现状
Apache Hue 是一个基于 Web 的交互式 SQL 助手,通过它可以帮助大数据从业人员(数仓工程师,数据分析师等)与数据仓库进行 SQL 交互。在 Amazon EMR 集群启动时,通过勾选 Hue 进行安装。在 Hue 启用以后,将原先需要登录主节点进行 SQL 编写及提交的工作转移到 web 前端,不仅方便统一管理日常开发需求,而且保证了集群的接入安全性。另一方面 Hue 自己独特的优势可以使用 SparkSQL 进行 Spark 任务的远程提交,相比于额外为 Amazon EMR 集群配置 Hive on Spark,或者使用代码进行 Livy 远程提交这两种方式而言,大大的提升了开发和运维效率。本文也介绍了如何通过 Hue 整合 Amazon Redshift 数仓, 以及远程提交 Phoenix 任务同 HBase 交互,将 Hue 打造为数据仓库的统一 SQL 访问平台。
| 亚马逊云科技开发者社区为开发者们提供全球的开发技术资源。这里有技术文档、开发案例、技术专栏、培训视频、活动与竞赛等。帮助中国开发者对接世界最前沿技术,观点,和项目,并将中国优秀开发者或技术推荐给全球云社区。如果你还没有关注/收藏,看到这里请一定不要匆匆划过,点这里让它成为你的技术宝库! |
方案架构总览
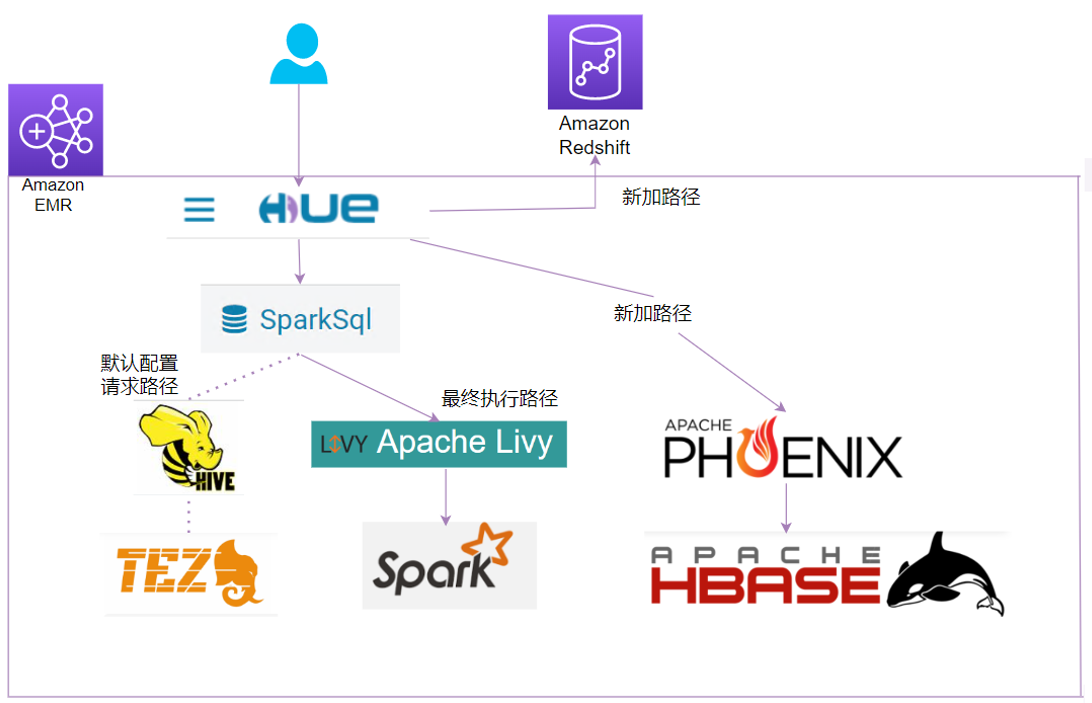
方案介绍
通过 Livy 提交 SparkSQL Job
执行引擎现状
首先,我们简单比对一下几种流行的执行引擎的现状:
- 由于处理客户查询需要高磁盘 IO,Apache MapReduce 是最慢的查询执行引擎。
- 在保持磁盘 IO 不变的情况下,Apache Tez 明显快于 Apache MapReduce。
- Apache Spark 比没有 IO 阻塞的 Apache Tez 稍快,和Apache Tez 一样以 DAG 方式处理数据,Spark 更加通用,提供内存计算,实时流处理,机器学习等多种计算方式,适合迭代计算。
Apache Livy 简介
Apache Livy 是一项服务,可通过 REST API 与 Spark 集群轻松交互。此方案中的配置方式可将 Hue 页面编写的 SparkSQL 通过 Livy 接口提交到 EMR 集群。
EMR Hue 处理 SparkSQL 默认行为
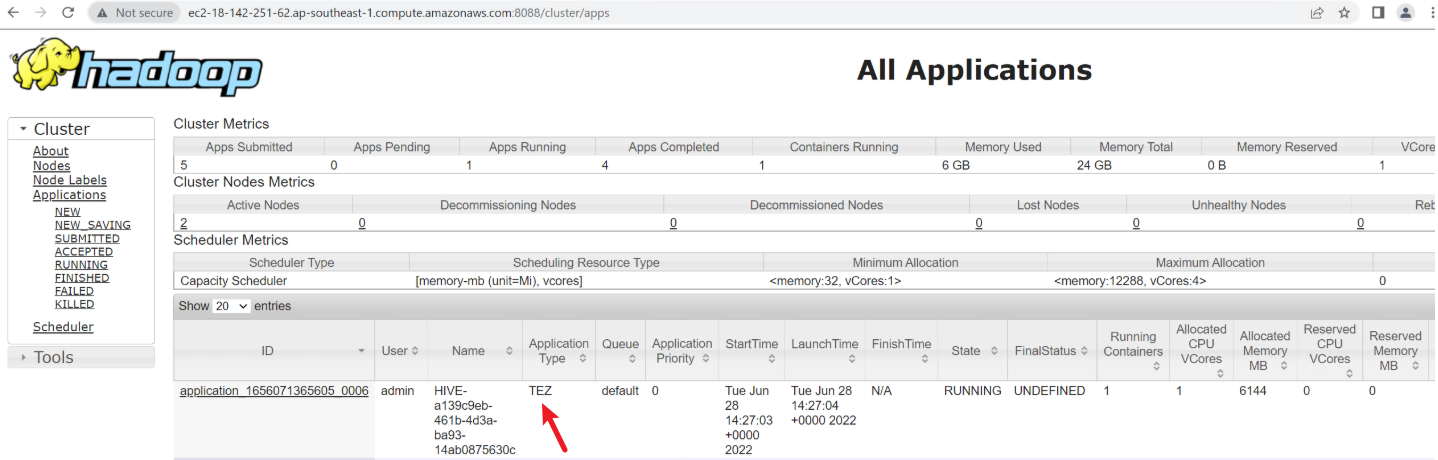
当在 Hue 的面板上 Editor 选择 SparkSQL 并提交 SQL 任务时,我们根据 application_id((Executing on YARN cluster with App id application_1656071365605_0006))去 Resource Manager 控制台上查询到对应的 Application Type 是 Tez:
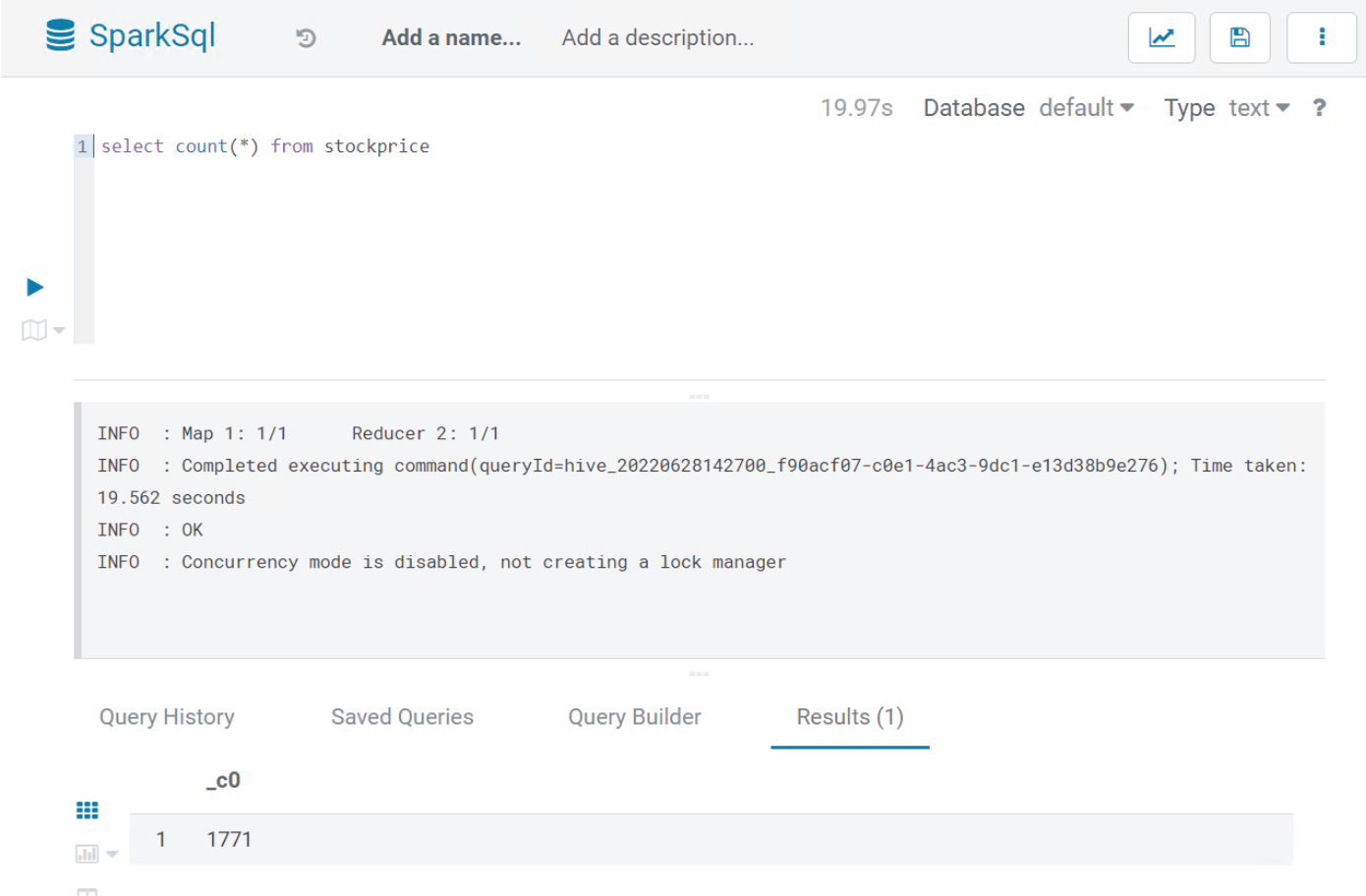
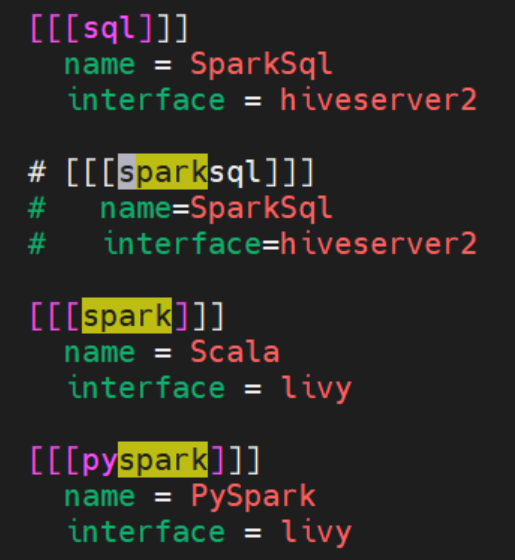
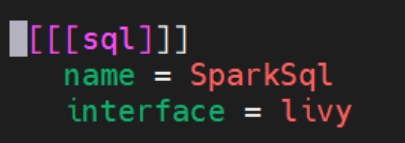
当我们打开 hue 的配置文件(/etc/hue/conf/hue.ini)看到[[[sql]]] 处配置如下图,interface 配置的是 hiveserver2 便知道了此时的 SparkSQL 走的仍是 hiveserver2,因此使用的是 Tez 引擎(EMR上的Hive执行引擎默认是Tez),这代表着并未真的使用 Spark 执行引擎在运行上述的 Query。
在 EMR Hue 中通过 Livy 提交 SparkSQL 任务
(1)修改 Hue 配置文件(/etc/hue/conf/hue.ini)中的执行引擎,并重启 Hue 服务
sudo systemctl restart hue.service
sudo systemctl status hue.service
重新提交 SparkSQL 任务后,看到该 Application 的 ApplicationType 已经为 SPARK。

生产场景中的性能调优:
上述 Application 通过 Spark 管理界面查看 Environment 细节:

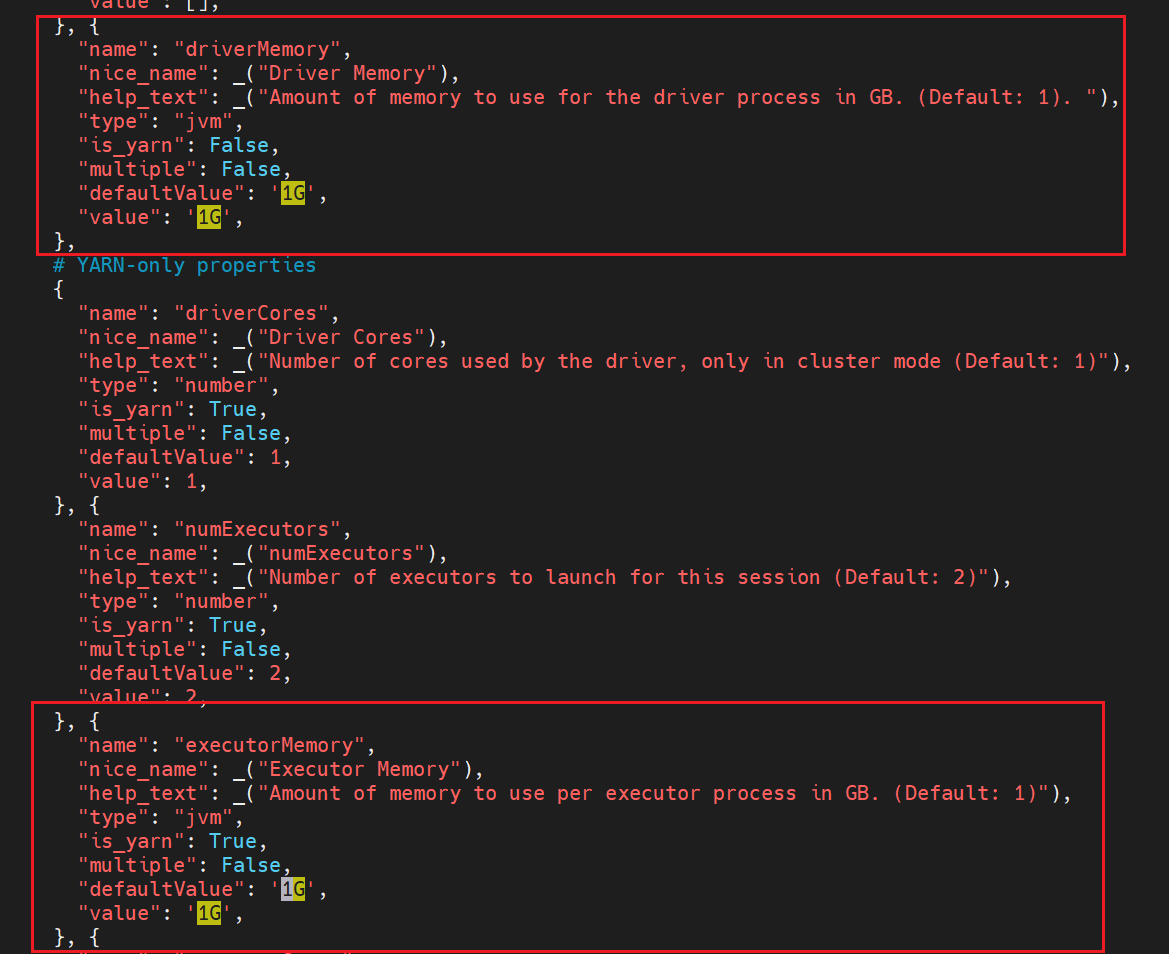
看到 spark.driver.memory 和 spark.executor.memory 均设置为1G

这是因为 Hue 源码中直接将上述两个参数的值设定为1G:
{
"name": "driverMemory",
"nice_name": _("Driver Memory"),
"help_text": _("Amount of memory to use for the driver process in GB. (Default: 1). "),
"type": "jvm",
"is_yarn": False,
"multiple": False,
"defaultValue": '1G',
"value": '1G',
},
…
{
"name": "executorMemory",
"nice_name": _("Executor Memory"),
"help_text": _("Amount of memory to use per executor process in GB. (Default: 1)"),
"type": "jvm",
"is_yarn": True,
"multiple": False,
"defaultValue": '1G',
"value": '1G',
}
如果用默认参数值容易在任务执行中触发 OOM 异常,导致任务运行失败,我们可选择通过以下方法进行调优:
cp /usr/lib/hue/desktop/libs/notebook/src/notebook/connectors/spark_shell.py /usr/lib/hue/desktop/libs/notebook/src/notebook/connectors/spark_shell.py.bak
sudo vi /usr/lib/hue/desktop/libs/notebook/src/notebook/connectors/spark_shell.py
将 ‘driverMemory’ 和 ‘executorMemory’ 的配置删除,重启 Hue 服务
sudo systemctl restart hue.service
sudo systemctl status hue.service
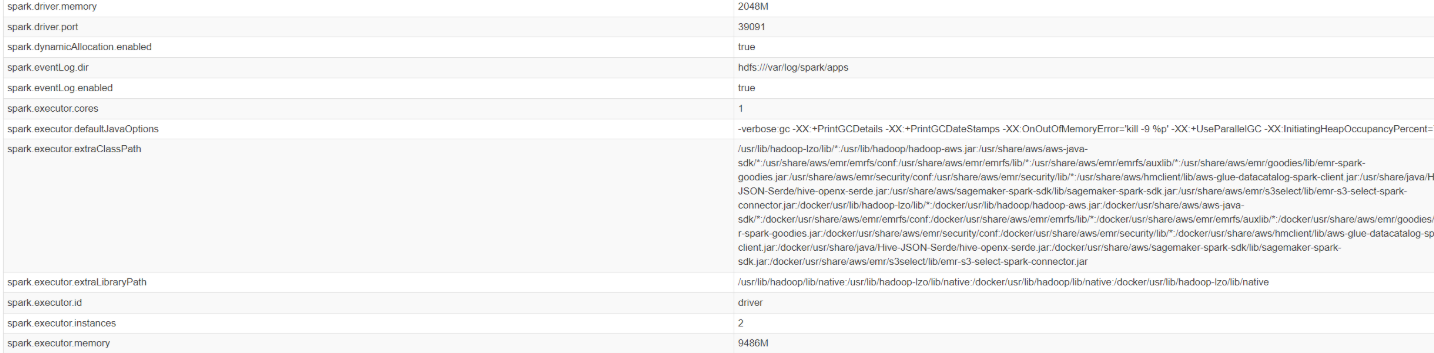
再次运行 SparkSQL,从 Environment 看到两个内存参数已经更新,和 /etc/spark/conf/spark-defaults.conf 内定义一致:

Hue 配置 Phoenix 提交 HBase 任务
Apache Phoenix 简介
Apache Phoenix 是一个开源的,大规模并行的关系数据库引擎,支持使用 Apache HBase 作为其后备存储的 OLTP for Hadoop。Phoenix 提供了一个 JDBC 驱动程序,该驱动程序隐藏了 noSQL 存储的复杂性,使用户能够创建,删除和更改 SQL 表,视图,索引和序列。
配置 Phoenix
(1)准备 Hue Python Virtual Environment
sudo /usr/lib/hue/build/env/bin/pip install phoenixdb
(2)修改 Hue 配置文件:
在 /etc/hue/conf/hue.ini的[notebook] [[interpreters]]部分加入:
[[[phoenix]]]
name=HBase Phoenix
interface=sqlalchemy
options='{"url": "phoenix:// ip-172-31-37-125.ap-southeast-1.compute.internal:8765/"}'
重启 Hue 服务
sudo systemctl restart hue.service
sudo systemctl status hue.service
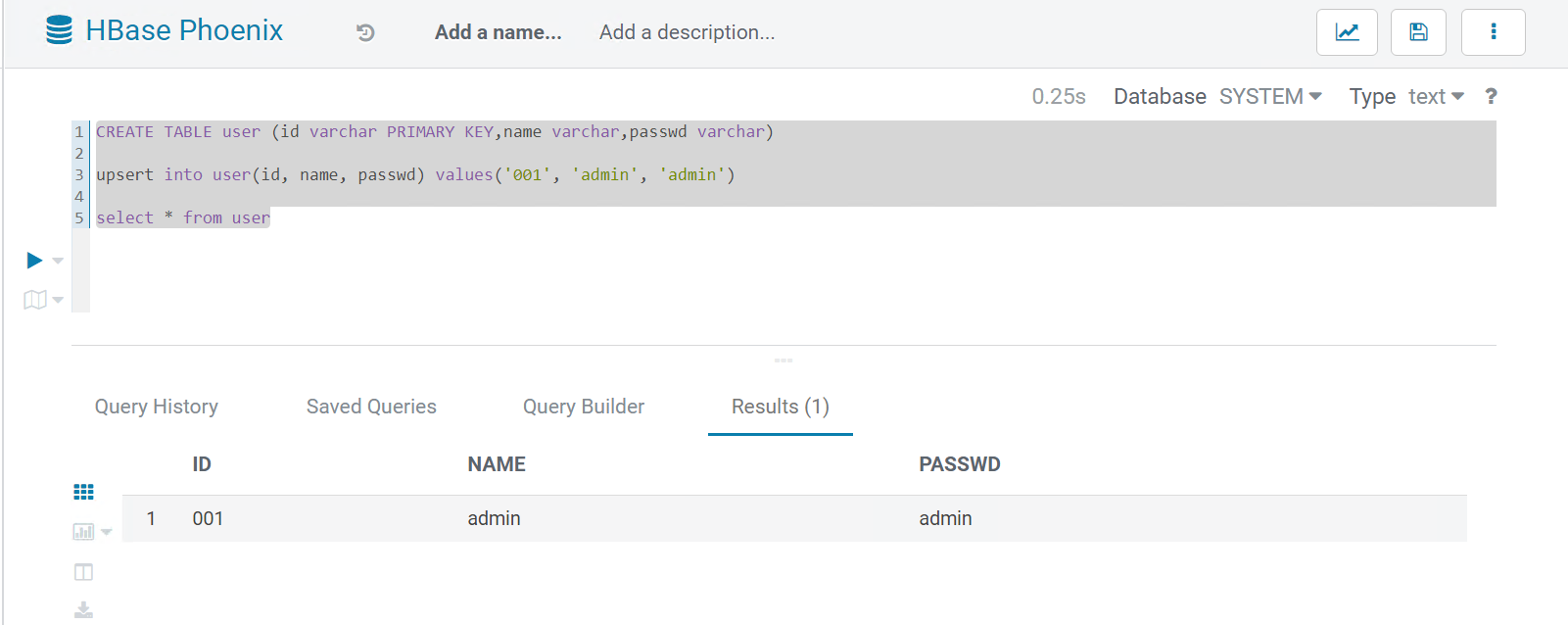
(3) Hue 页面提交 Phoenix 任务:
Hue – Editor 部分因为配置文件的更新,出现了 HBase Phoenix 的选项, 创建和查询 Table :
CREATE TABLE user (id varchar PRIMARY KEY,name varchar,passwd varchar)
upsert into user(id, name, passwd) values('001', 'admin', 'admin')
select * from user
HBase 显示列名乱码修正
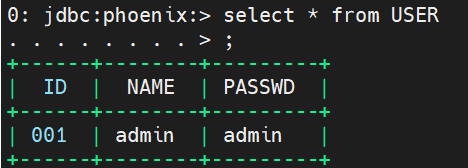
(1)当完成上述操作时,回到 HBase Shell 查看表内容,发现列名为乱码:

使用 Phoenix 命令行(/usr/lib/phoenix/bin/sqlline.py, 不透过Hue)创建表仍能重现该问题,且乱码不会在 Phoenix JDBC 连接中出现:
(2)在 Phoenix 创建表时最后加上 COLUMN_ENCODED_BYTES= 0可规避该问题:
CREATE TABLE user02 (id varchar PRIMARY KEY,name varchar,passwd varchar) COLUMN_ENCODED_BYTES= 0
upsert into user02(id, name, passwd) values('002', 'admin', 'admin')
select * from user02
HBase Shell 查看结果,列名已经显示正常:

Hue 连接 Redshift 提交任务
当数仓平台中涉及 Amazon EMR 和 Amazon Redshift 等多种服务时,通过 Hue 丰富的 Connectors 扩展种类,可以轻松实现统一交互的功能。
(1)准备 Hue Python Virtual Environment
cd /usr/lib/hue/
sudo ./build/env/bin/pip install sqlalchemy-redshift
sudo /usr/lib/hue/build/env/bin/pip2.7 install psycopg2-binary
(2)修改 Hue 配置文件:
在/etc/hue/conf/hue.ini的[notebook] [[interpreters]]部分加入:
[[[redshift]]]
name = Redshift
interface=sqlalchemy
options='{"url": "redshift+psycopg2://username:[email protected]:5439/database"}'
重启 Hue 服务
sudo systemctl restart hue.service
sudo systemctl status hue.service
(3) Hue 页面提交 Redshift 任务:
Hue – Editor 部分因为配置文件的更新,出现了 Reshift 的选项:
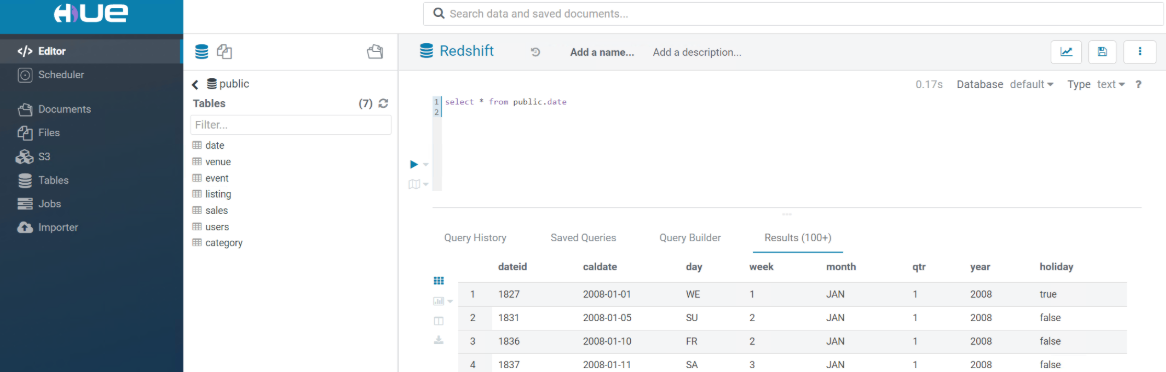
提交 SQL 查询,轻松获取 Amazon Redshift 数仓数据:
总结
本文主要帮助使用 Amazon EMR 的用户,通过 Hue 实现统一数仓平台开发工具,一方面集中管理数仓 SQL 开发任务,另一方面为其它部门提供自主分析的平台,对数仓建设有一定的推动作用。
本篇作者

Sunny Fang Amazon 技术客户经理,主要支持金融,互联网行业客户的架构优化、成本管理、技术咨询等工作,并专注在大数据和容器方向的技术研究和实践。在加入 Amazon 之前,曾就职于 Citrix 和微软等科技公司,拥有8年虚拟化与公有云领域的架构优化和支持经验。

张尹 Amazon 技术客户经理,负责企业级客户的架构和成本优化、技术支持等工作。有多年的大数据架构设计,数仓建模等实战经验。在加入 Amazon 之前,长期负责头部电商大数据平台架构设计、数仓建模、运维等相关工作。