深度神经网络(DNN)反向传播的公式推导可以参考之前的博客:https://transformerswsz.github.io/2019/05/29/反向传播/。
要套用DNN的反向传播算法到CNN,有几个问题需要解决:
- 池化层没有激活函数,我们可以令池化层的激活函数为
g(z)=z,即激活后输出本身,激活函数的导数为1。
- 池化层在前向传播的时候,对输入矩阵进行了压缩,我们需要反向推导出
δl−1,这个方法与DNN完全不同。
- 卷积层通过张量卷积,或者说若干个矩阵卷积求和得到当前层的输出,而DNN的全连接层是直接进行矩阵乘法而得到当前层的输出。我们需要反向推导出
δl−1,计算方法与DNN也不同。
- 对于卷积层,由于
W 使用的是卷积运算,那么从
δl 推导出该层的filter的
W,b 方式也不同。
在研究过程中,需要注意的是,由于卷积层可以有多个卷积核,各个卷积核的处理方法是完全相同且独立的,为了简化算法公式的复杂度,我们下面提到卷积核都是卷积层中若干卷积核中的一个。
下面将对上述问题进行逐一分析:
已知池化层的
δl,推导上一隐藏层的
δl−1
在前向传播算法时,池化层一般我们会用MAX或者Average对输入进行池化,池化的区域大小已知。现在我们反过来,要从缩小后的误差 $ \delta^l $,还原前一次较大区域对应的误差。
在反向传播时,我们首先会把 $ \delta^l $ 的所有子矩阵矩阵大小还原成池化之前的大小,然后如果是MAX,则把 $ \delta^l $ 的所有子矩阵的各个池化局域的值放在之前做前向传播算法得到最大值的位置。如果是Average,则把 $ \delta^l $ 的所有子矩阵的各个池化局域的值取平均后放在还原后的子矩阵位置。这个过程一般叫做
upsample。
示例
假设池化区域为2*2,步长为2,
δl 的第k个子矩阵为:
δkl=(2486)
我们先将
δkl 还原,即变成:
⎝⎜⎜⎛0000024028608000⎠⎟⎟⎞
如果是MAX,假设我们之前在前向传播时记录的最大值位置分别是左上、右下、右上、左下,则转换后的矩阵为:
⎝⎜⎜⎛2000004000060800⎠⎟⎟⎞
如果是Average,转换后的矩阵为:
⎝⎜⎜⎛0.50.5110.50.511221.51.5221.51.5⎠⎟⎟⎞
这样我们就得到了上一层
∂akl−1∂J(W,b) ,要得到
δkl−1 :
δkl−1=(∂zkl−1∂akl−1)T∂akl−1∂J(W,b)=upsample(δkl)⊙σ′(zkl−1)
其中,
upsample 函数完成了池化误差矩阵放大与误差重新分配的逻辑。
对于张量
δl ,我们有:
δl−1=upsample(δl)⊙σ′(zl−1)
已知卷积层的
δl,推导上一层隐藏层的
δl−1
在DNN中,我们知道
δl−1 和
δl 的递推关系为:
δl−1=∂zl−1∂J(W,b)=(∂zl−1∂zl)T∂zl∂J(W,b)=(∂zl−1∂zl)Tδl
注意到
zl 和
zl−1 的关系为:
zl=al−1∗Wl+bl=σ(zl−1)∗Wl+bl
因此我们有:
δl−1=(∂zl−1∂zl)Tδl=δl∗rot180(Wl)⊙σ′(zl−1)
这里的式子其实和DNN的类似,区别在于对于含有卷积的式子求导时,卷积核被旋转了180度。即式子中的
rot180(),翻转180度的意思是上下翻转一次,接着左右翻转一次。在DNN中这里只是矩阵的转置。那么为什么呢?由于这里都是张量,直接推演参数太多了。我们以一个简单的例子说明为啥这里求导后卷积核要翻转。
假设我们
l−1 层的输出
al−1 是一个3*3的矩阵,第
l 层的卷积核
Wl 是一个2*2矩阵,步幅为1,则输出
zl 是一个 2*2的矩阵,这里
bl 简化为0,则有:
al−1∗Wl=zl
我们列出
a,W,z 的矩阵表达式如下:
⎝⎛a11a21a31a12a22a32a13a23a33⎠⎞∗(w11w21w12w22)=(z11z21z12z22)
根据卷积得出:
z11=a11w11+a12w12+a21w21+a22w22z12=a12w11+a13w12+a22w21+a23w22z21=a21w11+a22w12+a31w21+a32w22z22=a22w11+a23w12+a32w21+a33w22
接着我们模拟反向求导:
▽al−1=∂al−1∂J(W,b)=(∂al−1∂zl)T∂zl∂J(W,b)=(∂al−1∂zl)Tδl
从上式可以看出,对于
al−1 的梯度误差
▽al−1 ,等于第
l 层的梯度误差乘以
∂al−1∂zl ,而
∂al−1∂zl 对应上面的例子中相关联的
w 的值。假设
z 矩阵对应的反向传播误差是
δ11,δ12,δ21,δ22 组成的2*2矩阵,则利用上面梯度的式子和4个等式,我们可以分别写出
▽al−1 的9个标量的梯度。
比如对于
a11 的梯度,由于在4个等式中
a11 只和
z11 有乘积关系,从而我们有:
▽a11=w11δ11
对于
a12 的梯度,由于在4个等式中
a12 和
z11,z12 有乘积关系,从而我们有:
▽a12=w11δ12+w12δ11
同理可得:
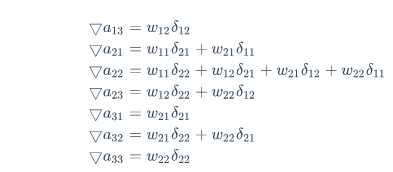
这上面9个式子其实可以用一个矩阵卷积的形式表示,即:
⎝⎜⎜⎛00000δ11δ2100δ12δ2200000⎠⎟⎟⎞∗(w22w12w21w11)=⎝⎛▽a11▽a21▽a31▽a12▽a22▽a32▽a13▽a23▽a33⎠⎞
为了符合梯度计算,我们在误差矩阵周围填充了一圈0,此时我们将卷积核翻转后和反向传播的梯度误差进行卷积,就得到了前一次的梯度误差。这个例子直观的介绍了为什么对含有卷积的式子反向传播时,卷积核要翻转180度的原因。
以上就是卷积层的误差反向传播过程。
已知卷积层的
δl,推导该层的
W,b 的梯度
对于全连接层,可以按DNN的反向传播算法求该层
W,b 的梯度,而池化层并没有
W,b ,也不用求
W,b 的梯度。只有卷积层的
W,b 需要求出。
注意到卷积层
z 和
W,b 的关系为:
zl=al−1∗Wl+b
因此我们有:
∂Wl∂J(W,b)=al−1∗δl
注意到此时卷积核并没有反转,主要是此时是层内的求导,而不是反向传播到上一层的求导。具体过程我们可以分析一下。
这里举一个简化的例子,这里输入是矩阵,不是张量,那么对于第
l 层,某个卷积核矩阵
W 的导数可以表示如下:
∂Wpql∂J(W,b)=i∑j∑(δijlai+p−1,j+q−1l−1)
那么根据上面的式子,我们有:
∂W11l∂J(W,b)=a11δ11+a12δ12+a21δ21+a22δ22∂W12l∂J(W,b)=a12δ11+a13δ12+a22δ21+a23δ22∂W13l∂J(W,b)=a13δ11+a14δ12+a23δ21+a24δ22......∂W33l∂J(W,b)=a33δ11+a34δ12+a43δ21+a44δ22
最终我们可以一共得到9个式子。整理成矩阵形式后可得:
∂Wl∂J(W,b)=⎝⎜⎜⎛a11a21a31a41a12a22a32a42a13a23a33a43a14a24a34a44⎠⎟⎟⎞∗(δ11δ21δ12δ22)
从而可以清楚的看到这次我们为什么没有反转的原因。
而对于
b,则稍微有些特殊,因为
δl 是高维张量,而
b 只是一个向量,不能像DNN那样直接和
δl 相等。通常的做法是将
δl 的各个子矩阵的项分别求和,得到一个误差向量,即为
b 的梯度:
∂bl∂J(W,b)=u,v∑(δl)u,v
CNN反向传播算法总结
现在我们总结下CNN的反向传播算法,以最基本的批量梯度下降法为例来描述反向传播算法。
输入:m个图片样本,CNN模型的层数L和所有隐藏层的类型,对于卷积层,要定义卷积核的大小K,卷积核子矩阵的维度F,填充大小P,步幅S。对于池化层,要定义池化区域大小k和池化标准(MAX或Average),对于全连接层,要定义全连接层的激活函数(输出层除外)和各层的神经元个数。梯度学习率
α,最大迭代次数MAX与停止迭代阈值
ϵ
输出:CNN模型各隐藏层与输出层的
W,b
- 初始化各隐藏层与输出层的各
W,b 的值为一个随机值。
- for iter to 1 to MAX:
- for i =1 to m:
- 将CNN输入
a1 设置为
xi 对应的张量
- for l = 2 to L-1,根据下面3种情况进行前向传播算法计算:
- 如果当前是全连接层:则有
ai,l=σ(zi,l)=σ(Wlai,l−1+bl)
- 如果当前是卷积层:则有
ai,l=σ(zi,l)=σ(Wl∗ai,l−1+bl)
- 如果当前是池化层:则有
ai,l=pool(ai,l−1)
- 对于输出层第L层:
ai,L=softmax(zi,L)=softmax(WLai,L−1+bL)
- 通过损失函数计算输出层的
δi,L
- for l = L-1 to 2, 根据下面3种情况进行进行反向传播算法计算:
- 如果当前是全连接层:
δi,l=(Wl+1)Tδi,l+1⊙σ′(zi,l)
- 如果当前是卷积层:
δi,l=δi,l+1∗rot180(Wl+1)⊙σ′(zi,l)
- 如果当前是池化层:
δi,l=upsample(δi,l+1)⊙σ′(zi,l)
- for l = 2 to L,根据下面2种情况更新第
l 层的
Wl,bl:
- 如果当前是全连接层:
Wl=Wl−α∑i=1mδi,l(ai,l−1)T,bl=bl−α∑i=1mδi,l
- 如果当前是卷积层,对于每一个卷积核有:
Wl=Wl−α∑i=1mδi,l∗ai,l−1,bl=bl−α∑i=1m∑u,v(δi,l)u,v
- 如果所有的
W,b 的变化值都小于停止迭代阈值
ϵ,则跳出迭代循环到步骤3。
- 输出各隐藏层与输出层的线性关系系数矩阵
W 和偏置量
b 。
转载自:https://www.cnblogs.com/pinard/p/6494810.html?tdsourcetag=s_pcqq_aiomsg