今天博主在研究卷积神经网络的反向传播算法时,产生了这么一个疑问:pooling层没有卷积核,那反向传播的时候,做了些什么呢?更新了什么参数呢?
有一位博主提到:池化层一般没有参数,所以反向传播的时候,只需对输入参数求导,不需要进行权值更新。但是具体在计算的时候是要根据Max还是Average来进行区分,进行参数更新的。
我们来看看池化层的前向传播和反向传播过程
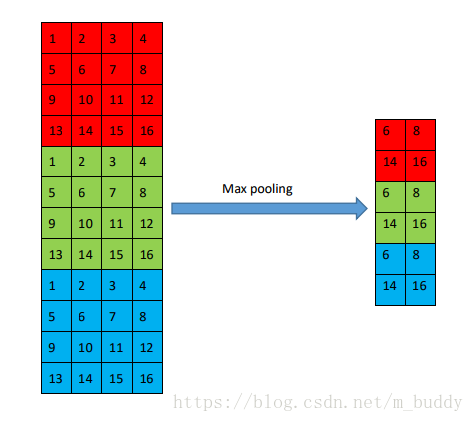
1 Max-Pooling
该种类型的池化层是取运算窗口中的最大值作为最后运算的结果,可以表示为:
上图中就是以3∗23∗2大小的窗口进行运算得到的结果
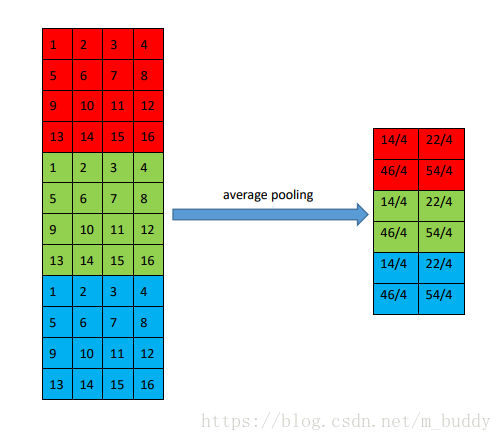
2 Average-Pooling
该种类型的池化层是取运算窗口中的所有值的均值作为最后运算的结果,可以表示为:
Pooling池化操作的反向梯度传播
CNN网络中另外一个不可导的环节就是Pooling池化操作,因为Pooling操作使得feature map的尺寸变化,假如做2×22×2的池化,假设那么第l+1l+1层的feature map有16个梯度,那么第ll层就会有64个梯度,这使得梯度无法对位的进行传播下去。其实解决这个问题的思想也很简单,就是把1个像素的梯度传递给4个像素,但是需要保证传递的loss(或者梯度)总和不变。根据这条原则,mean pooling和max pooling的反向传播也是不同的。
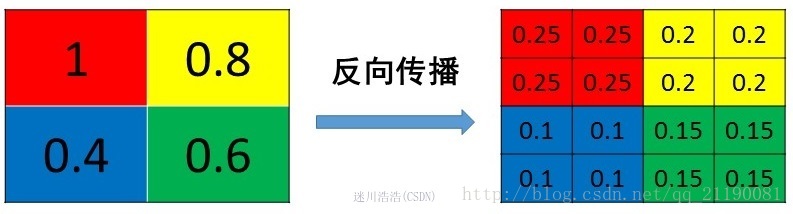
1、mean pooling
mean pooling的前向传播就是把一个patch中的值求取平均来做pooling,那么反向传播的过程也就是把某个元素的梯度等分为n份分配给前一层,这样就保证池化前后的梯度(残差)之和保持不变,还是比较理解的,图示如下
mean pooling比较容易让人理解错的地方就是会简单的认为直接把梯度复制N遍之后直接反向传播回去,但是这样会造成loss之和变为原来的N倍,网络是会产生梯度爆炸的。
2、max pooling
max pooling也要满足梯度之和不变的原则,max pooling的前向传播是把patch中最大的值传递给后一层,而其他像素的值直接被舍弃掉。那么反向传播也就是把梯度直接传给前一层某一个像素,而其他像素不接受梯度,也就是为0。所以max pooling操作和mean pooling操作不同点在于需要记录下池化操作时到底哪个像素的值是最大,也就是max id
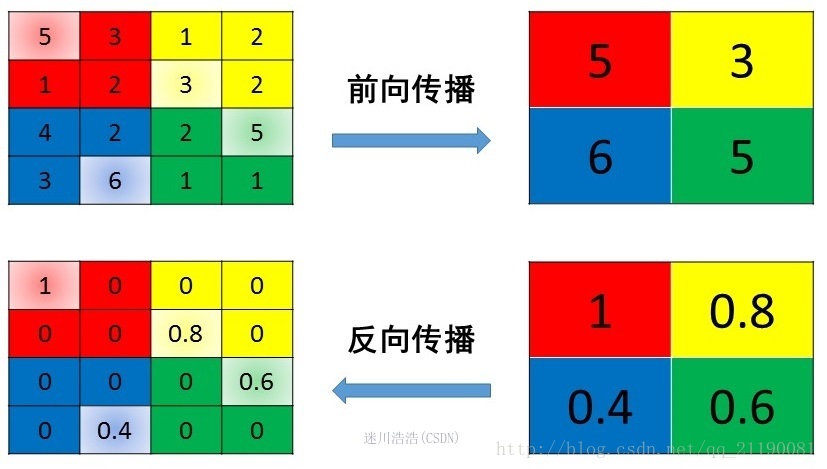
源码中有一个max_idx_的变量,这个变量就是记录最大值所在位置的,因为在反向传播中要用到,那么假设前向传播和反向传播的过程就如图所示
总结
无论max pooling还是mean pooling,都没有需要学习的参数。因此,在卷积神经网络的训练中,Pooling层需要做的仅仅是将误差项传递到上一层,而没有梯度的计算。
(1)max pooling层:对于max pooling,下一层的误差项的值会原封不动的传递到上一层对应区块中的最大值所对应的神经元,而其他神经元的误差项的值都是0;
(2)mean pooling层:对于mean pooling,下一层的误差项的值会平均分配到上一层对应区块中的所有神经元。
参考文献
原文:https://blog.csdn.net/hai008007/article/details/79769174
原文:https://blog.csdn.net/qq_21190081/article/details/72871704
原文:https://blog.csdn.net/m_buddy/article/details/80426531