day33进程池和线程池
0.内容回顾


1 """""" 2 """ 3 昨日内容回顾 4 """ 5 6 """ 7 1.TCP服务端实现并发 8 1.将不同的功能尽量拆分成不同的函数 9 拆分出来的功能可以被多个地方使用 10 1.将连续循环和通信循环拆分成不同的函数 11 2.将通信循环做成多线程 12 13 ps: 14 1.端口报错解决策略: 15 server.setsockopt(socket.SOL_SOCKET,socket.SO_REUSEADDR,1) 16 2.线程并发,在同一个端口下进行 17 进程并发不同端口快速切换,进程需要进行快速回收 18 19 """ 20 21 """ 22 2.GIL(全局解释器锁) 23 1.在CPython解释器才有GIL的概念,不是Python的特点 24 2.GIL也是一把互斥锁,将并发变为串行,牺牲了效率,但是提高了数据的安全性 25 26 ps: 27 1.针对不同的数据 应该使用不同的锁去处理 28 2.自己不要轻易的处理锁的问题 哪怕你知道acquire 和 release 29 当业务逻辑稍微复杂的一点情况下 极容易造成死锁 30 31 CPython中GIL锁的存在是因为Python的内存管理不是线程安全的 32 """ 33 """ 34 3.内存管理 35 1.引用计数:值与变量的绑定关系的个数 36 2.标记清除: 37 当内存快要满的时候 会自动停止程序的运行 38 检测所有的变量与值的绑定关系, 39 给没有绑定关系的值(即:计数=0,)打上标记,最后一次性清除 40 3.分代回收: 41 (垃圾回收机制也是需要消耗资源的, 42 而正常一个程序的运行内部会使用到很多变量与值, 43 44 并且有一部分类似于常量(一般不变,是可以变的), 45 减少垃圾回收消耗的时间,应该对变量与值的绑定关系做一个分类>>>:) 46 新生代(5s)>>> 青春代(10s)>>> 老年代(20s) 47 垃圾回收机制扫描一定次数发现关系还在, 会将该对关系移至下一代 48 随着代数的递增,扫描次数(频率)在降低 49 50 """ 51 """ 52 4.同一个进程下多个线程能否同时运行? 53 GIL类似于是加在解释器上的锁,随着解释器调用加锁,故:无法在同一个进程下运行多个线程. 54 55 GIL释放的三个时机: 56 1.解释器调用结束 57 2.遇到IO操作 58 3.使用超过解释器默认最长时间 59 """ 60 """ 61 5.死锁与递归锁 62 死锁: 63 有两把锁,客户1持有A锁,B锁在其他人手中,但是逻辑为客户1继续拿B锁,方才能按照先进后出解锁,其他人也需要A锁才能正常解锁运行, 64 此时各持一把,进入"死锁状态". 65 没有解决方法,只有避免方法---"递归锁RLock" 66 即:本质使用同一把锁,多次加锁+1 释放-1 两次次数相同 67 68 递归锁: 69 可以被第一抢到的人该锁的人多次的acquire 和release,内部会有一个计数 70 acquire : + 71 release : - 72 当别人再抢这把锁的时候,只要"计数!=0" 就永远也抢不到 73 74 """ 75 """ 76 6.信号量: 77 如果: 78 互斥锁: 单个卫生间 79 信号量: 多个卫生间 80 81 即:解决并发数据 安全问题 -- 批量解决 82 from threading import Semaphore 83 from multiprocessing import Semaphore 84 sm = Semaphore(3) 85 参数为批量处理的具体数目 86 """ 87 from threading import Semaphore 88 from multiprocessing import Semaphore 89 sm = Semaphore(3) 90 """ 91 7.event 事件 92 e = Event() 93 e.wait() 等待信号 94 e.set() 发送信号 95 """ 96 """ 97 8.线程q(队列) 98 1.Queue # 队列 99 2.LifoQueue # 堆栈 100 3.PriorityQueue # 优先级(数字越小,优先级越高,参数为元组) 101 """
2.TCP服务端实现并发
1 import socket 2 import os 3 client = socket.socket() 4 client.connect(('127.0.0.1',9114)) 5 while True: 6 # for i in range(3): 7 client.send('haha'.encode('utf-8')) 8 date = client.recv(1024) 9 date = date.decode('utf-8') 10 print(date)
1 import socket 2 import os 3 from threading import Thread 4 from multiprocessing import Process 5 server = socket.socket() 6 server.setsockopt(socket.SOL_SOCKET,socket.SO_REUSEADDR,1) 7 server.bind(('127.0.0.1',9114)) 8 server.listen(5) 9 10 def task(conn,i): 11 while True: 12 try: 13 date = conn.recv(1024) 14 # print(date.decode('utf-8'),'线程%s'%i) 15 print('son:%s'%os.getpid()) 16 # print('father:%s'%os.getppid()) 17 conn.send(date.upper()) 18 except ConnectionResetError as e: 19 print(e) 20 break 21 conn.close() 22 if __name__ == '__main__': 23 24 while True: 25 conn,addr = server.accept() 26 27 t_list = [] 28 for i in range(10): 29 # t = Thread(target=task,args=(conn,i,)) 30 t = Process(target=task,args=(conn,i,)) 31 print('主:%s' % os.getppid()) 32 t_list.append(t) 33 t.start() 34 35 for p in t_list: 36 p.join() 37 print(p)
端口未及时回收.png

解决方法:
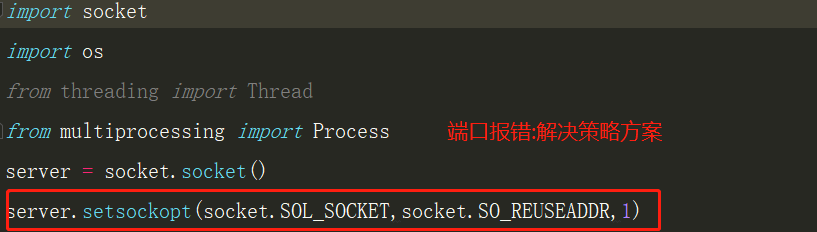
1.进程池和线程池
1 """""" 2 """ 3 1.什么是池? 4 在保证硬件安全的情况下,最大限度的利用计算机 5 池其实是降低程序的运行效率 但是保证了计算机硬件的安全 6 (出现的原因 :硬件的发展跟不上软件的速度) 7 """ 8 9 """ 10 2.池子创建的过程(进程池/线程池), 11 创建一次就不会再创建了, 12 至始至终用的都是最初的那几个. 13 这样的话节省了反复开辟(进程池/线程池)所消耗的资源 14 15 """
1 """""" 2 """ 3 2.线程池 4 """ 5 from concurrent.futures import ThreadPoolExecutor 6 7 """ 8 pool = ThreadPoolExecutor() 9 # 1.括号内可以传参数指定线程的个数 10 # 2.也可以不传,不传默认是当前所在计算机上 "cpu个数 " * 5 11 """ 12 pool = ThreadPoolExecutor() 13 """ 14 池子中创建的线程创建一次就不会再创建了 15 至始至终用的都是最初的那几个 16 这样的话节省了反复开辟线程的资源 17 """ 18 import time 19 import os 20 def task(n): 21 print(n,os.getpid()) # 查看当前进程号 22 time.sleep(0.1) 23 return n ** 2 24 25 26 27 28 """ 29 提交任务的方式: 30 同步: 31 提交任务之后, 32 原地等待任务的返回结果, 期间不做任何事 33 异步: 34 提交任务之后 35 不等待任务的返回结果(异步的结果怎么拿???)直接执行下一行代码 36 """ 37 """ 38 异步: 39 # 朝线程池中提交任务 40 pool.submit(task, 1) # 异步提交 41 """ 42 # # 朝线程池中提交任务 43 # pool.submit(task,1) # 异步提交 44 # print('主') 45 # ''' 46 # 1 20532 47 # 主 48 # ''' 49 t_list = [] 50 for i in range(8): 51 res = pool.submit(task,i) 52 t_list.append(res) 53 #print(res) 54 #print(res.result()) 55 pool.shutdown() # 关闭池子 等待所有的任务执行之后,才往下走 56 for p in t_list: 57 print('>>>:',p) # 得到对象 58 print('>>>:',p.result()) # 取值 59 60 """ 61 0 21884 62 1 21884 63 2 21884 64 >>>: <Future at 0x25aa9f526a0 state=finished returned int> 65 >>>: 0 66 >>>: <Future at 0x25aaa2771d0 state=finished returned int> 67 >>>: 1 68 >>>: <Future at 0x25aaa27d4a8 state=finished returned int> 69 >>>: 4 70 71 """
1 """""" 2 from concurrent.futures import ProcessPoolExecutor 3 import time 4 """ 5 pool = ProcessPoolExecutor() 6 # 1.括号 可以 传参 指定进程池的 进程个数 7 # 2.也可以不传 不传默认是当前计算机 CPU的个数 8 """ 9 pool = ProcessPoolExecutor() 10 """ 11 池子中创建的进程创建一次就不会再创建了 12 至始至终用的都是最初的那几个 13 这样的话节省了反复开辟进程的资源 14 """ 15 import os 16 def task(n): 17 print(n, os.getpid()) # 查查看当前进程号 18 print(n,os.getppid()) # 查看父进程号 19 time.sleep(0.1) 20 return n ** 2 21 22 """ 23 提交任务的方式: 24 同步: 25 提交任务之后, 26 原地等待任务的返回结果, 期间不做任何事 27 异步: 28 提交任务之后 29 不等待任务的返回结果(异步的结果怎么拿???)直接执行下一行代码 30 """ 31 """ 32 异步: 33 # 朝线程池中提交任务 34 pool.submit(task, 1) # 异步提交 35 """ 36 # # 朝线程池中提交任务 37 # pool.submit(task,1) # 异步提交 38 # print('主') 39 # ''' 40 # 1 20532 41 # 主 42 # ''' 43 if __name__ == '__main__': 44 45 t_list = [] 46 for i in range(40): 47 res = pool.submit(task,i) 48 t_list.append(res) 49 #print(res) 50 #print(res.result()) 51 pool.shutdown() # 关闭池子 等待所有的任务执行之后,才往下走 52 for p in t_list: 53 print('>>>:',p) # 得到对象 54 print('>>>:',p.result()) # 取值
1 """""" 2 """ 3 异步回调机制: 4 当异步提交的任务有返回结果之后.会自动触发回调函数执行 5 t = pool.submit(task,i).add_done_callback(call_back) # 异步回调机制 6 """ 7 from concurrent.futures import ThreadPoolExecutor,ProcessPoolExecutor 8 import time 9 import os 10 11 # 1.进程池 12 # pool = ProcessPoolExecutor() 13 # 2.线程池 14 pool = ThreadPoolExecutor() 15 def task(n): 16 print('数字>>>:%s son>>>:%s father>>>:%s'%(n,os.getpid(),os.getppid())) 17 """ 18 数字>>>:0 son>>>:14296 father>>>:22552 19 数字>>>:1 son>>>:14296 father>>>:22552 20 数字>>>:2 son>>>:14296 father>>>:22552 21 数字>>>:3 son>>>:14296 father>>>:22552 22 """ 23 time.sleep(0.1) 24 return n ** 2 25 26 def call_back(n): 27 print('拿到了异步提交任务的返回结果:', n.result()) 28 """ 29 拿到了异步提交任务的返回结果: 0 30 拿到了异步提交任务的返回结果: 1 31 拿到了异步提交任务的返回结果: 4 32 拿到了异步提交任务的返回结果: 9 33 """ 34 """ 35 ps: 36 n.result() /p.result() # 只能取一次结果,连续重复使用,后执行的会报错: 37 AttributeError: 'NoneType' object has no attribute 'result' 38 """ 39 40 if __name__ == '__main__': 41 t_list = [] 42 for i in range(4): 43 t = pool.submit(task,i).add_done_callback(call_back) 44 t_list.append(t) 45 """ 46 pool.shutdown() 关闭池子,等待池子中所有的任务执行完毕之后才会往下运行 47 否则会报错: 48 RuntimeError: cannot schedule new futures after shutdown 49 运行时错误:关闭后无法计划新的预购 50 """ 51 pool.shutdown() 52 for p in t_list: 53 # print(p) 54 ''' 55 print(p) # 对象 56 # 值 57 <Future at 0x22b28b876a0 state=running> 58 <Future at 0x22b28bd3710 state=pending> 59 <Future at 0x22b28bd37b8 state=pending> 60 <Future at 0x22b28bd3860 state=pending> 61 ''' 62 print('>>>:',p.result()) # 取值 63 64 ''' 65 >>>: 0 66 >>>: 1 67 >>>: 4 68 >>>: 9 69 70 '''
异步回调的一句话.png
2.协程
1.协程验证
1 """""" 2 """ 3 进程:资源单位 4 线程:执行单位 5 6 1.什么是协程? 7 协程:单线程下实现并发 8 9 并发 10 切换+保存状态 11 ps:看起来像是同时执行 就可以称之为并发 12 13 协程:完全是程序员自己意淫出来的名词 14 单线程实现并发 15 16 并发的条件: 17 多道技术 18 空间复用 19 时间复用 20 切换+保存状态 21 22 2.协程的内部原理: 23 逻辑: 24 程序员自己通过代码自己检测程序中的IO 25 一旦遇到IO自己通过代码切换 26 给操作系统的感觉是你这个线程没有任何IO 27 ps:欺骗操作系统 28 让他误以为你这个程序一直没有IO 29 从而保证程序在"运行态"和"就绪态"来回切换 30 提升代码的运行效率 31 32 ps: 33 切换+保存状态就一定能提升效率吗??? 34 分情况讨论: 35 1.当你的任务是IO密集型的情况下(避免了阻塞态),提升效率 36 2.当你的任务是计算密集型(本身就是运算,只有达到时间阙值方才切换,切换和保存状态,需要消耗时间),降低效率 37 """ 38 """ 39 yield 保存上一次的结果 40 多进程下开多线程 41 多线程下再开协程 42 """ 43 """ 44 gevent模块 45 """ 46 '''导入''' 47 from gevent import spawn 48 """ 49 ps:gevent模块没办法自动识别time.sleep等IO操作 50 所以需要手动配置一个参数 51 """ 52 """猴子补丁""" 53 from gevent import monkey;monkey.patch_all() 54 """ 55 from gevent import monkey;monkey.patch_all() 56 # 由于该模块经常被使用 所以建议写成一行 57 """
1 """""" 2 """ 3 1.知识点1: 4 验证: 5 6 # 串行 0.00598454475402832 s 7 # yield 并发执行 100.49972939491272 s 8 """ 9 10 """ 11 知识点2 12 """ 13 """gevent 是一个基于协程的Python网络库""" 14 """ 15 # 导入模块 16 from gevent import spawn 17 18 ps: gevent模块无法检测出IO 19 需要手动配置一个参数 20 """ 21 """ 22 from gevent import spawn 23 # 1.检测有无IO,帮忙自动切 24 # 2.但是他不具备检测IO功能,所以引入 "money"猴子模块,即"猴子补丁" 25 """ 26 """ 27 # 知识点3 猴子补丁 28 from gevent import monkey 29 monkey.patch_all() 30 # 由于该模块经常被使用 所以建议写成一行 31 from gevent import monkey;monkey.patch_all() 32 """ 33 """ 34 monkey.patch_all() 35 monkey patch指的是在运行时动态替换, 36 一般是在startup的时候. 37 38 用过gevent就会知道,会在最开头的地方gevent.monkey.patch_all(); 39 把标准库中的thread/socket等给替换掉. 40 这样我们在后面使用socket的时候可以跟平常一样使用,无需修改任何代码,但是它变成非阻塞的了. 41 42 # 解决阻塞的方法,即:切换阻塞态到非阻塞态 -- 猴子补丁 43 """ 44 45 """ 46 47 """ 48 # 导入模块 49 from gevent import spawn 50 from gevent import monkey;monkey.patch_all() 51 import time 52 53 def ha(): 54 print('哈哈哈') 55 time.sleep(0.1) 56 print('哈哈哈') 57 58 def hei(): 59 print('嘿嘿嘿') 60 time.sleep(0.1) 61 print('嘿嘿嘿') 62 63 def he(): 64 print('呵呵呵') 65 time.sleep(0.1) 66 print('呵呵呵') 67 68 start = time.time() 69 """spawn 会检测所有的任务""" 70 # g1 = spawn(ha) 71 # g2 = spawn(he) 72 # g3 = spawn(hei) 73 # g1.join() 74 # g2.join() 75 # g3.join() 76 ha() 77 hei() 78 he() 79 stop = time.time() 80 81 """ 82 # 串行 0.3086245059967041 s 83 哈哈哈 84 哈哈哈 85 呵呵呵 86 嘿嘿嘿 87 哈哈哈 88 嘿嘿嘿 89 哈哈哈 90 呵呵呵 91 嘿嘿嘿 92 嘿嘿嘿 93 呵呵呵 94 呵呵呵 95 3333333333333333333333333333333333 0.3086245059967041 96 """ 97 print('3333333333333333333333333333333333',stop-start) 98 """ 99 协程: # 0.10787224769592285 s 100 101 哈哈哈 102 呵呵呵 103 嘿嘿嘿 104 哈哈哈 105 呵呵呵 106 嘿嘿嘿 107 3333333333333333333333333333333333 0.10787224769592285 108 """ 109 110 """ 111 结论: 112 协程消耗时间更短 ,更节省资源,串行消耗时间较长 113 """
1 """""" 2 """ 3 验证: 4 """ 5 # 串行 0.00598454475402832s 6 7 import time 8 9 def func1(): 10 for i in range(1000): 11 i += 1 12 print(i) 13 def func2(): 14 for i in range(1000): 15 i += 1 16 print(i) 17 start = time.time() 18 func1() 19 func2() 20 stop = time.time() 21 print('11111111111111111111111111111111',stop-start) 22 # 11111111111111111111111111111111 0.00598454475402832s
1 """""" 2 """ 3 基于yield并发执行 4 """ 5 import time 6 def func1(): 7 for i in range(1000): 8 i += 1 9 yield i 10 11 def func2(): 12 g = func1() 13 for i in range(1000): 14 time.sleep(0.1) 15 # 模拟IO ,yield并不会捕捉到并自动切换 i+1 16 i += 1 17 print(i,next(g)) 18 start = time.time() 19 func2() 20 stop = time.time() 21 print('222222222222222222222222',stop-start) 22 # 222222222222222222222222 100.49972939491272s
2.单线程实现TCP并发
1 import socket 2 from threading import Thread,current_thread 3 4 5 def client(): 6 client = socket.socket() 7 client.connect(('127.0.0.1', 9799)) 8 n = 0 9 while True: 10 11 date = "%s %s" % (current_thread().name,n) 12 client.send(date.encode('utf-8')) 13 data = client.recv(1024) 14 print('from server data:', data.decode('utf8')) 15 n += 1 16 for n in range(400): 17 t = Thread(target=client) 18 t.start() 19 #print(t)
1 from gevent import spawn 2 from gevent import monkey;monkey.patch_all() 3 import socket 4 5 server = socket.socket() 6 server.bind(('127.0.0.1',9799)) 7 server.listen(5) 8 9 def task(conn): 10 while True: 11 try: 12 date = conn.recv(1024) 13 if len(date) == 0:break 14 print(date.decode('utf-8')) 15 conn.send(date.upper()) 16 except ConnectionResetError as e: 17 print(e) 18 break 19 conn.close() 20 def severerl(): 21 while True: 22 conn,addr = server.accept() 23 spawn(task,conn) 24 if __name__ == '__main__': 25 26 t1 = spawn(severerl) 27 t1.join()
3.IO模型(了解)
1.png
2.png

3.png
5.png

IO.png
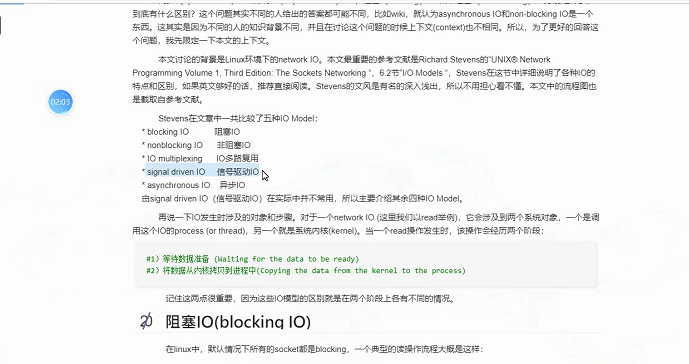
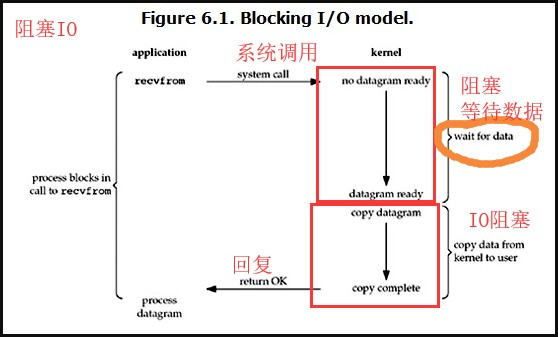
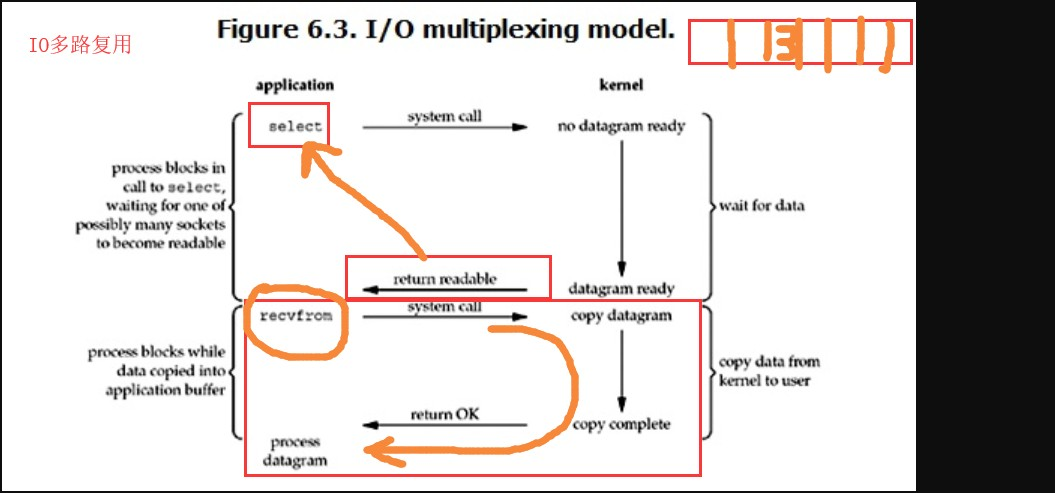
1 """""" 2 """ 3 四种IO模型 4 """ 5 """ 6 1.阻塞IO (图1) 7 系统调用recvfrom 时候 8 (内核)没有收到数据 阻塞 等待数据, 9 收到数据后,复制一份给 "需求方" 10 2.非阻塞IO (图2) 11 12 非阻塞 即 即使遇到了IO操作 也不会阻塞在原地 会继续往下执行 13 server 是一个服务器socket对象 14 server.setblocking(Fasle) 设置为非阻塞 15 问题是: 每次读取数据时 不一定有数据 为了能够及时处理数据 只能不停的询问 忙轮询 16 这种忙轮询的方式,即使没有数据需要处理 也需要不停的循环,造成了无用CPU占用 17 18 3.IO多路复用 (图3) 19 假设原本有30个socket 需要我们自己来处理, 如果是非阻塞IO模型,相当于从头开始问道尾,如果没有需要处理的 20 回过头来再次重复, 21 22 多路复用解决问题的思路,找一个代理即select,将你的socket交给select来检测 23 select 会返回 那些已经准备好的 可读或者可写的socket 24 我们拿着这些准备好的socket 直接处理即可 25 26 对比线程池 27 避免了开启线程的资源消耗 28 缺点: 29 同时检测socket不能超过1024 30 31 4.信号驱动(略) 32 5.异步IO (图5) 33 线程池中的submit 就是异步任务 34 异步的特点就是 立马就会返回 35 同步翻译为sync 异步async 36 """
1 进程池 线程池 2 3 协程 4 5 IO模型(了解)