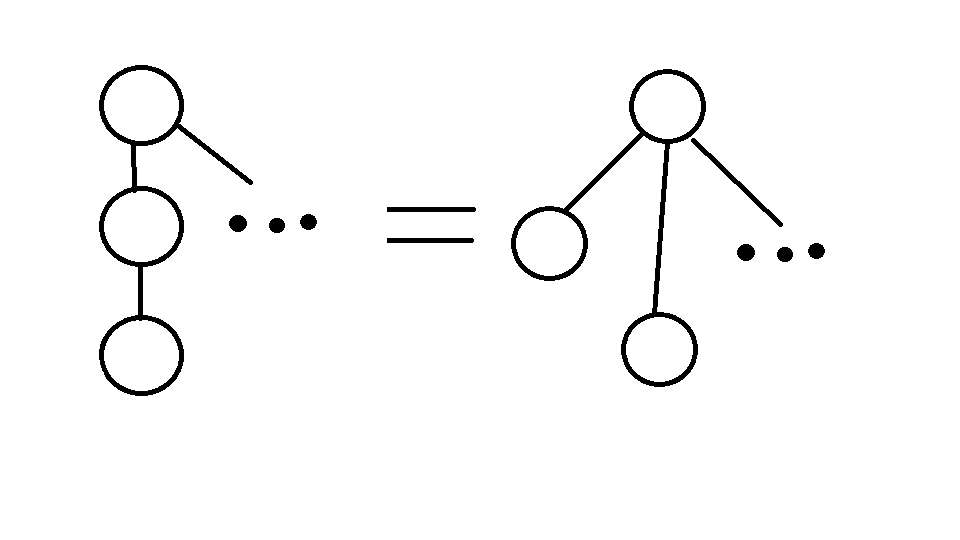
如此一来,在查询的时候就可以直接访问到自己的根节点了。
#include<stdio.h>
#include<algorithm>
int n,m,a,b,fa[10005];
int find(int x){ //查询函数
if(fa[x]!=x) fa[x]=find(fa[x]); //缩点:反复向上询问,询问到根节点才赋值
return fa[x];
}
int main(){
scanf("%d%d",&n,&m);
for(register int i=1;i<=n;i++){fa[i]=i;} //初始化,开始时每个节点都是一个根节点
for(register int i=1;i<=m;i++){
scanf("%d%d",&a,&b);
a=find(a);b=find(b);
if(a!=b) fa[b]=fa[a]; //合并
}
int Q;
scanf("%d",&Q);
for(register int i=1;i<=Q;i++){
scanf("%d%d",&a,&b);
if(find(a)==find(b)) printf("Yes\n"); //根节点相同
else printf("No\n");
}
return 0;
}
通过这道题目,我们可以了解了并查集的基本运行思路,其实很多题的基本代码也是依照这个作为模板,不过在此基础上作出一些变化。
例题2.黑社会团伙
由题意可知,这题与上一题大题框架一样,变化的地方在于
- 求集合数量
- 多出了新的概念,我敌人的敌人也是我的朋友
由新的概念便可以引申出许多新的关系,稍作整理,就有如下几条
- 我朋友的朋友是我的朋友
- 我朋友的敌人是我的敌人
- 我敌人的敌人是我的朋友
- 我敌人的朋友是我的敌人
这时如果仅用原来的单个集合进行计算,就会发现难以表现如上的4种情况,在上一题中,只存在两种情况,是我的亲戚,或者不是,而在该例题中,存在3种情况,是朋友,是敌人,或者两者没有关系。
在上一题中我们用了一棵图来描述人与人之间的亲戚关系,两点之间有建边即为亲戚关系,无建边则没有关系,也就是将有亲戚关系的集合互相合并,那么在这一题中,我们依然可以沿用这样的思路,不过这题我们需要两张图,一张用以表现朋友关系,一张用以表现敌人关系,两张图中的节点可以互相映射。
那么接下来就是编写代码,我们个可以使用n的空间表示朋友,n的空间表示敌人,总共使用2*n的空间。
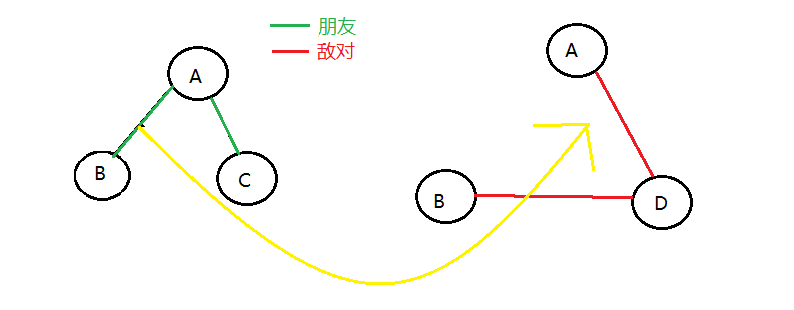
如何编写两棵树之间节点互相的关系映射,假设两人A,B,当A与B是朋友时,在朋友关系图中将B点与A点建边,另外在B的敌人关系图中查找B的敌人,在敌人关系图中将该节点与A节点建边。
假设A与B是朋友,A与C是朋友,B与D是敌人,如图
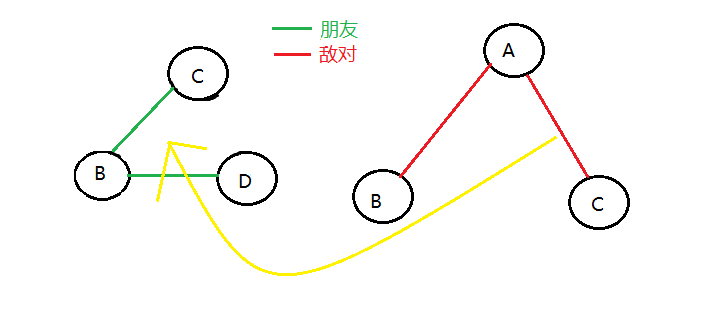
反之,亦可成立,即A与B是敌人时,将B点与A点在敌人关系树中建边,同时,在敌人关系树图中寻找与A有关的节点(除了B),在朋友关系图中将该节点与B节点建边。
假设A与B是敌人,A与C是敌人,B与D是朋友,如图
假设表示朋友的集合是P,P的反集即表示敌人的集合是D
则用数学的集合语言来表示就是
- A与B是朋友:
- \(P(A) \cup P(B)\) 朋友的朋友是朋友
- \(D(A) \cup D(B)\) 朋友的敌人是敌人
- A与B是敌人:
- \(F(A) \cup P(B)\) 敌人的敌人是朋友
- \(D(A) \cup F(B)\) 敌人的朋友是敌人
然后,再利用缩点来提高代码的运行效率,就可以达到“Ac的真实了!”
但是如何实现上述的关系转化?
Fa数组开2*N空间,然后1对应n+1,2对应n+2,3对应n+3,以此类推,也就是1—n表示集合P,n+1—n+n表示P的反集,集合D,而计算团伙数量只要枚举一下所有的点,看看有几个点的fa数组没有被修改过,因为缩点以后,根节点必定对应他自己,所以计算根节点的数量即为集合数量。
上代码!
#include <stdio.h>
#include <algorithm>
#include <iostream>
int fa[50005];
int find(int a){
if(fa[a]!=a) fa[a]=find(fa[a]); //缩点
return fa[a];
}
int main(int argc, char const *argv[]){
int n,m;scanf("%d%d",&n,&m);
for (register int i = 1; i <= 2*n; ++i){ fa[i]=i; } //初始化
for (register int i = 1; i <= m; ++i){
char cmd;std::cin>>cmd;
int a,b;scanf("%d%d",&a,&b);
if (cmd =='F'){
fa[find(a)]=find(b); //朋友集合相并
fa[find(a+n)]=find(b+n); //敌人集合相并
}else{
fa[find(a+n)]=find(b); //敌人的朋友是敌人
fa[find(b+n)]=find(a); //敌人的敌人是朋友
}
}
int ans=0;
for (register int i = 1; i <= n; ++i){
if(fa[i]==i) ans++; //枚举集团数量
}
printf("%d",ans);
return 0;
}之后还有例题就再扩充吧www
通过上面的例题我们可以看到,并查集的本质其实就是求同存异,将具有某一相同特性或关系的数据合并在同个集合之中,并查集的代码量并不大,但是却能够清楚的描述出我们所需要的数据关系。
我个人认为并查集是一种十分优秀的算法,简短高效,值得去了解和钻研,问题就是你能不能去合理的运用,用得好就是一把利器,削铁如泥。
点赞+关注是阁下对我最大的鼓励!