
本文作者
Rohit Vashishtha、Adam Levin、Jyoti Aggarwal、BP Yau和Vijay Karumajji
亚马逊云科技在 re:Invent 2022 大会上推出了 Amazon Aurora zero-ETL 与 Amazon Redshift 集成功能,现在,该功能已通过 Amazon Aurora MySQL-Compatible(兼容第三3版)发布了正式版本(与MySQL 8.0兼容),可使用的地区包括 us-east-1、us-east-2、us-west-2、ap-northeast-1 和 eu-west-1。
作为入门级指南,这篇文章将手把手教您如何利用这一功能实现近实时分析。

挑战
目前,各行各业的客户都在想方设法增加营收,提升客户参与度,为此,他们积极部署近实时的分析应用场景,例如用户个性化策略、欺诈检测、库存监控等等。在分析这些应用场景的事务型数据时,常见两种方式:
分析事务型数据库中的现有数据(例如,阅读副本、联邦查询和分析加速软件)
将数据迁移到经过优化的数据存储中,这种存储能更有效地运行数据仓库等分析查询
zero-ETL集成的目的主要是为了简化后一种方式。

将数据从事务型数据库迁移至一个分析数据仓库的常用办法是 ETL,即通过提取(Extract),转换清洗(Transform)和加载(Load),也就是将来自多个数据源的数据结合成为一个大型、集中式的代码库(数据仓库)。搭建 ETL 管道很昂贵,管理也非常复杂。由于有多个接触点,ETL 管道上的偶发错误会导致长时间的延迟,使依赖这些数据的应用虽然在数据仓库中可用,但可能出现数据过期、丢失的问题,甚至可能导致错失商机的严重后果。
如果客户想要对多个事务型数据库的数据进行统一分析,那么,采用就地分析已有数据的解决方案可能是最好的选择,因为这些解决方案能够在一个数据库中加速完成查询。但这些系统也有局限性——它们无法将多个事务型数据库中的数据汇集在一起。
Zero-ETL
亚马逊云科技正将 zero-ETL 新愿景变为现实,通过 Aurora zero-ETL 与 Amazon Redshift 的集成,Aurora zero-ETL 的交易数据与 Amazon Redshift 的分析功能就可以结合在一起。此举能够最大程度地简化 Aurora 与 Amazon Redshift 之间定制化 ETL 管道的搭建和管理工作。现在,数据工程师可以通过将来自于多个 Aurora 数据库集群的数据复制到已有或新的 Amazon Redshift 实例中,由此获得跨应用与分区的全面洞察。所有 Aurora 数据库中的更新,都将自动地并且持续性地传输到 Amazon Redshift 中,数据工程师由此可以近乎实时地获得最新信息。不仅如此,这整个解决方案都可以设置为 serverless,并根据数据量动态扩展或缩减规模,企业无需管理任何基础设施。
在创建Aurora zero-ETL与Amazon Redshift集成时,客户只需按照现有的价格、根据Aurora与Amazon Redshift的用量来支付费用(包括数据传输)。使用Aurora zero-ETL与Amazon Redshift的集成功能没有额外的费用。
Aurora zero-ETL与 Amazon Redshift 的集成完成之后,可以将源数据库中的数据复制到目标数据仓库中。只需几秒钟,这些数据就在 Amazon Redshift 中呈现可用状态,此后,用户不仅可以使用 Amazon Redshift 提供的分析功能,还拥有了数据共享、工作负载优化自动化、并发扩展、机器学习等其它功能。用户可以在 Aurora 中实时执行数据事务处理,并利用 Amazon Redshift 运行报告、仪表板等分析工作负载。
架构详解如下图:
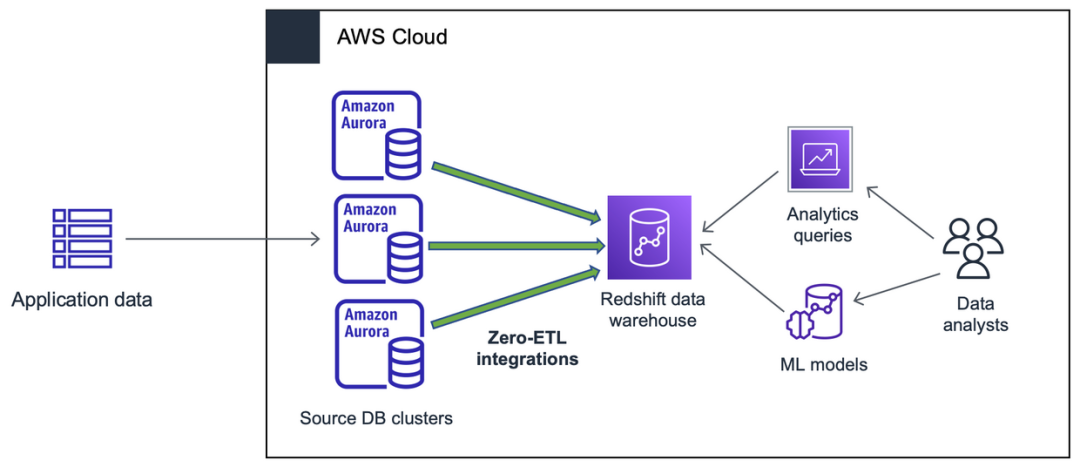
解决方案概览
让我们以票务网站TICKIT为例,用户通过这里在线上买卖体育赛事、演出和音乐会等的门票。该网站的交易数据被加载到Aurora MySQL 3.03.1(或者更高版本)数据库。现在,该网站的业务分析师希望能够生成一些指标来分析长期的门票交易情况,例如卖家的交易成功率、销量最好的活动,以及相关的地点和赛季等。他们希望能够利用zero-ETL集成实时获得实时洞察。
这个集成是指Amazon Aurora MySQL-Compatible 3.03.1版 (源数据库) 与Amazon Redshift(目标数据库)二者的集成。源数据库的交易数据将在目标中实时刷新,实现分析查询。
Amazon Aurora MySQL-Compatible Edition(兼容版)和 Amazon Redshift 都可以采用预置或serverless 方式。下图中,我们采用了预置的Aurora数据库及 Amazon Redshift Serverless 数据仓库。若想获得发布的完产品名单,请参见亚马逊云科技文档功能。
下图是架构详解:
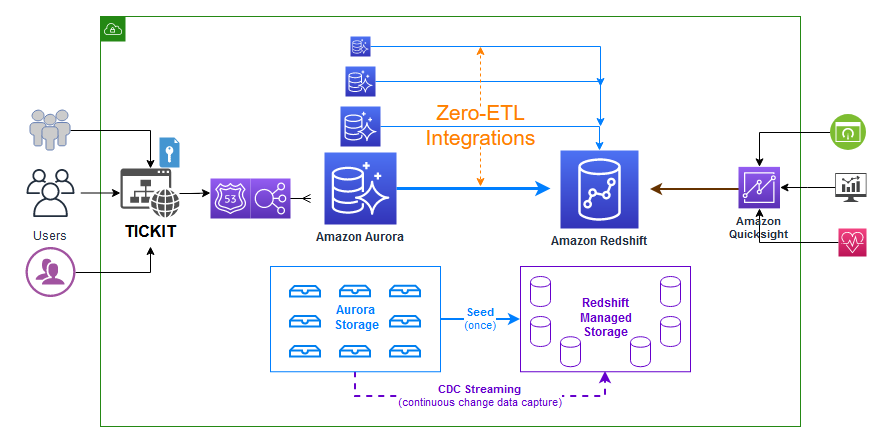
zero-ETL 集成需要完成如下步骤。Aurora 和 Amazon Redshift 完整的入门指南请参见下列文档链接。
利用自定义数据库集群参数组配置 Aurora MySQL 源。
为 Amazon Redshift Serverless 目标配置所需的资源策略以及其命名空间。
更新 Redshift Serverless 工作组,启用区分大小写的标识符。
配置所需的权限。
创建 zero-ETL 集成。
在 Amazon Redshift 中的集成功能中创建一个数据库。
利用自定义数据库集群参数组
配置Aurora MySQL 源
创建 Aurora MySQL 数据库需要完成如下步骤:
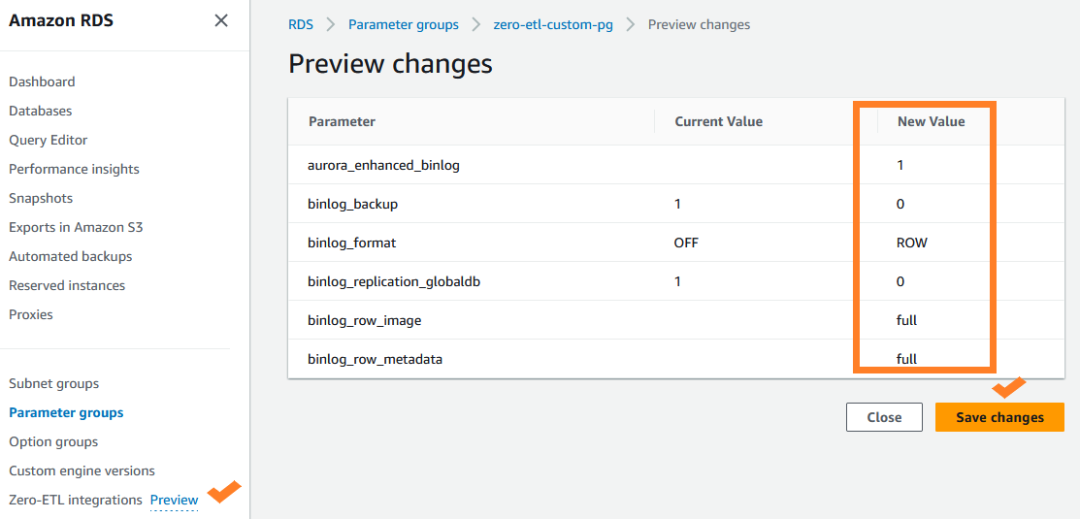
1. 在 Amazon RDS 控制台,创建一个名为 zero-etl-custom-pg 的数据库集群参数组。
Zero-ETL 集成要求控制二进制日志记录(binlog)的 Aurora DB 集群参数必须有特定值。例如,必须启动增强的binlog模式( aurora_enhanced_binlog=1 )。
2. 以下的binlog集群参数应设置为:
binlog_backup=0
binlog_replication_globaldb=0
binlog_format=ROW
aurora_enhanced_binlog=1
binlog_row_metadata=FULL
binlog_row_image=FULL
3. 选择Save changes (保存更改)。
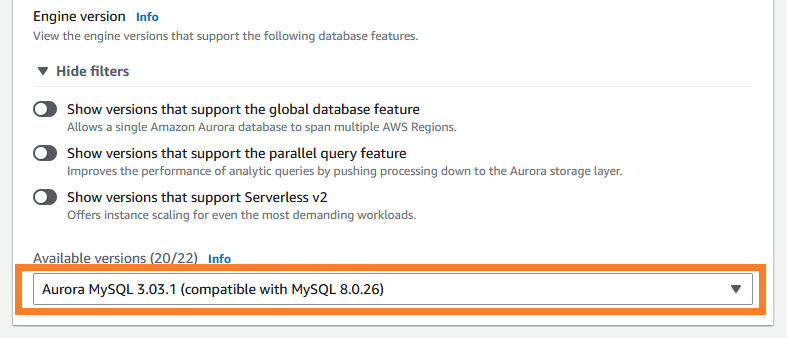
4. 在导航条中选择 Databases(数据库), 之后选择Create database(创建数据库)。

5. 在 Available versions(可用版本)中, 选择Aurora MySQL 3.03.1 (或更高版本)。
6. 在Templates(模板)中, 选择Production(生产).
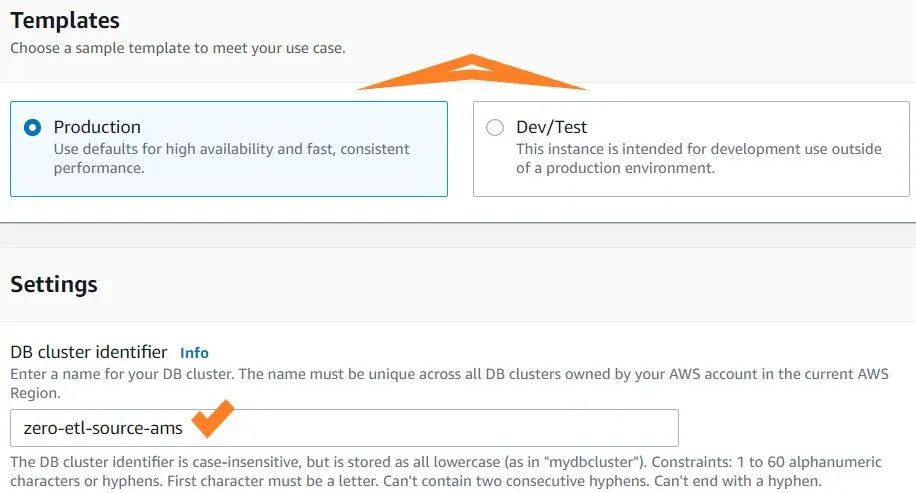
7. 在DB cluster identifier(DB集群识别码)中, 键入zero-etl-source-ams 。
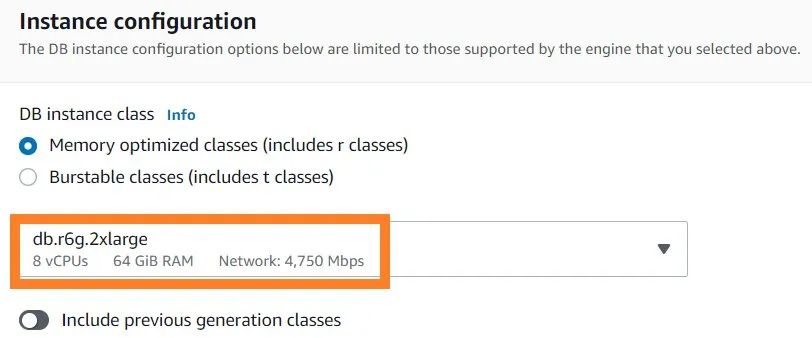
8. 在Instance configuration(实例配置)下, 选择Memory optimized classes (内存优化级),选择一个合适的实例规模(默认 db.r6g.2xlarge )。
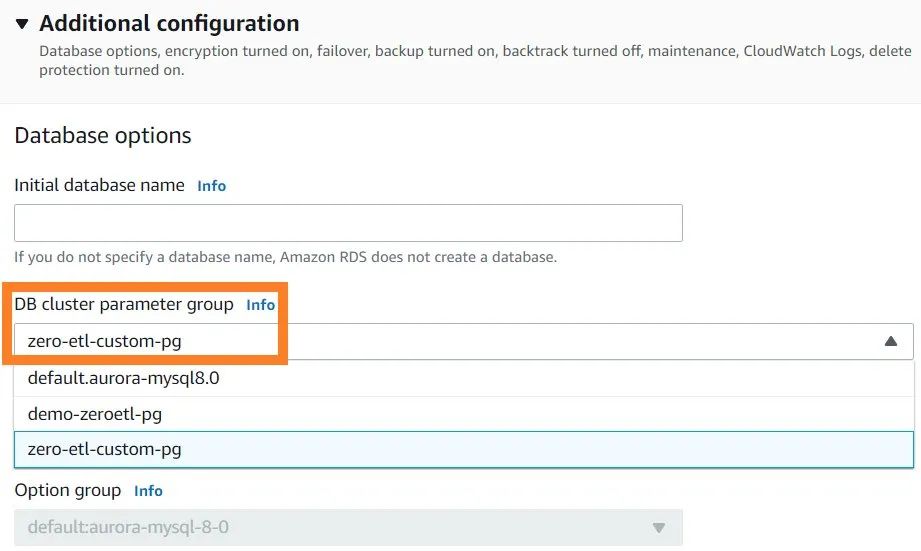
9. 在Additional configuration(其它配置)下的DB cluster parameter group (DB集群参数组)中,选择您之前创建的参数组 (zero-etl-custom-pg)。
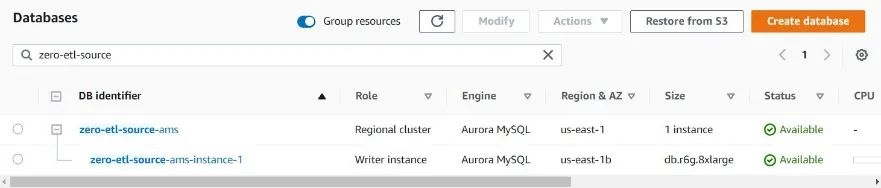
10. 选择 Create database(创建数据库)。
几分钟之后, Aurora MySQL 数据库就会生成,并作为zero-ETL的源数据库。
配置 Redshift Serverless 目标
本用例创建的是一个 Redshift Serverless 数据仓库,需要完成如下步骤:
1. 从Amazon Redshift控制台,在导航条中选择Serverless dashboard(serverless仪表板)
2. 选择Create preview workgroup(创建预览工作组)。

3. 在配置Workgroup name(工作组名称)时,键入 zero-etl-target-rs-wg。
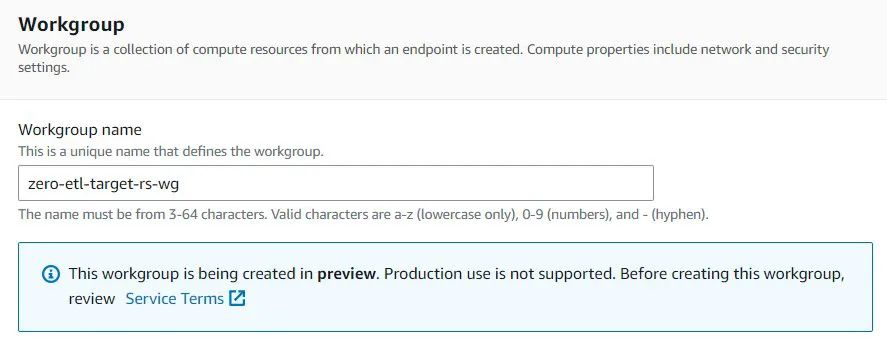
4. 在配置 Namespace(命名空间)时, 选择Create a new namespace(创建新的命名空间),键入zero-etl-target-rs-ns。
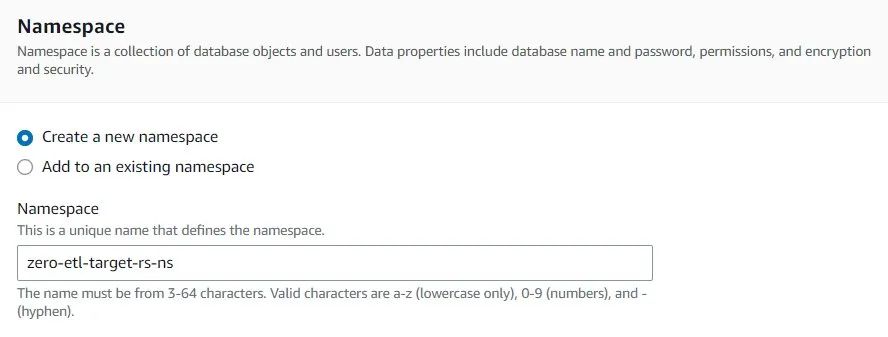
5. 导航至 zero-etl-target-rs-ns ,选择Resource policy(资源策略)标签。
6. 选择Add authorized principals(添加授权主体)。
7. 填入亚马逊云科技用户或角色的Amazon Resource Name(ARN,资源名),或有权在这个命名空间创建集成的亚马逊云科技账户ID(IAM 主体)。
通过根用户将账户ID存为ARN。
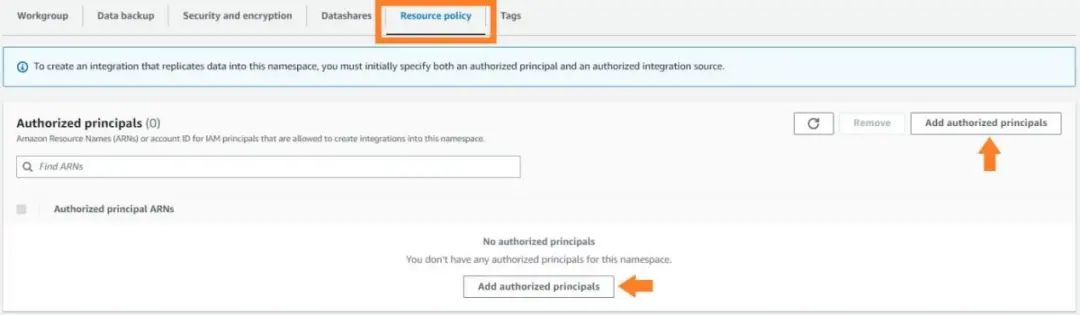
8. 通过在命名空间中添加一个有授权的集成源,指定Aurora MySQL DB 集群的 ARN,该集群是 zero-ETL 的数据源。
9. 选择 Save changes(保存修改)。
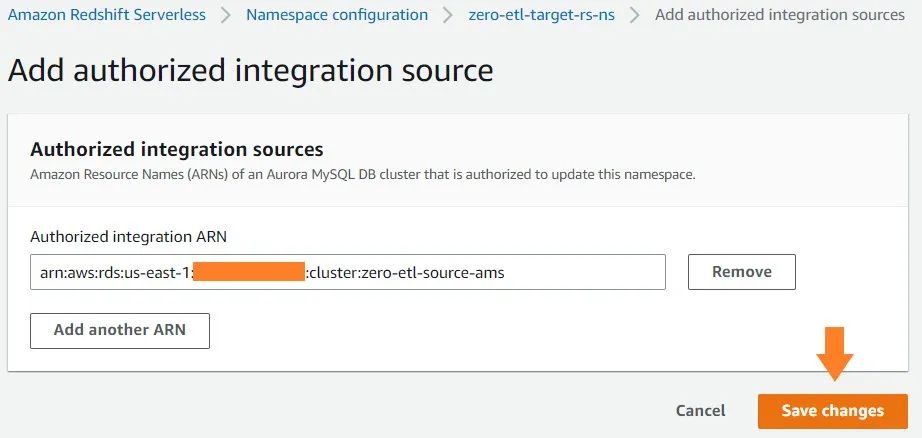
在Configuration(配置)标签页,您可以找到 Aurora MySQL 源的 ARN。具体如下:
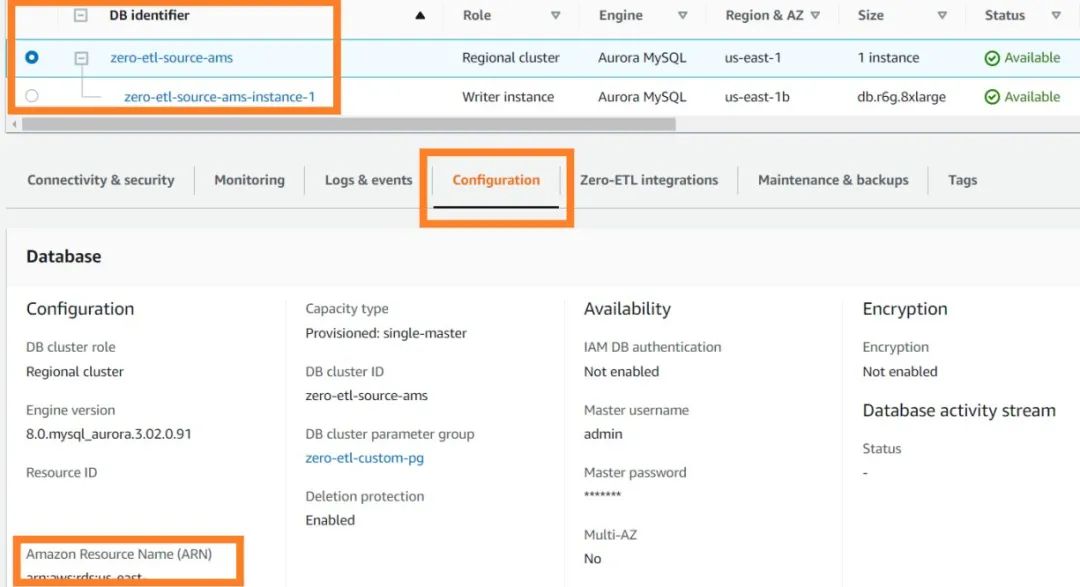
更新Redshift Serverless工作组,
启用区分大小写的标识符
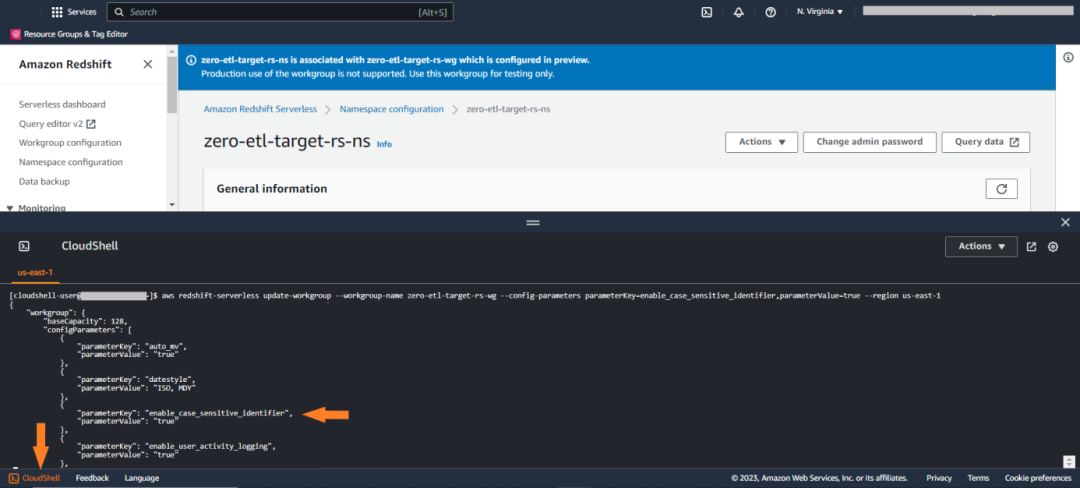
利用 Amazon Command Line Interface (CLI) 运行update-workgroup(更新工作组)操作:
aws redshift-serverless update-workgroup --workgroup-name zero-etl-target-rs-wg --config-parameters parameterKey=enable_case_sensitive_identifier,parameterValue=true --region us-east-1左滑查看更多
您可使用 Amazon CloudShell 或其他界面例如 Amazon Elastic Compute Cloud (Amazon EC2) ,该界面可以使用更新 Redshift Serverless 参数组的亚马逊云科技用户配置。下图展示的是如何在 CloudShell 上运行这一步骤。
下图显示的是如何在Amazon EC2上运行update-workgroup 命令。
配置所需的权限
创建 zero-ETL 集成时,用户或角色须通过适当的Amazon Identity and Access Management (IAM,亚马逊云科技身份及访问管理) 权限,附加基于身份的策略。下面这个策略示例允许相关主体执行如下操作:
为源数据库 Aurora DB 集群创建 zero-ETL 集成。
查看并删除所有的 zero-ETL 集成。
创建目标数据仓库中的入站集成。如果同一个账户拥有 Amazon Redshift 数据仓库,而且这个账户是得到授权的数据仓库主体,则不需要此权限。请注意:针对预置版本和 serverless 版本,Amazon Redshift 会使用不同的 ARN:
- 经配置的集群 – arn:aws:redshift:{region}:{account-id}:namespace:namespace-uuid
- Serverless – arn:aws:redshift-serverless:{region}:{account-id}:namespace/namespace-uuid
配置权限时须完成如下步骤:
1. 从IAM 控制台,在导航条中选择Policies(策略)。
2. 选择 Create policy(创建策略)。
3. 利用以下JSON创建名为 rds-integrations 的新策略:
{
"Version": "2012-10-17",
"Statement": [{
"Effect": "Allow",
"Action": [
"rds:CreateIntegration"
],
"Resource": [
"arn:aws:rds:{region}:{account-id}:cluster:source-cluster",
"arn:aws:rds:{region}:{account-id}:integration:*"
]
},
{
"Effect": "Allow",
"Action": [
"rds:DescribeIntegration"
],
"Resource": ["*"]
},
{
"Effect": "Allow",
"Action": [
"rds:DeleteIntegration"
],
"Resource": [
"arn:aws:rds:{region}:{account-id}:integration:*"
]
},
{
"Effect": "Allow",
"Action": [
"redshift:CreateInboundIntegration"
],
"Resource": [
"arn:aws:redshift:{region}:{account-id}:cluster:namespace-uuid"
]
}]
}左滑查看更多
策略预览:
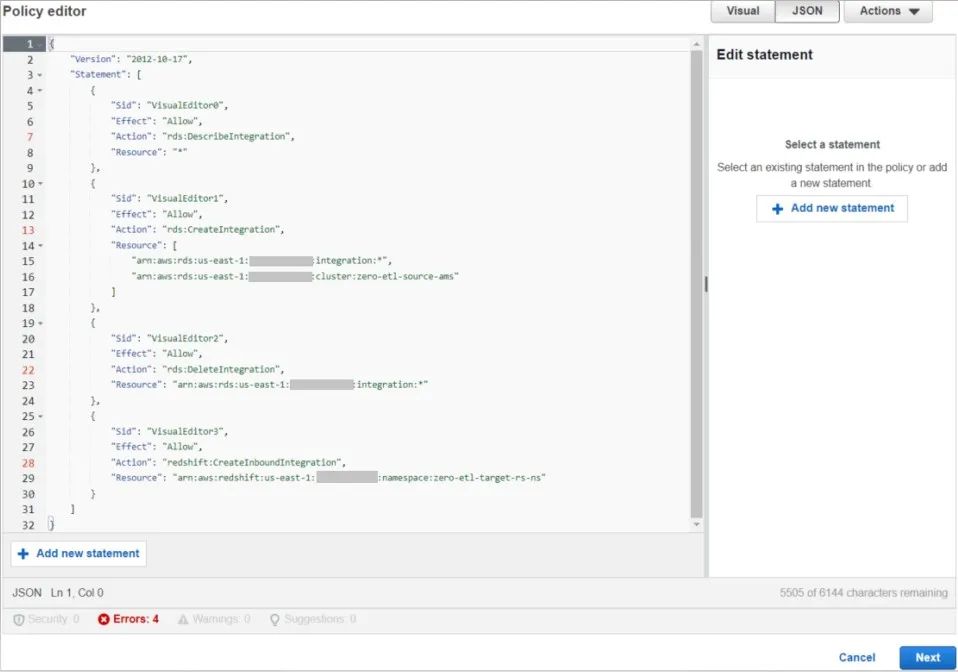
如果您看到针对RDS策略操作IAM策略告警,那是因为该版本仍旧是公共预览中的功能。一旦版本全面可用,这些操作将成为IAM策略的一部分,现在您可以安全地继续操作。
4. IAM用户或角色权限创建完成后,附加策略。
创建zero-ETL集成
创建 zero-ETL 集成需要完成如下步骤:
从 Amazon RDS 控制台, 在导航条中选择 Zero-ETL integrations( Zero-ETL集成)。
选择 Create zero-ETL integration(创建 zero-ETL 集成)。
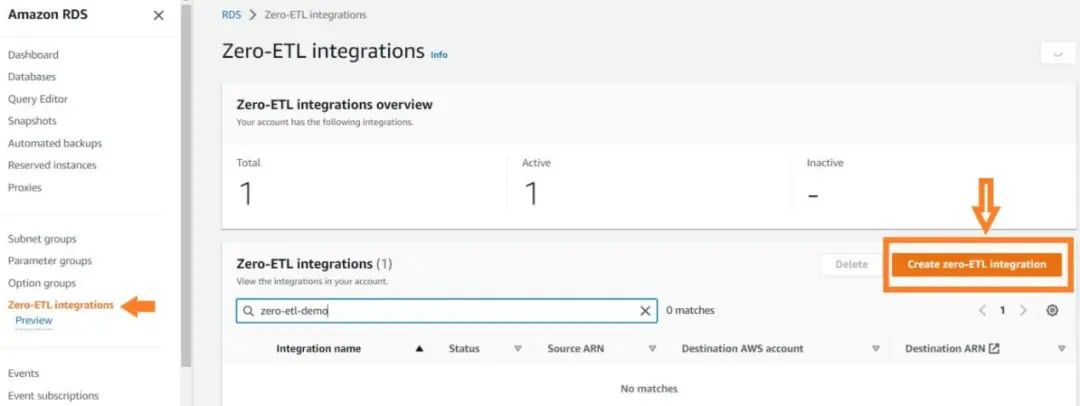
在 Integration name(集成名称)一栏,填入名称,例如 zero-etl-demo。
在 Aurora MySQL 源集群,浏览并选择源集群zero-etl-source-ams。
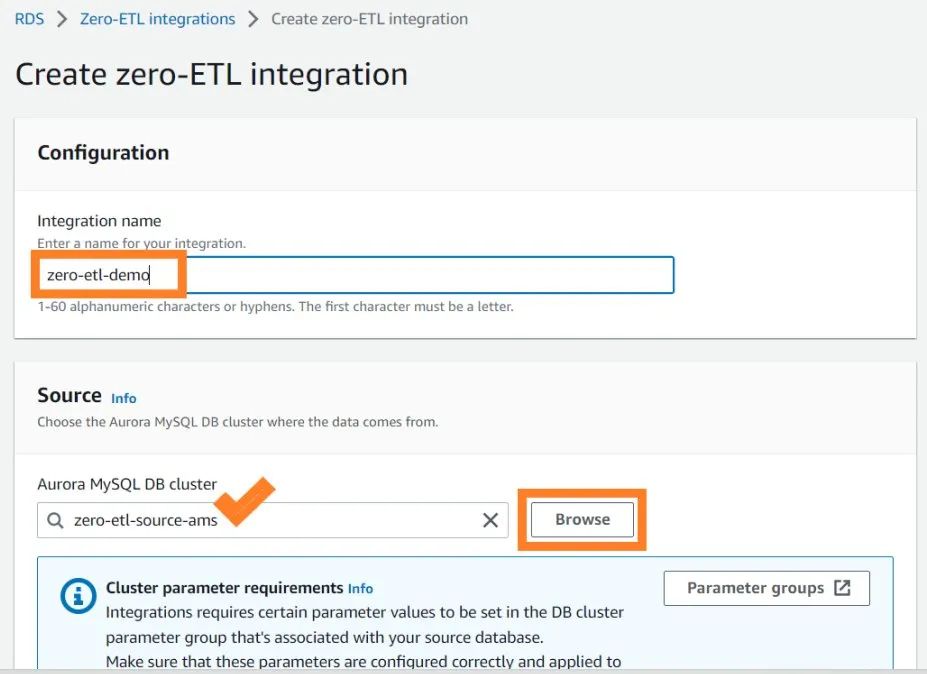
在Destination(目标)下的Amazon Redshift data warehouse(Amazon Redshift数据仓库),选择Redshift Serverless目标命名空间(zero-etl-target-rs-ns)。
选择Create zero-ETL integration(创建zero-ETL集成)。
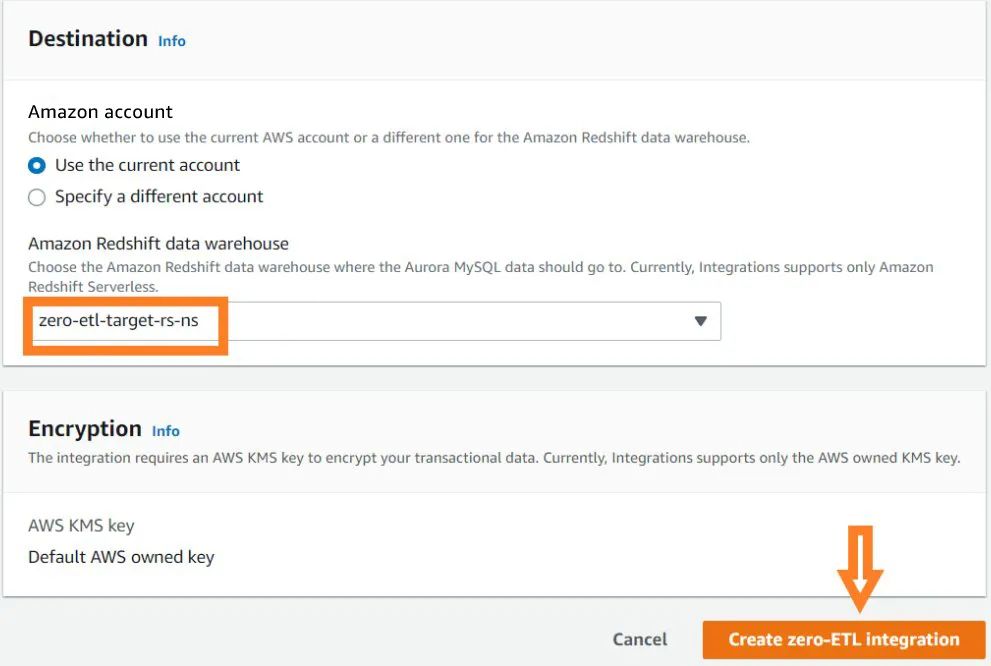
为了指定一个位于另一个亚马逊云科技账户中的目标Amazon Redshift数据仓库,用户必须要先创建一个角色,以便从当前账户访问目标账户中的资源。欲了解更多信息,请参阅Providing access to an IAM user in another Amazon account that you own(在您的另一个亚马逊云科技账户中为IAM用户提供访问权限)。
链接:
https://docs.aws.amazon.com/IAM/latest/UserGuide/id_roles_common-scenarios_aws-accounts.html
利用如下权限,在目标账户中创建角色:
{
"Version":"2012-10-17",
"Statement":[
{
"Effect":"Allow",
"Action":[
"redshift:DescribeClusters",
"redshift-serverless:ListNamespaces"
],
"Resource":[
"*"
]
}
]
}左滑查看更多
这个角色必须具有如下的信任策略,即设置了目标账户 ID。方法是:创建角色,以一个信任主体作为另一个账户中的亚马逊云科技账户 ID。
{
"Version":"2012-10-17",
"Statement":[
{
"Effect":"Allow",
"Principal":{
"AWS": "arn:aws:iam::{external-account-id}:root"
},
"Action":"sts:AssumeRole"
}
]
}左滑查看更多
下图展示的是如何在 IAM 控制台上完成这个创建。
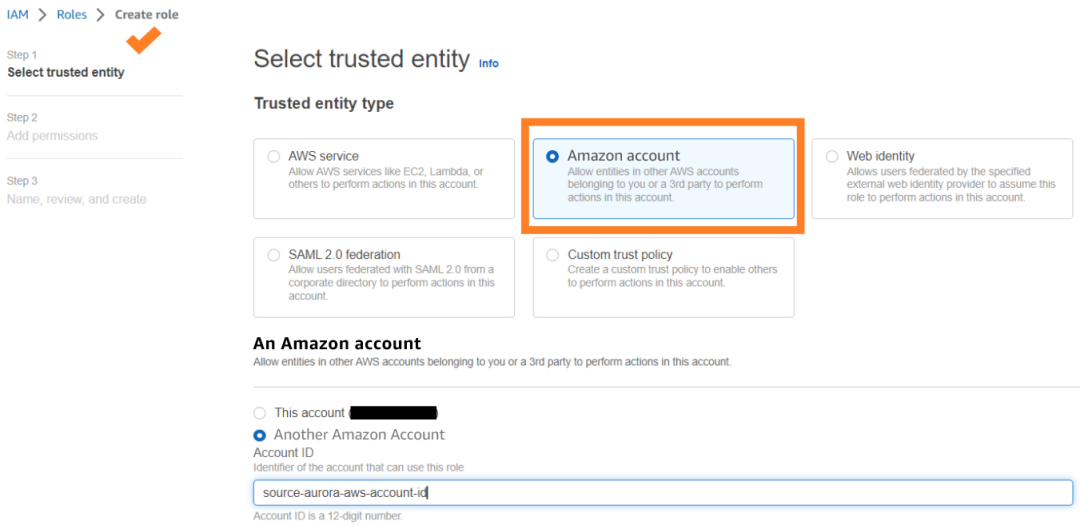
在创建 zero-ETL 集成时,选择目标账户 ID 以及您创建的角色的名字,然后继续,Specify a different account(设置一个不同的账户)选项。
您可以通过选择集成来查看详细信息,并监控进展。在将状态从 Creating (创建)更改成为 Active (已激活)时,需要几分钟的时间。具体所需时间要根据数据库源中可用数据集的规模大小而定。
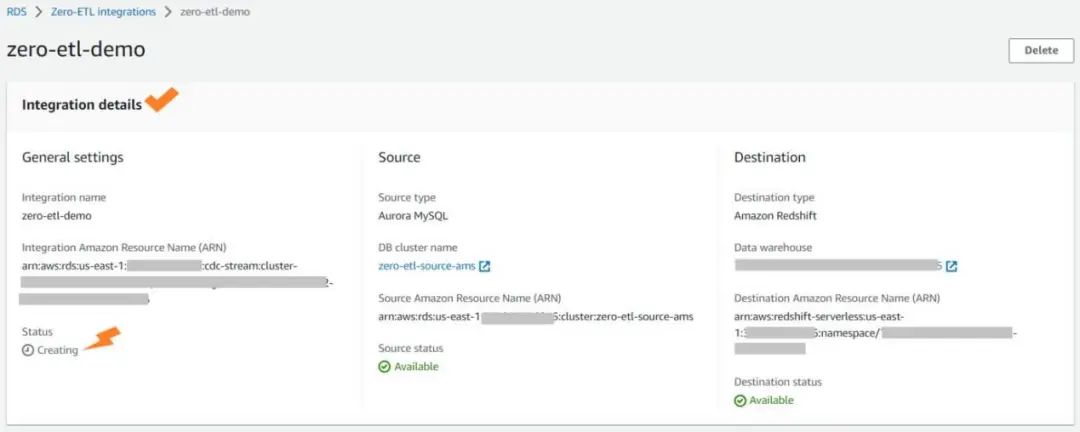
在Amazon Redshift中的集成功能中
创建一个数据库
创建数据库需要完成如下步骤:
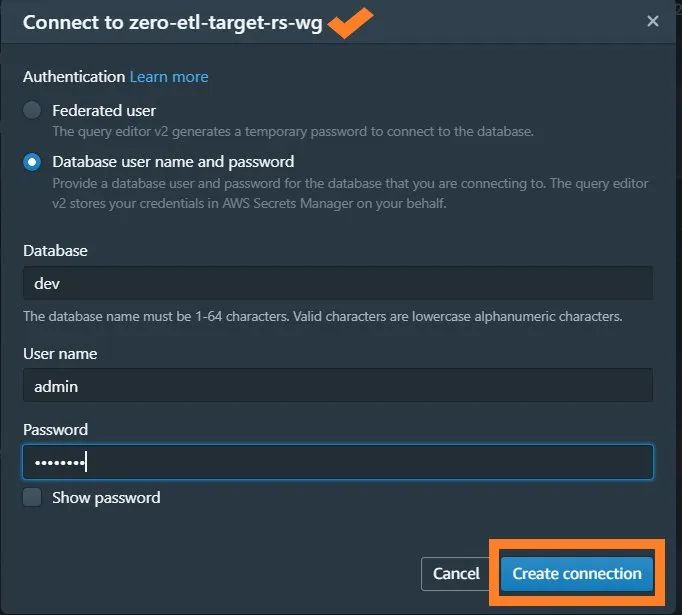
在Redshift Serverless仪表板中,导航至 zero-etl-target-rs-ns namespace。
选择Query data(查询数据),打开Query Editor v2(版本2)。

选择Create connection(创建连接),连接后可预览Redshift Serverless数据仓库。
从 svv_integration 系统表格中获取 integration_id :
select integration_id from svv_integration; ---- copy this result, use in the next sql左滑查看更多
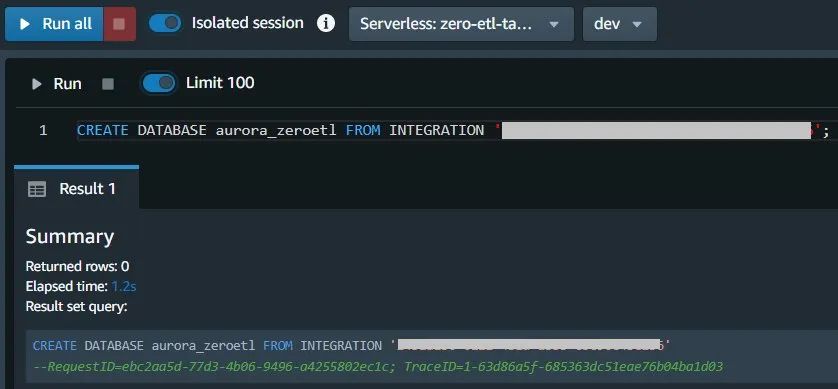
5. 使用上一步中的 integration_id ,通过集成创建新的数据库:
CREATE DATABASE aurora_zeroetl FROM INTEGRATION '';左滑查看更多
集成到此全部完成,数据库源的所有截图将原样出现在目标中,更改结果也将实时同步。
分析近乎实时的交易数据
现在我们要对TICKIT的事务型数据进行分析。
输入源TICKIT数据
输入源数据需要完成如下步骤:
1. 与 Aurora MySQL 集群连接,为 TICKIT 数据模型创建一个数据库或 schema,确认 schema 中的表格有主密钥,然后启动加载流程:
mysql -h <amazon_aurora_mysql_writer_endpoint> -u admin -p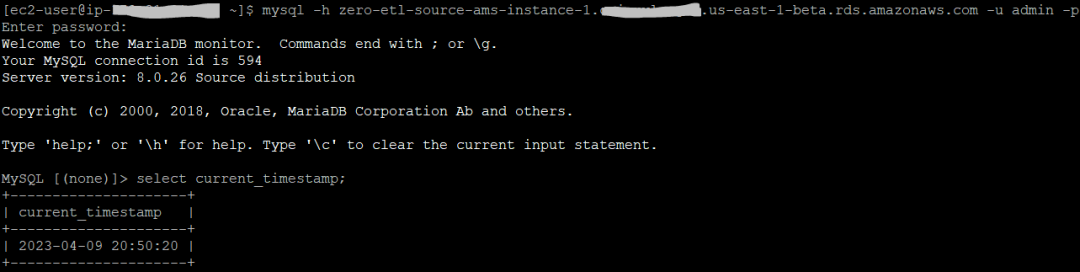
可利用以下HTML 文件中的脚本在Amazon Aurora MySQL-Compatible版本中创建一个样本数据库demodb (使用的是tickit.db模型)。
2. 运行脚本,在 demodb 数据库或 schema中创建 tickit.db模型表格:
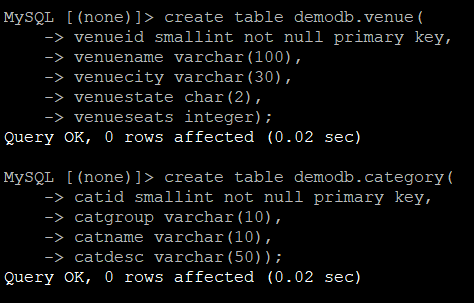
3. 从 Amazon Simple Storage Service (Amazon S3)中加载数据,记录在目标中更改数据捕获(CDC)校验的完成时间,观察集成的活跃程度。
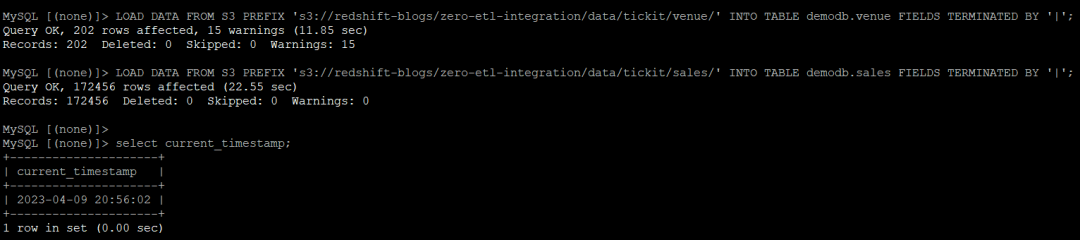
通过 Amazon S3 加载数据会有一些常见错误,如下:
对于最新版本的 Aurora MySQL 集群,我们需要在数据库集群参数组中设置 aws_default_s3_role 参数,这是针对有 Amazon S3 必要访问权的 ARN 的。
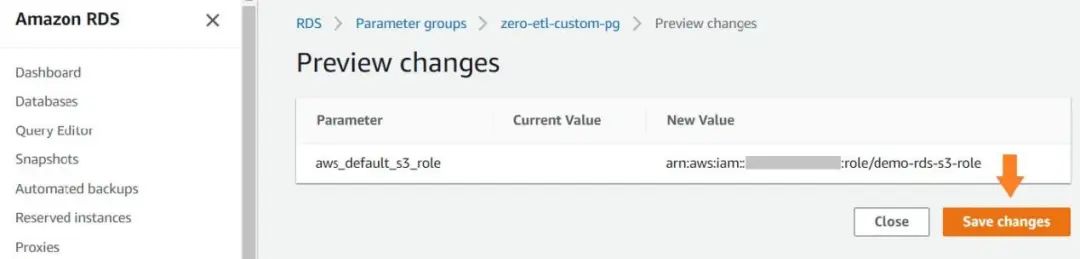
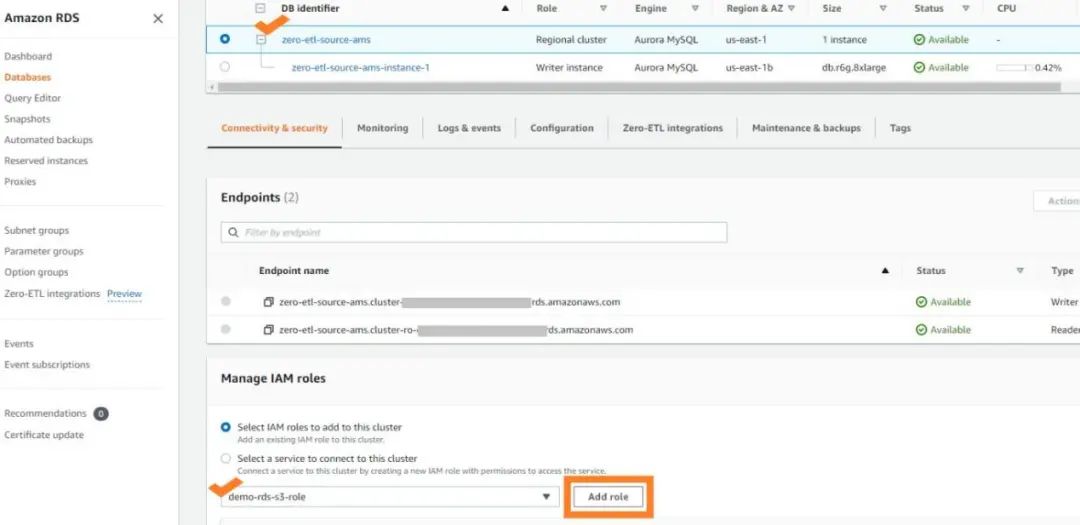
如果您遇到缺少凭证的错误 (例如,Error 63985 (HY000): S3 API returned error: Missing Credentials: Cannot instantiate S3 Client),那应该就是因为您尚未将 IAM 角色与集群关联。在这种情况下,请将所需的 IAM 角色添加到源 Aurora MySQL 集群中。
分析目标中的TICKIT 数据
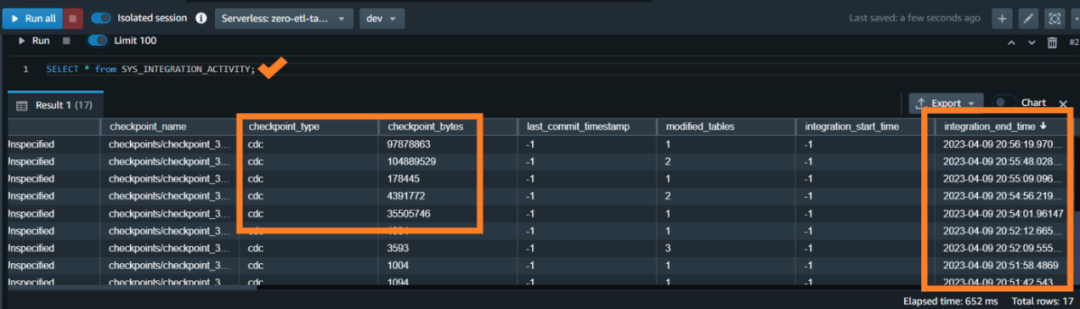
在 Redshift Serverless 仪表板中,使用您配置集成时创建的数据库打开 Query Editor(版本2)作为设置的一部分。使用以下代码来校验种子或 CDC 活动:
SELECT * FROM SYS_INTEGRATION_ACTIVITY;左滑查看更多
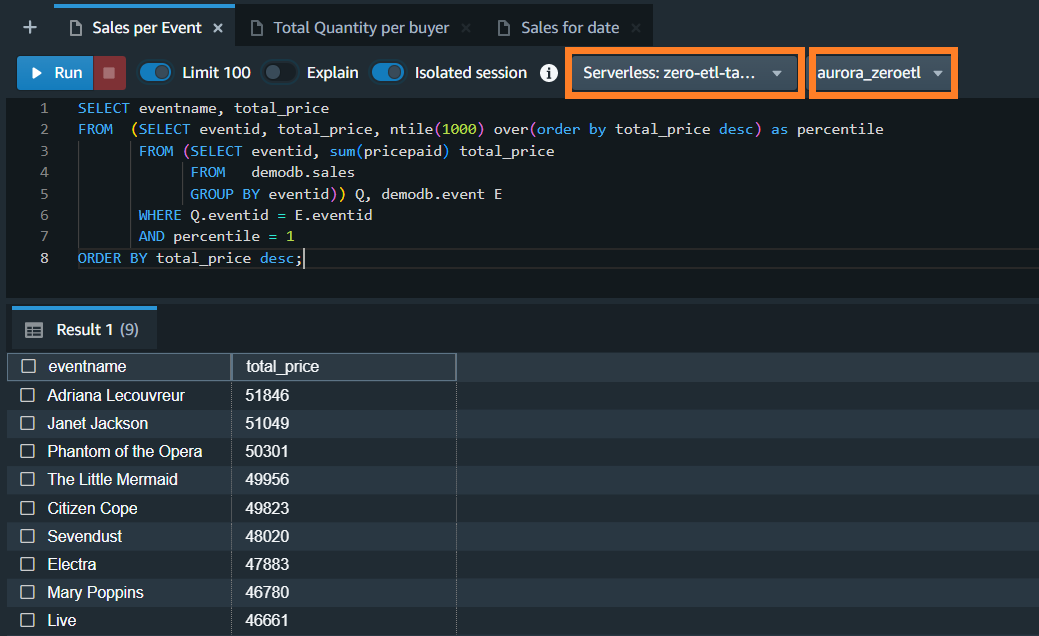
点击下拉菜单,选择集群或工作组,以及通过集成创建的数据库,运行 tickit.db 样本分析查询。
监控
若需要 zero-ETL 与 Amazon Redshift 集成的相关信息,您可以在 Amazon Redshift 中查询以下系统的视图和表格:
SVV_INTEGRATION(集成) – 提供集成的配置详细信息。
SYS_INTEGRATION_ACTIVITY(集成_活动) – 提供已完成的集成运行的相关信息。
SVV_INTEGRATION_TABLE_STATE (集成_表格_状态)– 描述集成中每一个表格的状态。
若需查看在 Amazon CloudWatch 中发布的与集成相关的指标,导航至 Amazon Redshift 控制台,从左边的导航条中选择 Zero-ETL 集成,然后点击集成链接,即可显示活动指标。
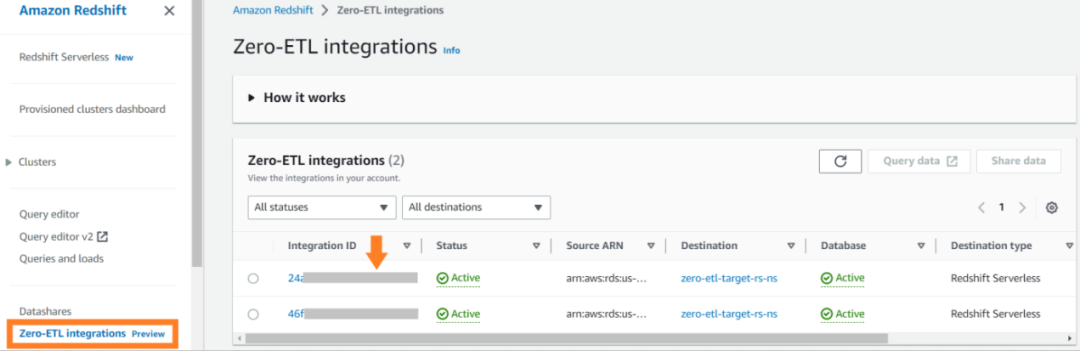
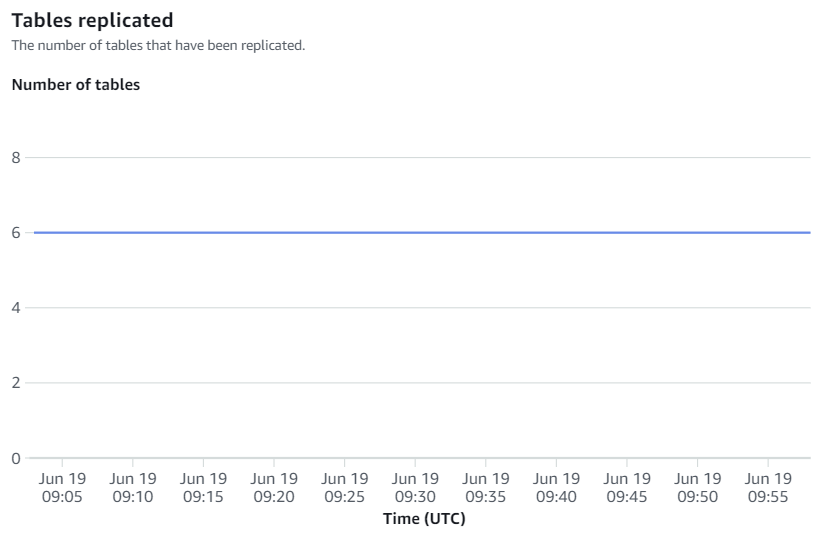
在 Redshift 控制台中可用的指标是集成指标和表格数据,表格数据包含有从 Aurora MySQL 复制到 Amazon Redshift 的所有表格的详细信息。

集成指标包含有表格复制成功和失败的次数,以及延迟的详细信息:
清理
在删除 zero-ETL 集成功能时,Aurora 会从 Aurora 集群中将其删除。交易数据不会从 Aurora 或 Amazon Redshift 中被删除,但 Aurora 也不会再向 Amazon Redshift 传输新的数据。
删除 zero-ETL 集成需要完成如下步骤:
在 Amazon RDS 控制台中从导航条选择 Zero-ETL integrations(Zero-ETL 集成)。
选择需要删除的 zero-ETL 集成,然后选择Delete(删除)。
确认删除,选择 Delete(删除)。

结论
本文着重介绍的是如何从 Amazon Aurora MySQL-Compatible Edition(兼容版)到 Amazon Redshift设置 Aurora zero-ETL 集成,此举可最大程度地减少复杂数据管道的维护工作,同时还能对交易数据和事务型数据进行近乎实时的分析。欲了解更多 zero-ETL 与 Amazon Redshift 集成的相关信息,请浏览 Aurora 和Amazon Redshift 的相关文档。


听说,点完下面4个按钮
就不会碰到bug了!
