一、Web Driver原理
WebDriver是按照Client/Server经典设计模式设计的。
简单来说:
Client端是我们的测试脚本,发送http请求给被测浏览器;
Server端就是任意的浏览器,Remote Server用来接收Client端的请求并作出响应,在Reponse中返回执行状态、返回值等信息
-
WebDriver具体的工作流程:
- WebDriver启动目标浏览器并绑定到指定端口。启动的浏览器作为远程服务器Remote Server
- Client端通过CommandExecuter发送http请求给远程服务器的侦听端口(通信协议:the webdriver wire protocal)
- Remote Server远程服务器需要依赖原生的浏览器组件(如:IEDriverServer.exe、chromedriver.exe等)来转化为浏览器的本地(native)调用
-
WebDriver用到的协议:
- 打开浏览器时:HTTP协议
- Client端发送http请求到远程服务器的侦听端口:the webdriver wire protocol
其中:
- 有线协议:指的是从点到点获取数据的方式,是应用层的协议。
- HTTP协议:是用于从服务器传输超文本标记语言HTML到客户端的通信协议。是一个应用层协议,由请求/响应构成,是一个标准的客户/服务器模式。是一个无状态的协议。(无状态:对事务没有记忆能力,不会保存这次传输的信息——节约内存)
二、WebDriver常用方法及操作
1、元素定位方法
Selenium提供了8种定位方式:
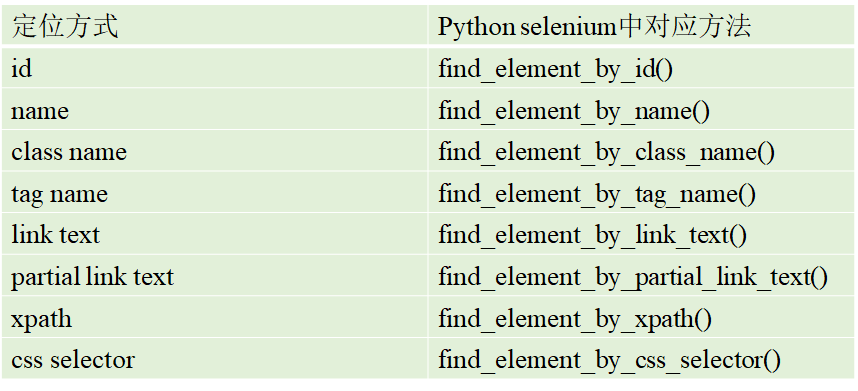
针对以上方法做以下说明:
- id定位:在HTML中规定id属性在HTML文档中必须是唯一的,类似于公民身份证号码,具有很强的唯一性。
- name定位:name用来指定元素的名称,name的属性值在当前页面中可以不唯一。
- class定位:class指定元素的类名。
- tag定位:HTML的本质就是通过tag来定义实现不同的功能,每个元素本质上也是一个tag。因为一个tag往往用来定义一类功能,所以通过tag识别某个元素的概率很低。
- link定位:专门用来定位文本链接。通过元素标签对之间的文本信息来定位元素。
- partial link定位:对link定位的一种补充,考虑到有些文本链接比较长,所以取其中一部分定位,只要可以唯一标识这个链接即可。
在实际项目中,有时一个元素并没有id、name属性,又或者页面上多个元素id、name属性值相同,又或者每一次刷新页面,id值都会随机变化,针对这些情况,selenium采用以下方式来定位:
- XPath定位:XPath是一种在XML文档中定位元素的语言。HTML可以看作XML的一种实现。
- 绝对路径定位:使用标签名的层级关系来定位元素的绝对路径
1 find_element_by_xpath("/html/body/div/div[2]/div/div/div/from/span/input")
- 利用元素属性定位:
1 find_element_by_xpath("//input[@id='kw']") 2 find_element_by_xpath("//input[@name='wd']")
3 find_element_by_xpath("//*[@id='kw']")
- 层级与属性结合
1 find_element_by_xpath("//span[@class='bg_s_ipt_wr']/input") 2 find_element_by_xpath("//form[@id='fprm']/span/input")
- 使用逻辑运算符
find_element_by_xpath("//input[@id='kw' and @class='su']/span/input")
- CSS定位:
- 用By定位元素:除以上八种定位方法外,还提供统一调用find_element()方法,通过By来声明定位的方法,并传入对应定位方法的定位参数,需要两个参数,定位类型,定位具体方式。底层其实是上面八种方法
find_element(By.ID,“kw”) find_element(By.NAME,“wd”) find_element(By.CLASS_NAME,“s_ipt”) find_element(By.TAG_NAME,“input”) find_element(By.LINK_TEXT,“新闻”) find_element(By.PARTIAL_LINK_TEXT,“新”) find_element(By.XPATH,"//[@class='bg s_btn']") find_element(By.CSS_SELECTOR,"span.bg s_btn_wr>input#su")