选择题
1、ls -l 文件的权限,问那些文件可以被任意用户访问、写入之类的

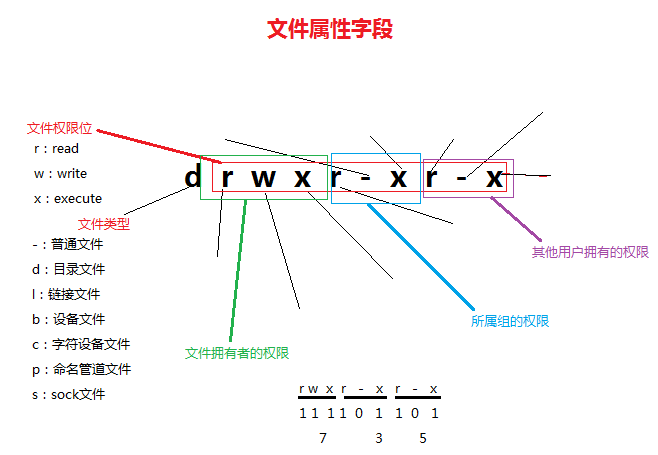
0:当前目录下所有文件所占用空间总和
1:文件属性字段
2:文件硬链接数
3:文件(目录)拥有者
4:文件(目录)拥有者所在的组
5:文件所占用的空间
6:文件最近访问(修改)时间
7:文件名
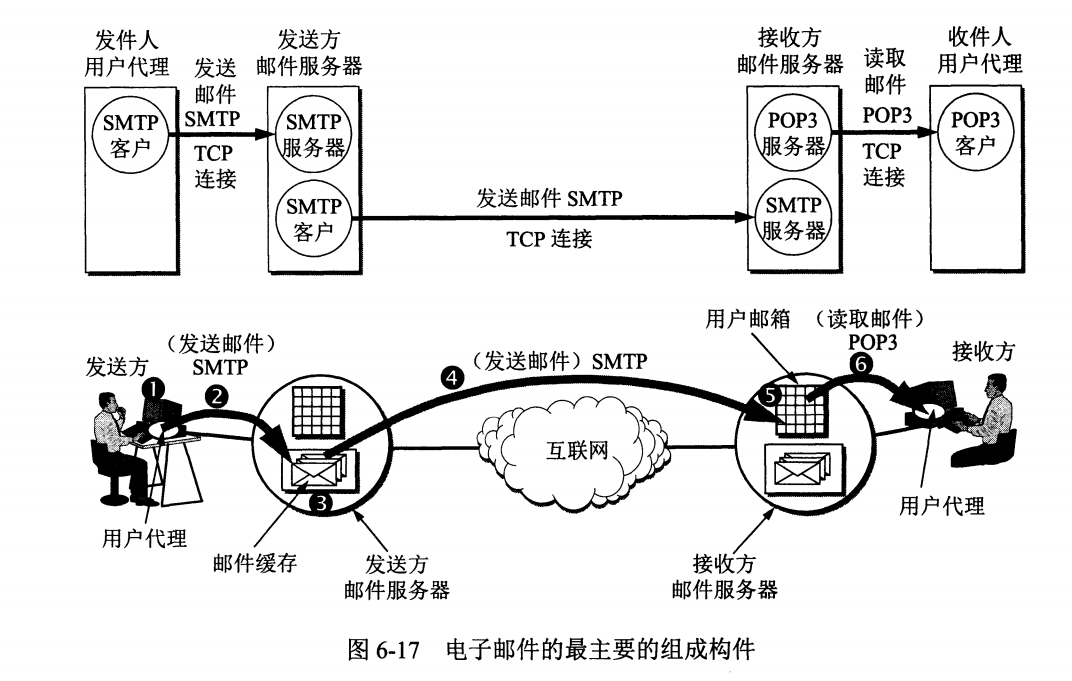
2、邮件发送过程中的邮件协议
3、IP头部长10,数据部分长2000,MTU分别为1500 & 576, 问IP数据要分几次发出?
4、一个select语句的题,求不同统计出某天访问的用户数
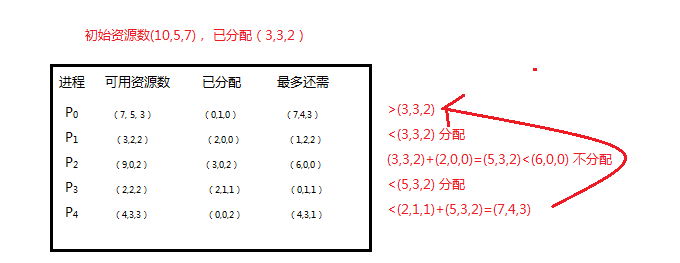
5、有3个临界资源,4个进程共享,各进程对资源的需求为:p1申请R1 和 R2,P2申请 R2 和 R3,P3申请R1 和R3, P4申请R2。 若系统进入死锁状态,则死锁的进程数至少为()
https://blog.csdn.net/u011240016/article/details/53305118
6、判断一个数组是正序、倒叙,需要我们将这个数组完整的遍历一遍通过构建有序序列,对于未排序数据,在已排序序列中从后向前扫描,找到相应的位置并插入的排序算法是
https://blog.csdn.net/kakaluoteyy/article/details/75330033
7、chmod 755 file1 chmod 647 file2
8、Hadoop Mapreduce的正确说法?(D)
mapreuduce的过程
reduce执行的顺序总是先于map?
mapper的数量由输入的文件大小决定?
reduce的数量必须大于0
combiner的过程实际也是reduce的过程
9、用长度为6的数据来实现循环队列,数组下标为[0,5],当前rear & front的值分别为 0 & 3,当从队列中删除一个元素,再加入2个元素,rear & front的值分别为?
10、hadoop的默认调度器: FIFO
late、capacity scheduler、fair scheduler
算法题
https://m.nowcoder.com/discuss/216237?&headNav=www
1、求最大公约数
#include<bits/stdc++.h>
using namespace std;
char s[100005];
long long gcd(long long a,long long b)
{
return a % b == 0 ?b : gcd(b , a % b) ;
}
int main()
{
scanf("%s",s+1) ;
long long a ; cin >> a;
long long b = 0;
for(int i = 1;s[i] != '\0';i++) {
b = (b * 10 + s[i] - '0') % a;
}
cout << gcd(b , a) ;
return 0;
}2、按位或
#include<bits/stdc++.h>
using namespace std;
int p[131072] ;
int mx = 131071 ;
int q ;
int main()
{
scanf("%d",&q) ;
while(q--) {
int op , x;scanf("%d%d",&op,&x) ;
if(op == 1) {
if(p[x] == x) continue ;
int s = mx ^ x;
for(int i = s ; i ; i = (i - 1) & s) {
p[i ^ x] |= x ;
}
p[x] = x;
}
else {
if(p[x] == x) puts("YES") ;
else puts("NO");
}
}
return 0;
}3、最大最小值
输入:
6
1 3 2 4 6 5
#include<bits/stdc++.h>
using namespace std;
multiset<int> st ;
int n , k;
struct num
{
int v ;
int id;
}h[100005];
bool cmp(num a,num b)
{
return a.v < b.v;
}
int L[100005] , R[100005];
int ans[100005];
int main()
{
scanf("%d",&n) ;
for(int i = 1;i <= n;i++) {
scanf("%d",&h[i].v) ;
h[i].id = i;
}
sort(h + 1 , h + n + 1, cmp) ;
for(int i = 1;i <= n;i++) {
L[i] = i - 1,R[i] = i + 1; ans[i] = 2e9;
}
for(int i = 1;i <= n;i++) {
int a = h[i].id - L[h[i].id] - 1 , b = R[h[i].id] - h[i].id - 1 ;
if(a) st.erase(st.find(a));
if(b) st.erase(st.find(b)) ;
st.insert(a + b + 1) ;
L[R[h[i].id]] = L[h[i].id] ; R[L[h[i].id]] = R[h[i].id] ;
multiset<int>::iterator it = st.end() ; it--;
ans[*it] = min(ans[*it] , h[i].v) ;
}
for(int i = n ; i >= 1;i--){
if(ans[i] == (2e9)) ans[i] = ans[i + 1];
}
for(int i = 1;i <= n;i++) printf("%d ",ans[i]) ;
return 0;
}输出:
1 3 3 4 6 6
4、优秀的01序列
#include<bits/stdc++.h>
using namespace std;
char s[1005] , t[1005];
int h[1005];
const int base = 773117 , mod = 1e9 + 7;
int pr[1005];
int s1[1005] , s2[1005] , len;
int pos[1005];
int n , m;
int ghash(int l,int r)
{
return ((h[r] - 1LL*h[l-1]*pr[r-l+1]) % mod + mod ) % mod;
}
int dp[1005][2];
void solve()
{
scanf("%s",s+1);
scanf("%s",t+1);
n = strlen(s + 1) , m = strlen(t + 1) ;
for(int i = 1;i <= m;i++) h[i] = (1LL * h[i - 1] * base + t[i] - '0') % mod;
int pc = 0;len = 0;
for(int i = 1;i <= n;i++) {
if(s[i] != s[i - 1]) {
int h1 = 0 , h2 = 0;
for(int j = i;j <= n;j++) {
h1 = (1LL * h1 * base + s[j] - '0') %mod;
h2 = (1LL * h2 * base + 1 + '0' - s[j]) % mod;
}
if(!pc) {
++len ; s1[len] = h1 ; s2[len] = h2;
}
else {
++len ; s1[len] = h2 ; s2[len] = h1 ;
}
pos[len] = (n - i + 1) ;
pc ^= 1;
}
}
memset(dp , 0 , sizeof(dp)) ; dp[0][1] = 1;
for(int i = 1;i <= m;i++) {
if(i >= pos[1] && ghash(i - pos[1] + 1 , i) == s1[1] && (dp[i - pos[1]][0] || dp[i - pos[1]][1])) dp[i][1] = 1;
for(int j = 2;j <= len;j++) {
if(i >= pos[j] && ghash(i - pos[j] + 1 , i) == s1[j] && (dp[i - pos[j]][0] || dp[i - pos[j]][1])) {dp[i][0] = 1;break;}
}
for(int j = 1;j <= len;j++) {
if(i >= pos[j] && ghash(i - pos[j] + 1 , i) == s2[j] && dp[i - pos[j]][0]) {dp[i][0] = 1;break;}
}
}
if(dp[m][0] || dp[m][1]) puts("YES");
else puts("NO");
return ;
}
int main()
{
int t;scanf("%d",&t) ;
pr[0] = 1;
for(int i = 1;i <= 1000;i++) pr[i] = 1LL * pr[i - 1] * base % mod;
while(t--) solve() ;
return 0;
}问答题
1、对大数据的理解? 通用数据处理架构? 最近接触过的大数据处理架构? 某种场景下的从原理&架构层进行对2种开源技术做对比。
https://blog.csdn.net/wjandy0211/article/details/78802044
对大数据的理解
大数据指无法在一定时间范围内用常规软件工具进行捕捉、管理和处理的数据集合,是需要新处理模式才能具有更强的决策力、洞察发现力和流程优化能力的海量、高增长率和多样化的信息资产。
大数据具有体量大、速度快、种类多、价值密度低的特点,因此,对于海量数据的主要任务是海量数据的存储与数据的挖掘分析。
2、统计页面流量来源:根据refer/上一页的信息去统计,每个pv都有个source去标识。
描述一种offline的计算方法:统计某些页面流量的来源
使用网关组件Kong +Opentracing(Zipkin)将外部访问信息发送到指定的后端接收器中,然后后端接收器将接收到数据对Soruce计算一个Hash值然后的按照规则消费到指定的消息中间件(Kafka 为了可多次消费并可以设置持久还时间)的Topic中,接收完后,利用Hadoop集群进行统计
流量漏斗?
分析出流量源
任意页面的路径分析?
任意页面路径,计算hash然后从历史数据中根据Hash做匹配