原理图
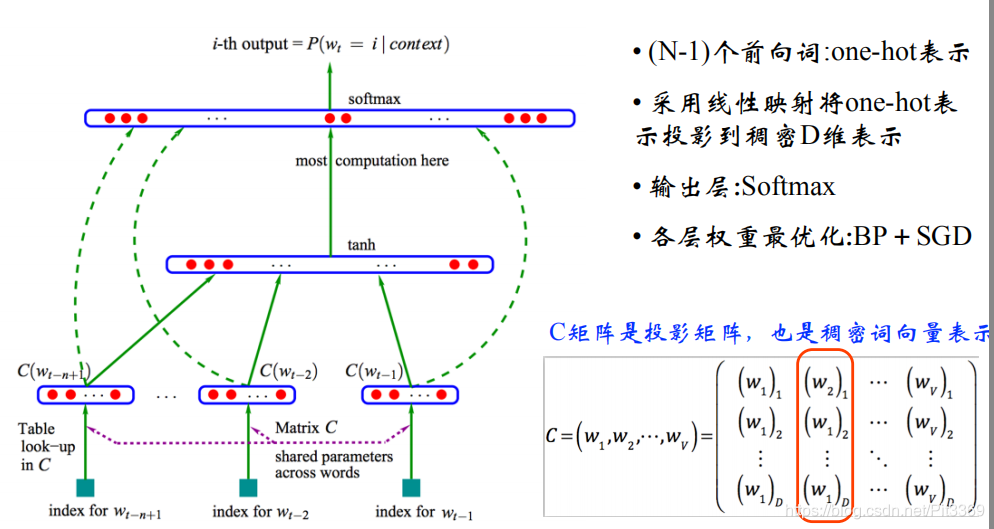
运用场景:
知道句子的前N-1个词,来预测第N个词。
网络的流程:
1.词语one-hot编码—————2.projection_layer层————3.hidden_layer层——————4.SoftMax层
1准备工作
这个代码是我在GitHub上看到的,原代码是针对英文,英文比较简单。我修改下针对中文。并给出Keras版代码。
import numpy as np
import tensorflow as tf
import re
sentences = [ "我爱你", "余登武", "范冰冰"]
#分字
def seg_char(sent):
pattern = re.compile(r'([\u4e00-\u9fa5])')
chars = pattern.split(sent)
chars =[w for w in chars if len(w.strip()) > 0]
return chars
chars=np.array([seg_char(i)for i in sentences])
chars=chars.reshape(1,-1)
#chars[['我' '爱' '你' '余' '登' '武' '范' '冰' '冰']]
word_list=np.squeeze(chars)#降维
#word_list['我' '爱' '你' '余' '登' '武' '范' '冰' '冰']
word_list = list(set(word_list))
word_dict = {w: i for i, w in enumerate(word_list)}
#word_dict{'余': 0, '武': 1, '你': 2, '范': 3, '登': 4, '我': 5, '冰': 6, '爱': 7}
number_dict = {i: w for i, w in enumerate(word_list)}
#number_dict{0: '登', 1: '武', 2: '冰', 3: '我', 4: '余', 5: '范', 6: '你', 7: '爱'}
n_class = len(word_dict) # number of Vocabulary
2输入输出one-hot编码
# NNLM Parameter
n_step = 2 # number of steps ['我 爱', '范 冰', '余 登']
n_hidden = 2 # number of hidden units
def make_batch(sentences):
input_batch = []
target_batch = []
for sen in sentences:
word = seg_char(sen)#分字
input = [word_dict[n] for n in word[:-1]]
target = word_dict[word[-1]]
input_batch.append(np.eye(n_class)[input])
target_batch.append(np.eye(n_class)[target])
return input_batch, target_batch
input_batch, target_batch=make_batch(sentences)

3模型
# Model
X = tf.placeholder(tf.float32, [None, n_step, n_class]) # [batch_size, number of steps, number of Vocabulary]
Y = tf.placeholder(tf.float32, [None, n_class])
input = tf.reshape(X, shape=[-1, n_step * n_class]) # [batch_size, n_step * n_class]
H = tf.Variable(tf.random_normal([n_step * n_class, n_hidden]))
d = tf.Variable(tf.random_normal([n_hidden]))
U = tf.Variable(tf.random_normal([n_hidden, n_class]))
b = tf.Variable(tf.random_normal([n_class]))
tanh = tf.nn.tanh(d + tf.matmul(input, H)) # [batch_size, n_hidden]
model = tf.matmul(tanh, U) + b # [batch_size, n_class]
cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits_v2(logits=model, labels=Y))
optimizer = tf.train.AdamOptimizer(0.001).minimize(cost)
prediction =tf.argmax(model, 1)
4训练
# Training
init = tf.global_variables_initializer()
sess = tf.Session()
sess.run(init)
for epoch in range(5000):
_, loss = sess.run([optimizer, cost], feed_dict={X: input_batch, Y: target_batch})
if (epoch + 1)%1000 == 0:
print('Epoch:', '%04d' % (epoch + 1), 'cost =', '{:.6f}'.format(loss))
# Predict
predict = sess.run([prediction], feed_dict={X: input_batch})
5测试
# Test
input = [seg_char(sen)[:2] for sen in sentences]
print([seg_char(sen)[:2] for sen in sentences], '预测得到->', [number_dict[n] for n in predict[0]])

全文代码
import numpy as np
import tensorflow as tf
import re
sentences = [ "我爱你", "余登武", "范冰冰"]
def seg_char(sent):
pattern = re.compile(r'([\u4e00-\u9fa5])')
chars = pattern.split(sent)
chars =[w for w in chars if len(w.strip()) > 0]
return chars
chars=np.array([seg_char(i)for i in sentences])
chars=chars.reshape(1,-1)
word_list=np.squeeze(chars)
##word_list['我' '爱' '你' '余' '登' '武' '范' '冰' '冰']
word_list = list(set(word_list))
word_dict = {w: i for i, w in enumerate(word_list)}
#word_dict{'余': 0, '武': 1, '你': 2, '范': 3, '登': 4, '我': 5, '冰': 6, '爱': 7}
number_dict = {i: w for i, w in enumerate(word_list)}
#{0: '登', 1: '武', 2: '冰', 3: '我', 4: '余', 5: '范', 6: '你', 7: '爱'}
n_class = len(word_dict) # number of Vocabulary
# NNLM Parameter
n_step = 2 # number of steps ['我 爱', '范 冰', '余 登']
n_hidden = 2 # number of hidden units
def make_batch(sentences):
input_batch = []
target_batch = []
for sen in sentences:
word = seg_char(sen)#分字
input = [word_dict[n] for n in word[:-1]]
target = word_dict[word[-1]]
input_batch.append(np.eye(n_class)[input])
target_batch.append(np.eye(n_class)[target])
return input_batch, target_batch
input_batch, target_batch=make_batch(sentences)
# Model
X = tf.placeholder(tf.float32, [None, n_step, n_class]) # [batch_size, number of steps, number of Vocabulary]
Y = tf.placeholder(tf.float32, [None, n_class])
input = tf.reshape(X, shape=[-1, n_step * n_class]) # [batch_size, n_step * n_class]
H = tf.Variable(tf.random_normal([n_step * n_class, n_hidden]))
d = tf.Variable(tf.random_normal([n_hidden]))
U = tf.Variable(tf.random_normal([n_hidden, n_class]))
b = tf.Variable(tf.random_normal([n_class]))
tanh = tf.nn.tanh(d + tf.matmul(input, H)) # [batch_size, n_hidden]
model = tf.matmul(tanh, U) + b # [batch_size, n_class]
cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits_v2(logits=model, labels=Y))
optimizer = tf.train.AdamOptimizer(0.001).minimize(cost)
prediction =tf.argmax(model, 1)
# Training
init = tf.global_variables_initializer()
sess = tf.Session()
sess.run(init)
for epoch in range(5000):
_, loss = sess.run([optimizer, cost], feed_dict={X: input_batch, Y: target_batch})
if (epoch + 1)%1000 == 0:
print('Epoch:', '%04d' % (epoch + 1), 'cost =', '{:.6f}'.format(loss))
# Predict
predict = sess.run([prediction], feed_dict={X: input_batch})
# Test
input = [seg_char(sen)[:2] for sen in sentences]
print([seg_char(sen)[:2] for sen in sentences], '预测得到->', [number_dict[n] for n in predict[0]])
Keras 版代码
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
# @Author: yudengwu
# @Date : 2020/8/26
from keras.models import Sequential
import numpy as np
import tensorflow as tf
import re
sentences = [ "我爱你", "余登武", "范冰冰"]
#分字
def seg_char(sent):
pattern = re.compile(r'([\u4e00-\u9fa5])')
chars = pattern.split(sent)
chars =[w for w in chars if len(w.strip()) > 0]
return chars
chars=np.array([seg_char(i)for i in sentences])
chars=chars.reshape(1,-1)
word_list=np.squeeze(chars)
##word_list['我' '爱' '你' '余' '登' '武' '范' '冰' '冰']
word_list = list(set(word_list))
word_dict = {w: i for i, w in enumerate(word_list)}
#word_dict{'余': 0, '武': 1, '你': 2, '范': 3, '登': 4, '我': 5, '冰': 6, '爱': 7}
number_dict = {i: w for i, w in enumerate(word_list)}
#{0: '登', 1: '武', 2: '冰', 3: '我', 4: '余', 5: '范', 6: '你', 7: '爱'}
n_class = len(word_dict) # number of Vocabulary
# NNLM Parameter
n_step = 2 # number of steps ['我 爱', '范 冰', '余 登']
#输入输出onr-hot化
def make_batch(sentences):
input_batch = []
target_batch = []
for sen in sentences:
word = seg_char(sen)#分字
input = [word_dict[n] for n in word[:-1]]
target = word_dict[word[-1]]
input_batch.append(np.eye(n_class)[input])
target_batch.append(np.eye(n_class)[target])
return input_batch, target_batch
input_batch, target_batch=make_batch(sentences)
input_batch=np.array(input_batch)
input_batch=input_batch.reshape(-1,n_step*n_class)
target_batch=np.array(target_batch)
target_batch=target_batch.reshape(-1,n_class)
from keras.layers import Dense
import keras
#模型
def define_model():
model = Sequential()
model.add(Dense(2,activation='tanh',input_shape=(n_step*n_class,)))
model.add(Dense(n_class, activation='softmax')) # 输出层
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
model.summary()
return model
model=define_model()
model.fit(input_batch, target_batch, epochs=5000)#训练5000轮,数据少啦,一两轮没效果
#预测测试
predict=model.predict(input_batch)
predict=np.argmax(predict,1)#求取最大值索引
print('输入的是:',[seg_char(sen)[:2] for sen in sentences])
print('预测得到:',[number_dict[n] for n in predict])

NNLM 缺点:如果词语太多,会造成维度过大问题。
可以取出中间层权重 即wordvec方法。
NNLM也可以做文本生成的。for循环,加随机采样。
可以看下另一篇博客文本生成。

电气专业的计算机萌新,写博文不容易。如果你觉得本文对你有用,请点个赞支持下,谢谢。
