1、背景
语言模型就是计算句子中的词按照组成句子的顺序排列的概率,由此来判断是不是正常句子。
传统的语言模型,N-gram模型,基于马尔科夫假设,下一个词的出现仅依赖前面的一个或n个词
对一句话S=x1,x2,x3,x4,x5,…,xnS=x1,x2,x3,x4,x5,…,xn而言,它的概率:
P(S)=P(x1,x2,x3,x4,x5,…,xn)
=P(x1)P(x2|x1)P(x3|x1,x2)...P(xn|x1,x2,...,xn−1)
使用假设后,变成
P(x1)P(x2|x1)P(x3|x2)P(x4|x3)...P(xn|xn-1) 1-gram
P(x1)P(x2|x1)P(x3|x2,x1)P(x4|x3,x2)...P(xn|xn-1,xn-2) 2-gram
一般工程中选择3,也就是一个词仅与之前面的3个词相关,就可以了,n越大计算量指数级递增
传统语言模型的缺点是:

A:稀疏性 一些没出现的词概率为0,将直接影响概率的计算,,因此采取一些平滑处理,,比如拉普拉斯平滑、线性插值
B:泛化能力弱 依赖固定的模式匹,“舒适的酒店”和“温馨的宾馆”应该是相似的概率分布,传统语言模型学习不到
因此发展出神经网络语言模型
2、神经网络语言模型之NNLM
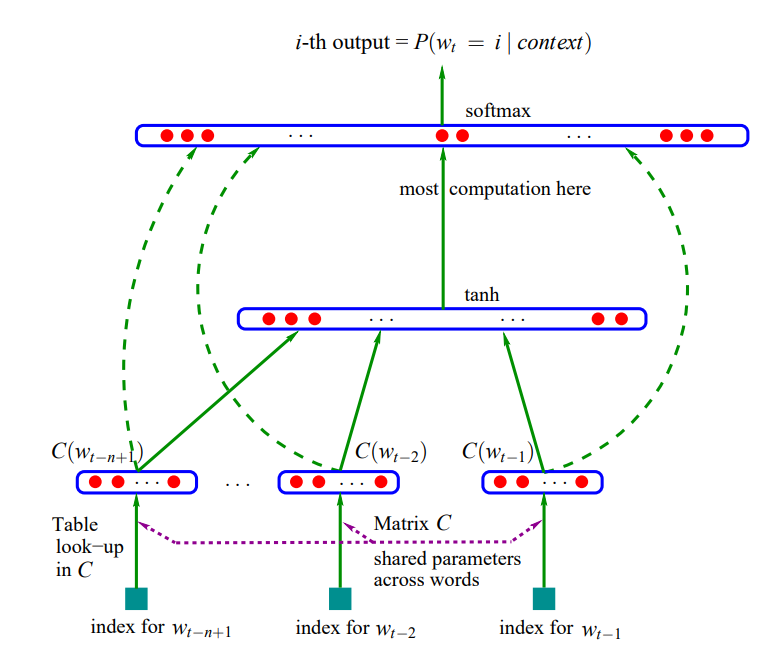
直接通过神经网络对n元条件概率进行统计
输入:前n-1个词的one-hot表示
将输入与一个V*M的矩阵相乘,V表示词汇表的大小,M表示映射后的维度
得到的n-1个词的映射后向量,每个都是1*M维,共n-1个,组合成一维的向量(n-1)*M,表示前n-1个词组成的词向量
接一个softmax计算得到的是预测词的概率,输出是1*V维的,表示在词汇表在最大概率出现的词,即为预测的下一个词
这里最重要的是得到了一个V*M的映射矩阵,对每个词来说都是乘以这个矩阵计算概率,因此这个矩阵就是词汇表中V个词的表示,每一行表示一个词对应的向量
3、代码
import tensorflow as tf
import numpy as np
tf.reset_default_graph()
sentences = [ "i like dog Luckid", "i love coffee mi", "i hate milk hello"]
word_list = " ".join(sentences).split()
word_list = list(set(word_list))
word_dict = {w: i for i, w in enumerate(word_list)}
number_dict = {i: w for i, w in enumerate(word_list)}
n_class = len(word_dict)
# NNLM Parameter
n_step = 3 # number of steps ['i like', 'i love', 'i hate']
n_hidden = 2 # number of hidden units
def make_batch(sentences):
input_batch = []
target_batch = []
for sen in sentences:
word = sen.split()
input = [word_dict[n] for n in word[:-1]]
target = word_dict[word[-1]]
input_batch.append(np.eye(n_class)[input])
target_batch.append(np.eye(n_class)[target])
return input_batch, target_batch
# Model
X = tf.placeholder(tf.float32, [None, n_step, n_class]) # [batch_size, number of steps, number of Vocabulary]
Y = tf.placeholder(tf.float32, [None, n_class])
input = tf.reshape(X, shape=[-1, n_step * n_class]) # [batch_size, n_step * n_class]
H = tf.Variable(tf.random_normal([n_step * n_class, n_hidden]))
d = tf.Variable(tf.random_normal([n_hidden]))
U = tf.Variable(tf.random_normal([n_hidden, n_class]))
b = tf.Variable(tf.random_normal([n_class]))
tanh = tf.nn.tanh(d + tf.matmul(input, H)) # [batch_size, n_hidden]
model = tf.matmul(tanh, U) + b # [batch_size, n_class]
cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits_v2(logits=model, labels=Y))
optimizer = tf.train.AdamOptimizer(0.001).minimize(cost)
prediction =tf.argmax(model, 1)
# Training
init = tf.global_variables_initializer()
sess = tf.Session()
sess.run(init)
input_batch, target_batch = make_batch(sentences)
for epoch in range(10000):
_, loss = sess.run([optimizer, cost], feed_dict={X: input_batch, Y: target_batch})
if (epoch + 1)%1000 == 0:
print('Epoch:', '%04d' % (epoch + 1), 'cost =', '{:.6f}'.format(loss))
# Predict
predict = sess.run([prediction], feed_dict={X: input_batch})
# Test
input = [sen.split()[:n_step] for sen in sentences]
print([sen.split()[:n_step] for sen in sentences], '->', [number_dict[n] for n in predict[0]])