进程池、线程池:
开进程池和线程池都是要消耗资源的,只不过比较而言消耗的资源进程池多一点,线程池少一点
就是在计算机硬件能承受的最大范围内去利用计算机。
什么是池?
就是在保证计算机硬件安全的情况最大利用计算机。
因为计算机硬件的发展跟不上软件的速度。
作用:
1.自动管理了进程/线程的开启和销毁
2.自动管理分配任务
3.限制了进程/线程的创建数量,信号量只是限制了最大并发线程访问数量,线程已经创建了。
就是可以对线程/进程进行回收,
池子中创建的进程/线程创建一次就不会再创建了
从始至终使用都是那几个,这样就节省了开启线程进程的资源
使用:
submint()是提交任务
pool.shutdown() # 等待所有任务全部完毕 销毁所有线程 后关闭线程池


def task(n): print(n,os.getpid()) # 查看当前进程号 time.sleep(2) return n**2 def call_back(n): print('拿到了异步提交任务的返回结果:',n.result()) """ 提交任务的方式 同步:提交任务之后 原地等待任务的返回结果 期间不做任何事 异步:提交任务之后 不等待任务的返回结果(异步的结果怎么拿???) 直接执行下一行代码 """ # pool.submit(task,1) # 朝线程池中提交任务 异步提交 # print('主') """ 异步回调机制:当异步提交的任务有返回结果之后,会自动触发回调函数的执行 """ if __name__ == '__main__': t_list = [] for i in range(20): res = pool.submit(task,i).add_done_callback(call_back) # 提交任务的时候 绑定一个回调函数 一旦该任务有结果 立刻执行对于的回调函数 # print(res.result()) # 原地等待任务的返回结果 t_list.append(res) # pool.shutdown() # 关闭池子 等待池子中所有的任务执行完毕之后 才会往下运行代码 # for p in t_list: # print('>>>:',p.result())
协程:
就是单线程下实现并发。
也叫轻量级线程。
并发:就是看上去是并行,其实是切换加保存执行
并行:就是真正意义上的同时进行。
IO密集用多线程
计算密集用多进程
首先我们可以使用生成器完成并发执行
def task1(): while True: yield print("task1 run") def task2(): g = task1() while True: next(g) print("task2 run") task2()
优点:协程的创建开销更小,属于程序级别的,操作系统完全感知不到。
单线程下就能实现并发执行,最大限度使用cpu
gevent模块:
import gevent,sys from gevent import monkey # 导入monkey补丁 monkey.patch_all() # 打补丁 import time print(sys.path) def task1(): print("task1 run") # gevent.sleep(3) time.sleep(3) print("task1 over") def task2(): print("task2 run") # gevent.sleep(1) time.sleep(1) print("task2 over") g1 = gevent.spawn(task1) g2 = gevent.spawn(task2) #gevent.joinall([g1,g2]) g1.join() g2.join()
如果没有join的话,执行以上代码不会有任何信息,因为协程的任务都是以异步的方式提交的,所以主线程会继续执行代码,直到运行完最后一行便会结束主进程。这就导致了协程的任务没有及时执行,所以这个时候我们要用join来保证协程内的代码执行完毕后才会执行主线程,当然如果主线程不会结束那么也就不需要调用join。
注意:
1.如果主线程结束了 协程任务也会立即结束。
2.monkey补丁的原理是把原始的阻塞方法替换为修改后的非阻塞方法,即偷梁换柱,来实现IO自动切换
必须在打补丁后再使用相应的功能,避免忘记,建议写在最上方
IO模型:
总共有五种IO:
blocking IO 阻塞IO
nonblocking IO 非阻塞IO
IO multiplexing IO多路复用
signal driven IO 信号驱动IO
asynchronous IO 异步IO
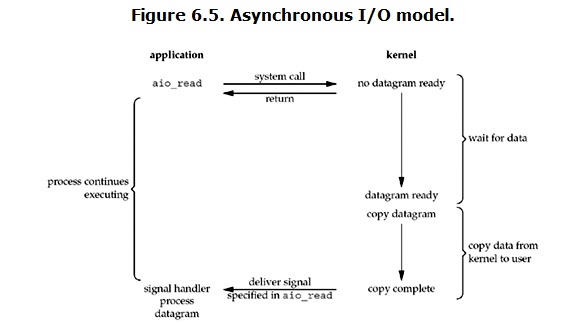
阻塞IO:
在linux中,默认情况下所有的socket都是blocking,一个典型的读操作流程大概是这样:
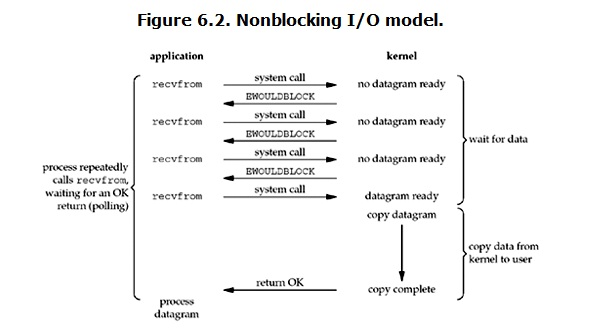
非阻塞IO:
Linux下,可以通过设置socket使其变为non-blocking。当对一个non-blocking socket执行读操作时,流程是这个样子:
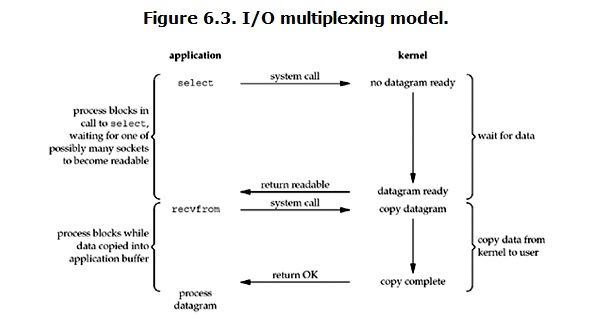
IO多路复用:
IO multiplexing这个词可能有点陌生,但是如果我说select/epoll,大概就都能明白了。有些地方也称这种IO方式为事件驱动IO(event driven IO)。我们都知道,select/epoll的好处就在于单个process就可以同时处理多个网络连接的IO。它的基本原理就是select/epoll这个function会不断的轮询所负责的所有socket,当某个socket有数据到达了,就通知用户进程。它的流程如图:
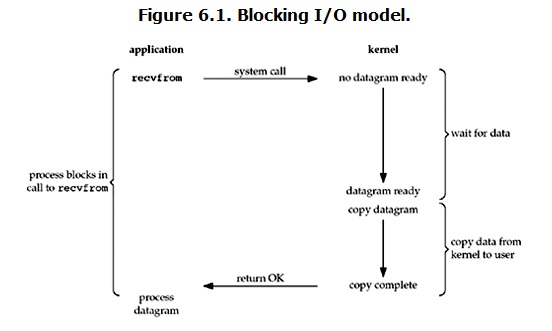
异步IO(ASYN开头的):
Linux下的asynchronous IO其实用得不多,从内核2.6版本才开始引入。先看一下它的流程: