第十二章 应用
2020-2-29 深度学习笔记12 - 深度学习应用 1(大规模深度学习)
2020-3-1 深度学习笔记12 - 深度学习应用 2(计算机视觉,语音识别)
自然语言处理NLP
统计语言建模的目标是学习语言中单词序列的联合概率函数。
自然语言处理让计算机能够使用人类语言,例如英语或法语。
为了让简单的程序能够高效明确地解析,计算机程序通常读取和发出特殊化的语言。 而自然的语言通常是模糊的,并且可能不遵循形式的描述。 自然语言处理中的应用如机器翻译,学习者需要读取一种人类语言的句子,并用另一种人类语言发出等同的句子。
许多NLP应用程序基于语言模型,语言模型定义了关于自然语言中的字、字符或字节序列的概率分布。
1.n-gram
参考https://blog.csdn.net/songbinxu/article/details/80209197。通俗易懂,比《机器学习》好理解多了。
语言模型定义了自然语言中标记序列的概率分布。 根据模型的设计,标记可以是词、字符、甚至是字节。 标记总是离散的实体。 最早成功的语言模型基于固定长度序列的标记模型,称为 n-gram。 一个 n-gram 是一个包含
个标记的序列。
n-gram是基于这样的想法,它的第一个特点是某个词的出现依赖于其他若干个词,第二个特点是我们获得的信息越多,预测越准确。我想说,我们每个人的大脑中都有一个n-gram模型,而且是在不断完善和训练的。我们的见识与经历,都在丰富着我们的阅历,增强着我们的联想能力。
n-gram 模型是一种语言模型(Language Model,LM),语言模型是一个基于概率的判别模型,它的输入是一句话(单词的顺序序列),输出是这句话的概率,即这些单词的联合概率(joint probability)。

n-gram本身也指一个由 n 个单词组成的集合,各单词具有先后顺序,且不要求单词之间互不相同。常用的有 Bi-gram (N=2) 和 Tri-gram (N=3),一般已经够用了。
例如,在上面这句话里,可以分解的 Bi-gram 和 Tri-gram :
Bi-gram : {I, love}, {love, deep}, {love, deep}, {deep, learning}
Tri-gram : {I, love, deep}, {love, deep, learning}
基于 n-gram 的模型定义一个条件概率——给定前 n-1 个标记后的第 n 个标记的条件概率。 该模型使用这些条件分布的乘积定义较长序列的概率分布:
这个分解可以由概率的链式法则证明。 初始序列
的概率分布可以通过带有较小
值的不同模型建模。
训练 n-gram 模型是简单的,因为最大似然估计可以通过简单地统计每个可能的 n-gram 在训练集中出现的次数来获得。
对于小的 值,模型有特定的名称: 称为一元语法, 称为二元语法及 称为三元语法。 这些名称源于相应数字的拉丁前缀和希腊后缀”-gram”,分别表示所写之物。
通常我们同时训练 n-gram 模型和 n-1 gram模型。 这使得下式可以简单地通过查找两个存储的概率来计算。
为了在
中精确地再现推断,我们训练
时必须省略每个序列最后一个字符。
例1:
以Bi-gram为例,我们有这样一个由三句话组成的语料库:

容易统计,“I”出现了3次,“I am”出现了2次,因此能计算概率:
同理,还能计算出如下概率:
,
,
,
,
例2:
1994 从加州一个餐厅的数据库中做了一些统计:



据统计,p(I∣<s>)=0.25,p(<s>∣food)=0.68,于是:
p(<s>I want chinese food<s>)=0.25×0.33×0.0065×0.52×0.68=1.896×10−4
我们算出了“I want chinese food”这句话的概率,但有时候这句话会很长,那么概率(都是小于1的常数)的相乘很可能造成数据下溢(downflow),即很多个小于1的常数相乘会约等于0,此时可以使用log概率解决。
关于出现下溢,《机器学习》一文说明如下:
n-gram 模型最大似然的基本限制是,在许多情况下从训练集计数估计得到的 很可能为零(即使元组 可能出现在测试集中)。这可能会导致两种不同的灾难性后果:
(1)当
为零时,该比率是未定义的,因此模型甚至不能产生有意义的输出。
(2)当
非零而
为零时,测试样本的对数似然为
。
为避免这种灾难性的后果,大多数 n-gram 模型采用某种形式的平滑。平滑技术将概率质量从观察到的元组转移到类似的未观察到的元组。
(1)一种基本技术基于向所有可能的下一个符号值添加非零概率质量。 这个方法可以被证明是,计数参数具有均匀或Dirichlet先验的贝叶斯推断。
(2)另一个非常流行的想法是包含高阶和低阶 n-gram 模型的混合模型,其中高阶模型提供更多的容量,而低阶模型尽可能地避免零计数。
N-gram的用途
(1)词性标注
“爱”这个词,它既可以作为动词使用,也可以作为名词使用。假设我们需要匹配一句话“xxx爱中国”中“爱”的词性。
我们可以将词性标注看成一个多分类问题,按照Bi-gram计算每一个词性概率:
选取概率更大的词性(比如动词)作为这句话中“爱”字的词性。
(2)垃圾短信分类
有一个垃圾短信如下,需要识别
"在家日赚百万,惊人秘密…"
在朴素贝叶斯的基础上,稍微对条件概率做一点改动即可。
条件概率不再是各词语之间独立:
垃圾短信分类问题可以总结为以下三个步骤:
- step1:给短信的每个句子断句。
- step2:用n-gram判断每个句子是否垃圾短信中的敏感句子。
- step3:若敏感句子个数超过一定阈值,认为整个邮件是垃圾短信。
(3)分词器Tokenizer
X 表示有待分词的句子,Y_i 表示该句子的一个分词方案。
X=“我爱深度学习”
Y1={“我”,“爱深”,“度学习”}
Y2={“我爱”,“深”,“度学”,“习”}
Y3={“我”,“爱”,“深度学习”}
p(Y1)=p(我)p(爱深∣我)p(度学习∣爱深)
p(Y2)=p(我爱)p(深∣我爱)p(度学∣深)p(习∣度学)
p(Y3)=p(我)p(爱∣我)p(深度学习∣爱)
三个概率中,“我爱”可能在语料库中比较常见,因此p(爱∣我)会比较大,然而“我爱深”这样的组合比较少见,于是p(爱深∣我)和p(深∣我爱)都比较小,导致p(Y3)比p(Y1)和p(Y2)都大,因此第三种分词方案最佳。
(4) 机器翻译
同一句话,可能有多种翻译方式,它们的区别仅在于单词的组合顺序,这时候使用N-gram分别计算各种情况的概率,选最大的那个即可。

(5) 语音识别
同一种发音,可能被解析成不同的句子,然而其中有一种更符合语法规则。

2-神经语言模型(neural language model,NLM)
神经语言模型是一类用来克服维数灾难的语言模型,它使用词的分布式表示对自然语言序列建模。不同于基于类class-based的 n-gram 模型,神经语言模型在能够识别两个相似的词,并且不丧失将每个词编码为彼此不同的能力。
神经语言模型共享一个词(及其上下文)和其他类似词(和上下文之间)的统计强度。模型为每个词学习的分布式表示,允许模型处理具有类似共同特征的词来实现这种共享。
例如,如果词dog和词cat映射到具有许多属性的表示,则包含词cat的句子可以告知模型对包含词dog的句子做出预测,反之亦然。因为这样的属性很多,所以存在许多泛化的方式,可以将信息从每个训练语句传递到指数数量的语义相关语句。维数灾难需要模型泛化到指数多的句子(指数相对句子长度而言)。该模型通过将每个训练句子与指数数量的类似句子相关联克服这个问题。
3-高维输出
在许多自然语言应用中,我们通常希望我们的模型产生词(而不是字符)作为输出的基本单位。
对于大词汇表,由于词汇量很大,在词的选择上表示输出分布的计算成本可能非常高。 在许多应用中, 包含数十万词。 表示这种分布的朴素方法是应用一个仿射变换,将隐藏表示转换到输出空间,然后应用softmax函数。
假设我们的词汇表 大小为 。 因为其输出维数为 ,描述该仿射变换线性分量的权重矩阵非常大。 这造成了表示该矩阵的高存储成本,以及与之相乘的高计算成本。
输出层的高计算成本在训练期间(计算似然性及其梯度)和测试期间(计算所有或所选词的概率)都有出现。 对于专门的损失函数,可以有效地计算梯度,但是应用于传统softmax输出层的标准交叉熵损失时会出现许多困难。
第一个神经语言模型通过将词汇量限制为10 000或20 000来减轻大词汇表上softmax的高成本。在这种方法的基础上建立新的方式,将词汇表 分为最常见词汇(由神经网络处理)的短列表 和较稀有词汇的尾列表 (由 n-gram 模型处理)。
为了组合这两个预测,神经网络还必须预测在上下文 之后出现的词位于尾列表的概率。 我们可以添加额外的sigmoid输出单元估计 实现这个预测。
短列表方法的一个明显缺点是,神经语言模型的潜在泛化优势仅限于最常用的词,这大概是最没用的。 这个缺点引发了处理高维输出替代方法的探索。
减少大词汇表
上高维输出层计算负担的经典方法是分层地分解概率。
这种层次结构是先建立词的类别,然后是词类别的类别,然后是词类别的类别的类别等。 这些嵌套类别构成一棵树,其叶子为词。。 在平衡树中,树的深度为
。 选择一个词的概率是由路径(从树根到包含该词叶子的路径)上的每个节点通向该词分支概率的乘积给出。
为了预测树的每个节点所需的条件概率,我们通常在树的每个节点处使用逻辑回归模型,并且为所有这些模型提供与输入相同的上下文 。 因为正确的输出编码在训练集中,我们可以使用监督学习训练逻辑回归模型。 我们通常使用标准交叉熵损失,对应于最大化正确判断序列的对数似然。
分层softmax的一个重要优点是,它在训练期间和测试期间(如果在测试时我们想计算特定词的概率)都带来了计算上的好处。
当然即使使用分层softmax,计算所有 个词概率的成本仍是很高的。 另一个重要的操作是在给定上下文中选择最可能的词。 不幸的是,树结构不能为这个问题提供高效精确的解决方案。
分层softmax的缺点是,在实践中倾向于更差的测试结果(相对基于采样的方法)。 这可能是因为词类选择得不好。
加速神经语言模型训练的一种方式是,避免明确地计算所有未出现在下一位置的词对梯度的贡献。每个不正确的词在此模型下具有低概率。枚举所有这些词的计算成本可能会很高。相反,我们可以仅采样词的子集。
为减少训练大词汇表的神经语言模型的计算成本,研究者也提出了其他基于采样的方法。最近用于神经语言模型的训练目标是噪声对比估计。
4-结合 n-gram 和神经语言模型
n-gram 和神经语言模型有什么异同点?
- 共同点:都是计算语言模型,将句子看作一个词序列,来计算句子的概率
- 不同点:
- 计算概率方式不同,n-gram基于马尔可夫假设只考虑前n个词,nnlm要考虑整个句子的上下文
- 训练模型的方式不同,n-gram基于最大似然估计来计算参数,nnlm基于RNN的优化方法来训练模型,并且这个过程中往往会有word embedding作为输入,这样对于相似的词可以有比较好的计算结果,但n-gram是严格基于词本身的
- 循环神经网络可以将任意长度的上下文信息存储在隐藏状态中,而不仅限于n-gram模型中的窗口限制
n-gram 模型相对神经网络的主要优点是 n-gram 模型具有更高的模型容量(通过存储非常多的元组的频率),并且处理样本只需非常少的计算量(通过查找只匹配当前上下文的几个元组)。 如果我们使用哈希表或树来访问计数,那么用于 n-gram 的计算量几乎与容量无关。 相比之下,将神经网络的参数数目加倍通常也大致加倍计算时间。
因此,增加容量的一种简单方法是将两种方法结合,由神经语言模型和 n-gram 语言模型组成集成。模型容量的增加是巨大的(架构的新部分包含高达|sV|n个参数),但是处理输入所需的额外计算量是很小的(因为额外输入非常稀疏)。
5-神经机器翻译NMT
神经网络机器翻译(Neural Machine Translation, NMT)是最近几年提出来的一种机器翻译方法。相比于传统的统计机器翻译(SMT)而言,NMT能够训练一张能够从一个序列映射到另一个序列的神经网络,输出的可以是一个变长的序列,这在翻译、对话和文字概括方面能够获得非常好的表现。
机器翻译的趋势是让机器更“自主”的学习如何翻译,大致可以分为三个阶段
(1)1980到1990年之间,大多都是基于规则的翻译:转化法(transfer-based)、中间语法(interlingual)、以及辞典法(dictionary-based)等
(2)1990年到2013年之间,基于统计的翻译,利用数学统计规律进行翻译。本文开始时候介绍的n-gram模型
(3)2013年之后,主流的方法开始使用基于神经网络的翻译,主要是使用深度学习的方法。

目前为止,在机器翻译中性能最好的是2014年提出神经机器翻译模型(NMT)。
NMT其实是一个encoder-decoder系统,encoder把源语言序列进行编码,并提取源语言中信息,通过decoder再把这种信息转换到另一种语言即目标语言中来,从而完成对语言的翻译。
但是,如果只是让encoder将源语言压缩成固定的向量时,意味着将所有的重要信息进行了压缩,那么当输入的源语言越来越长时,就会丢失一些重要信息,最终导致翻译的性能下降。
为了解决这个问题,2014年Cho和Sutskever等人提出了基于联合学习对齐和翻译的神经翻译模型。大致思想是:将输入的源语言不再压缩成固定的向量,而是将他们编码成一系列灵活的向量,当decoder对每一个单词进行翻译时,会考虑与该单词相关的向量,自适应的选择这些重要的信息,然后基于上下文和这些重要信息来对该单词进行翻译。这样做就更符合我们人类翻译的步骤,先对每个单词进行翻译,然后根据上下文进行调整,最终得到我们满意的结果。
RNN(Recurrent Neural Network,循环神经网络)具备了允许模型具有可变输入长度和输出长度的能力。
在所有情况下,一个模型首先读取输入序列并产生概括输入序列的数据结构。我们称这个概括为”上下文” 。 上下文 可以是向量列表,或者向量或张量。 读取输入以产生 的模型可以是RNN或卷积网络。 另一个模型(通常是RNN),则读取上下文 并且生成目标语言的句子。
NMT实现过程参见https://www.cnblogs.com/yunkaiL/p/11040687.html
从概率学的角度来看,机器翻译其实就是对给定源语言x的条件下,寻找输出为y的目标语言的最大概率,即argmaxyp(y|x)。

假设源语言的输入为1,2,3,…,Tx,源语言转换成的向量模式为x=(x1,…,xTx),通过RNN网络要得到隐藏状态,而当前的隐藏状态是由上一个隐藏状态和当前的输入所共同决定,即

获得了各个时间段的隐藏层以后,再将隐藏层的信息汇总,生成最后该句子的上下文的向量c
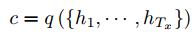
其中 ht∈Rn 表示 t 时刻的隐藏状态,f 和 q 是非线性激活函数。一种简单的方法是将最后的隐藏层作为上下文向量 c
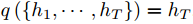
解码阶段可以看做编码的逆过程,decoder根据给定的上下文向量c和已经生成的单词y1,…,yt−1来预测下一个生成的单词 yt
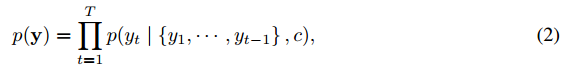
其中y=(y1,…,yTy),其中的条件概率模型也可以写成
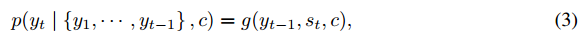
其中 g 是非线性激活函数,yt−1 表示上一个阶段隐藏层的输出,st 表示当前RNN的隐藏层的状态,c表示前面提到的上下文向量。最终句子的输出其实就是求该条件概率的最大乘积,即argmaxp(yt)
使用固定大小的表示概括非常长的句子(例如60个词)的所有语义细节是非常困难的。 这需要使用足够大的RNN,并且用足够长时间训练得很好才能实现。 更高效的方法是先读取整个句子或段落(以获得正在表达的上下文和焦点),然后一次翻译一个词,每次聚焦于输入句子的不同部分来收集产生下一个输出词所需的语义细节。这种方法称为基于attention的NMT。

相比于之前的encoder-decoder模型,attention模型最大的区别就在于它不再要求编码器将所有输入信息都编码进一个固定长度的向量之中。相反,此时编码器需要将输入编码成一个向量的序列,而在解码的时候,每一步都会选择性的从向量序列中挑选一个子集进行进一步处理。这样,在产生每一个输出的时候,都能够做到充分利用输入序列携带的信息。而且这种方法在翻译任务中取得了非常不错的成果。
具体实现略。
6-历史展望
自然语言处理的历史是由流行表示(对模型输入不同方式的表示)的变化为标志的。 在早期对符号和词建模的工作之后,神经网络在NLP上一些最早的应用将输入表示为字符序列。
最初,使用词作为语言模型的基本单元可以改进语言建模的性能。 而今,新技术不断推动基于字符和基于词的模型向前发展,最近的工作甚至建模Unicode字符的单个字节。
神经语言模型背后的思想已经扩展到多个自然语言处理应用,如解析、词性标注、语义角色标注、分块等,有时使用共享词嵌入的单一多任务学习架构。
