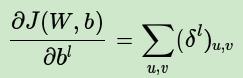参考:https://blog.csdn.net/kyang624823/article/details/78633897
卷积层 池化层反向传播:
1,CNN的前向传播
a)对于卷积层,卷积核与输入矩阵对应位置求积再求和,作为输出矩阵对应位置的值。如果输入矩阵inputX为M*N大小,卷积核为a*b大小,那么输出Y为(M-a+1)*(N-b+1)大小。 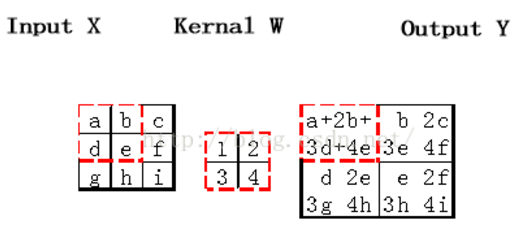
b)对于池化层,按照池化标准把输入张量缩小。
c)对于全连接层,按照普通网络的前向传播计算。
2,CNN反向传播的不同之处:
首先要注意的是,一般神经网络中每一层输入输出a,z都只是一个向量,而CNN中的a,z是一个三维张量,即由若干个输入的子矩阵组成。其次:
- 池化层没有激活函数。这个问题倒比较好解决,我们可以令池化层的激活函数为σ(z)=z,即激活后就是自己本身。这样池化层激活函数的导数为1。
- 池化层在前向传播的时候,对输入进行了压缩,那么我们向前反向推导上一层的误差时,需要做upsample处理。
- 卷积层是通过张量卷积,或者说若干个矩阵卷积求和而得到当前层的输出,这和一般的网络直接进行矩阵乘法得到当前层的输出不同。这样在卷积层反向传播的时候,上一层误差的递推计算方法肯定有所不同。
- 对于卷积层,由于W使用的运算是卷积,那么由该层误差推导出该层的所有卷积核的W,b的方式也不同。
由于卷积层可以有多个卷积核,各个卷积核的处理方法是完全相同且独立的,为了简化算法公式的复杂度,我们下面提到卷积核都是卷积层中若干卷积核中的一个。接下来看具体的CNN反向传播步骤。
3,已知池化层的误差,反向推导上一隐藏层的误差
在前向传播时,池化层我们会用MAX或者Average对输入进行池化,池化的区域大小已知。现在我们反过来,要从缩小后区域的误差,还原前一层较大区域的误差。这个过程叫做upsample。假设我们的池化区域大小是2x2。第l层误差的第k个子矩阵为:
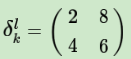
如果池化区域表示为a*a大小,那么我们把上述矩阵上下左右各扩展a-1行和列进行还原: 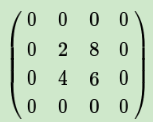
Pooling层反向传播需要保证传递的loss(或者梯度)总和不变。根据这条原则,mean pooling和max pooling的反向传播也是不同的。
MAX POOLING:
如果是MAX,假设我们之前在前向传播时记录的最大值位置分别是左上,右下,右上,左下,则转换后的矩阵为: 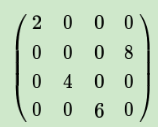
举个例子:
max pooling也要满足梯度之和不变的原则,max pooling的前向传播是把patch中最大的值传递给后一层,而其他像素的值直接被舍弃掉。那么反向传播也就是把梯度直接传给前一层某一个像素,而其他像素不接受梯度,也就是为0。所以max pooling操作和mean pooling操作不同点在于需要记录下池化操作时到底哪个像素的值是最大,也就是max id,这个变量就是记录最大值所在位置的,因为在反向传播中要用到,那么假设前向传播和反向传播的过程就如下图所示 :

Average POOLING
如果是Average,则进行平均,转换后的矩阵为: 
举个例子:
mean pooling的前向传播就是把一个patch中的值求取平均来做pooling,那么反向传播的过程也就是把某个元素的梯度等分为n份分配给前一层,这样就保证池化前后的梯度(残差)之和保持不变
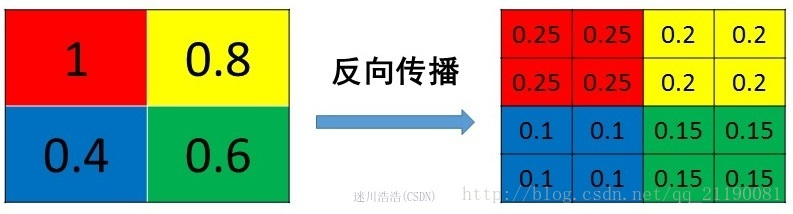
上边这个矩阵就是误差矩阵经过upsample之后的矩阵,那么,由后一层误差推导出前一层误差的公式为: 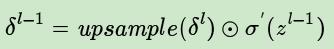
上式和普通网络的反向推导误差很类似: 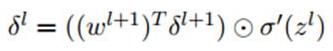
可以看到,只有第一项不同。
4,已知卷积层的误差,反向推导上一隐藏层的误差、
推导链接:https://blog.csdn.net/legend_hua/article/details/81590979
公式如下: 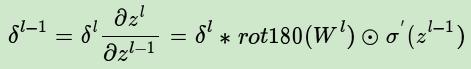
我们再看一次普通网络的反向推导误差的公式:
可以看到区别在于,下一层的权重w的转置操作,变成了旋转180度的操作,也就是上下翻转一次,左右再翻转一次,这其实就是“卷积”一词的意义(我们可简单理解为数学上的trick),可参考下图,Q是下一层的误差,周围补0方便计算,W是180度翻转后的卷积核,P是W和Q做卷积的结果:

5,已知卷积层的误差,推导该层的W,b的梯度
经过以上各步骤,我们已经算出每一层的误差了,那么:
a)对于全连接层,可以按照普通网络的反向传播算法求该层W,b的梯度。
b)对于池化层,它并没有W,b,也不用求W,b的梯度。
c)只有卷积层的W,b需要求出,先看w: 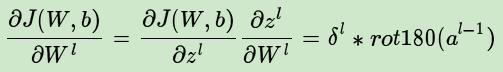
再对比一下普通网络的求w梯度的公式,发现区别在于,对前一层的输出做翻转180度的操作: 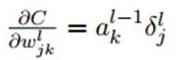
而对于b,则稍微有些特殊,因为在CNN中,误差δ是三维张量,而b只是一个向量,不能像普通网络中那样直接和误差δ相等。通常的做法是将误差δ的各个子矩阵的项分别求和,得到一个误差向量,即为b的梯度: