 版权声明:署名,允许他人基于本文进行创作,且必须基于与原先许可协议相同的许可协议分发本文 (Creative Commons)
版权声明:署名,允许他人基于本文进行创作,且必须基于与原先许可协议相同的许可协议分发本文 (Creative Commons)
原文链接:https://www.cnblogs.com/tecdat/p/11077424.html
Twitter是一个流行的社交网络,这里有大量的数据等着我们分析。Twitter R包是对twitter数据进行文本挖掘的好工具。本文是关于如何使用Twitter R包获取twitter数据并将其导入R,然后对它进行一些有趣的数据分析。

第一步是注册一个你的应用程序。
为了能够访问Twitter数据编程,我们需要创建一个与Twitter的API交互的应用程序。
注册后你将收到一个密钥和密码:
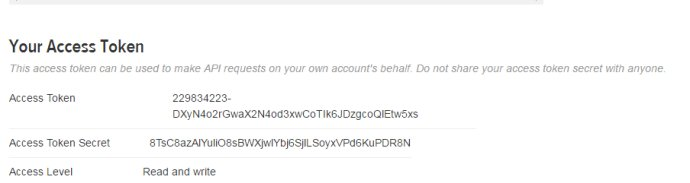
获取密钥和密码后便可以在R里面授权我们的应用程序以代表我们访问Twitter:

根据不同的搜索词,我们可以在几分钟之内收集到成千上万的tweet。这里我们测试一个关键词 littlecaesars的twitter结果:
抓取最新的1000条相关twitter
由于默认的抓取结果是json格式,因此使用twlisttodf函数将其转换成数据框
然后我们做一些简单的文本清理
从得到的数据里,我们可以看到有twitter发表时间,内容,经纬度等信息
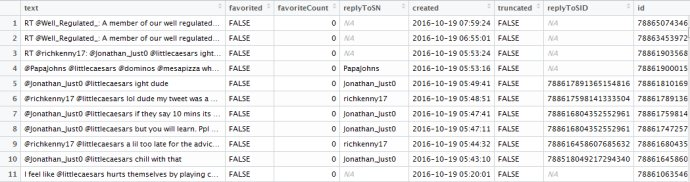
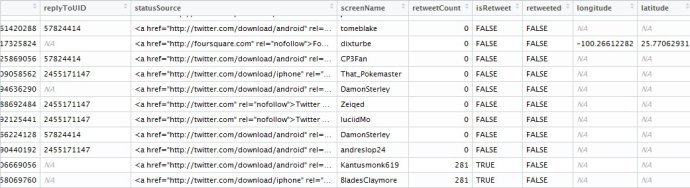
在清理数据之后,我们对twitter内容进行分词,以便进行数据可视化

分词之后可以得到相关twitter的高频词汇,然后将其可视化
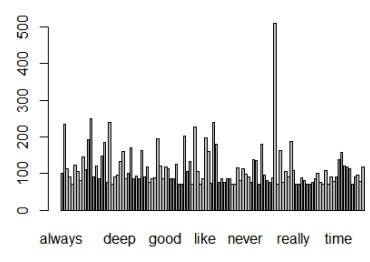

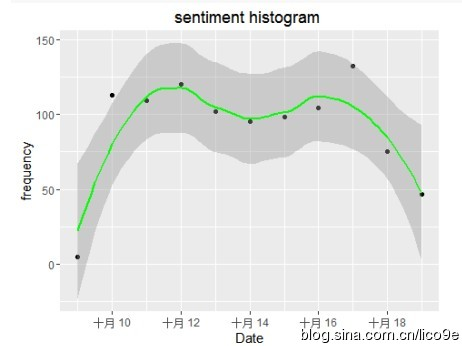
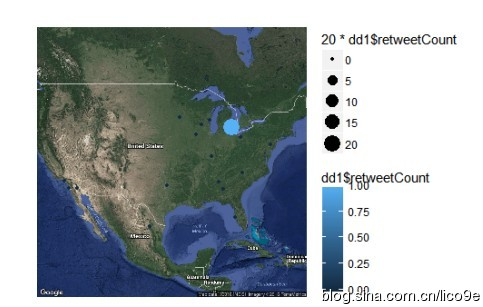
除此之外,还可以结合数据中的时间戳数据和地理数据进行可视化分析
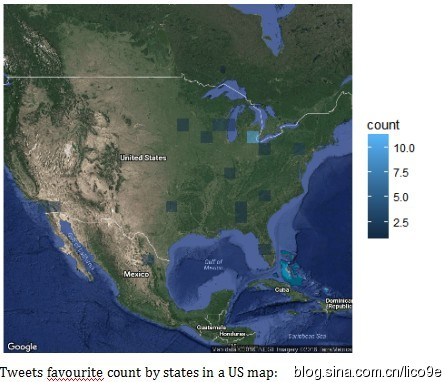
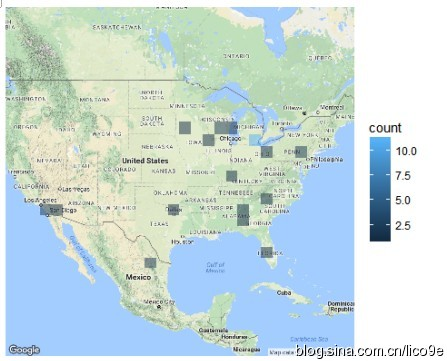
如果你一直在考虑对一些文本数据应用情感分析,你可能会发现使用R比你想象的更容易!
=====================================================