关于抑郁的Twitter情感分析
介绍
抑郁对全球公共健康带来了巨大挑战。每天,数百万人患有抑郁症,只有很少一部分人接受适当的治疗。过去,医生通常通过面对面的对话使用诊断标准来确定抑郁(如DSM-5抑郁症诊断标准)来诊断患者。然而,先前的研究表明,大多数患者在抑郁的早期阶段不会寻求医生的帮助,这将导致他们的心理健康下降。另一方面,许多人每天都使用社交媒体平台分享自己的情感。从那时起,关于使用社交媒体预测心理和身体疾病的研究已经很多,如心脏停搏、寨卡病毒以及处方药滥用的心理健康。这项研究关注使用社交媒体数据来检测社交媒体用户的抑郁思绪。本质上,该研究结合了文本分析,并专注于从书面交流中提取见解,以得出数据是否与抑郁思绪有关的结论。
本项目旨在分享他们的心理健康感受,判断是否存在焦虑和抑郁,对数据集进行EDA分析,并对Twitter文本进行情感分析。
数据
数据以未经清洗的格式收集,使用Twitter API进行收集。数据已被过滤,仅保留了英文内容。它针对的是用户在推文级别的心理健康分类。
- post_id:帖子的ID
- post_created:帖子创建时间
- post_text:未经清洗的推文文本
- user_id:用户标识
- followers:粉丝数量
- friends:好友数量
- favourites:收藏数量
- statuses:总状态数
- redata:当前推文的转发总数
- label:用于分类的标签(1表示抑郁,0表示无抑郁)
此示例的目标是使用监控数据来估计预测模型,并确定用户是否患有抑郁症。
换句话说,我们希望构建一个模型,可以根据其内容将数据分类为“抑郁”和“无抑郁”。我可以想出许多原因,为什么这种事情如此酷。我提出的原因之一是可以根据用户的情绪来判断他们的心理状况,并推广相关产品。例如,患有抑郁症的人可以推广药物。药物是治疗抑郁症最有效的方法之一,因此,将推文分类为“抑郁”和“无抑郁”对此非常有用。该项目的步骤如下:1. 对文本进行初步清理。2. 数据可视化。3. 使用“tm”包将其转换为格式。4. 将数据分成“训练”和“测试”集。5. 使用“一次性热编码”方法定义分类模型的“特征”。6. 在“e1071”包中应用朴素贝叶斯算法于“训练”数据。7. 使用该模型从“测试”数据中进行预测。
数据清理
接下来,下载数据集并使用以下代码进行读取:
我要做的第一件事是将“label”字段强制转换为因子,而不是值。
##
## no depression depression
## 10000 10000
有10000条抑郁数据和10000条无抑郁数据
这第二步有点小技巧。我尝试过使用tidyr和tm包来处理文本挖掘应用。它们都具有内置的功能,可以清理正则表达式和其他从文本数据中提取复杂内容的功能。由于某种原因,我在处理某些特殊字符(如非ASCII或转义字符)时一直遇到问题。在这里,我使用了一个简单的gsub()操作,将推文文本中的一些内容清除掉。
“词袋”模型会将每个推文视为一大袋词语。使用tm包来组织数据,我们首先要做的是创建一个语料库(Corpus)。语料库是一个文档集合。在这种情况下,每个推文都是一个文档。
## <<SimpleCorpus>>
## Metadata: corpus specific: 1, document level (indexed): 0
## Content: documents: 20000
现在我们有一个包含20000个文档(数据)的语料库。
tm包具有一些内置方法,可以去除标点符号和停用词等内容。我们将使用这些方法从语料库中删除一些内容:
## <<SimpleCorpus>>
## Metadata: corpus specific: 1, document level (indexed): 0
## Content: documents: 5
##
## [1] just year sinc diagnos anxieti depress today im take moment reflect far ive come sinc
## [2] sunday need break im plan spend littl time possibl
## [3] awak tire need sleep brain idea
## [4] rt sewhq retro bear make perfect gift great beginn get stitch octob sew sale now yay httptco
## [5] hard say whether pack list make life easier just reinforc much still need movinghous anxieti
数据可视化
词云提供了一种直观的方式来可视化语料库中词汇的频率。
词在语料库中出现的频率越高,其词体大小在词云中就越大。
我们可以通过使用wordcloud包中的wordcloud()函数轻松创建词云。
绘制没有抑郁的人的推文中的单词

绘制有抑郁的人的推文中的单词

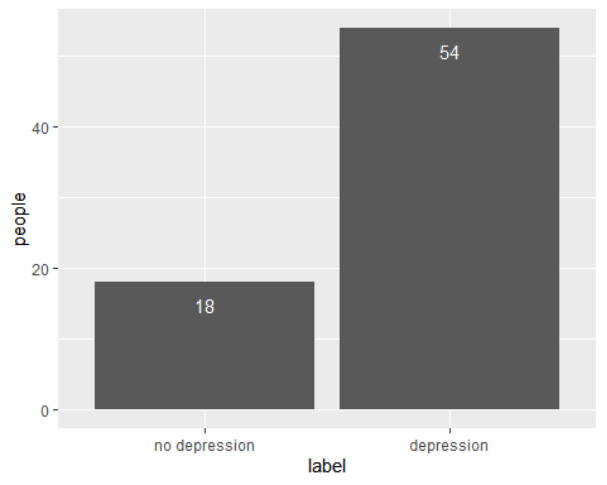
在20000条推文中,许多用户重复发推。总共调查了72名用户,其中54名患有抑郁,另外18名没有抑郁。
文档矩阵
在下一部分中,有几个需要注意的事项:
- 存在一个TermDocumentMatrix,将语料库中的术语沿着行排列,而将文档沿着列排列。
- 然后有一个DocumentTermMatrix,将文档沿着行排列,术语沿着列排列。
这个应用程序主要涉及DocumentTermMatrix。这是因为在应用朴素贝叶斯算法时,将观察数据放在行中,将特征(单词)放在列中是方便的。
## [1] 20000 28725
目前的文档-术语矩阵包含了从20000条推文中提取的28725个单词。这些单词将用于决定一条推文是否是积极或消极的。
文档-术语矩阵的稀疏性为100%,这意味着没有单词被留在矩阵之外。
## [1] 20000 1109
## <<DocumentTermMatrix (documents: 10, terms: 15)>>
## Non-/sparse entries: 20/130
## Sparsity : 87%
## Maximal term length: 7
## Weighting : term frequency (tf)
## Sample :
## Terms
## Docs anxieti come depress diagnos far ive just need sinc take
## 1 1 1 1 1 1 1 1 0 2 1
## 10 0 0 0 0 0 0 0 0 0 0
## 2 0 0 0 0 0 0 0 1 0 0
## 3 0 0 0 0 0 0 0 1 0 0
## 4 0 0 0 0 0 0 0 0 0 0
## 5 1 0 0 0 0 0 1 1 0 0
## 6 0 0 0 0 0 0 0 0 0 0
## 7 0 0 0 0 0 0 0 0 0 0
## 8 0 0 0 0 0 0 0 0 0 0
## 9 0 0 0 0 0 0 0 0 0 1
regular inspect()方法的信息量不是很大。但是,如果我们想知道一些单词或短语在语料库中出现的频率,我们可以做的一件事是将这些术语作为字典传递给DocumentTermMatrix()方法。
只是为了跟进。在上面的输出中,我们看到文件1有1次出现短语“焦虑”和1次出现“抑郁”。如果我们查看原始推文文本数据帧,我们可以看到:
## [1] "Its just over 2 years since I was diagnosed with anxiety and depression Today Im taking a moment to reflect on how far Ive come since"
能看一眼出现700多次的单词是件好事。
## word freq
## like like 1035
## depress depress 953
## just just 943
## dont dont 832
## get get 794
## one one 746

模型
朴素贝叶斯对分类数据进行训练,将数值数据转换为分类数据。我们将通过创建一个函数来转换数字特征,该函数将任何非零正值转换为“是”,将所有零值转换为“否”,以说明文档中是否存在特定术语。
此例程将DocumentTermMatrix的元素从字数更改为存在/不存在。以下是斯坦福大学的一门课程中关于NLP的一些很好的开源笔记。其中包括对二进制(布尔特征)朴素贝叶斯算法的一些讨论。
我们现在将数据集拆分为训练和测试数据集。我们将使用90%的数据进行训练,其余10%用于测试。
## user system elapsed
## 0.72 0.01 0.74
Model Evaluation for Naive Bayes
## Confusion Matrix and Statistics
##
## Reference
## Prediction no depression depression
## no depression 1006 0
## depression 0 970
##
## Accuracy : 1
## 95% CI : (0.9981, 1)
## No Information Rate : 0.5091
## P-Value [Acc > NIR] : < 2.2e-16
##
## Kappa : 1
##
## Mcnemar's Test P-Value : NA
##
## Sensitivity : 1.0000
## Specificity : 1.0000
## Pos Pred Value : 1.0000
## Neg Pred Value : 1.0000
## Prevalence : 0.5091
## Detection Rate : 0.5091
## Detection Prevalence : 0.5091
## Balanced Accuracy : 1.0000
##
## 'Positive' Class : no depression
与分别为100%和100%的支持向量机和随机森林模型相比,朴素贝叶斯模型以100%的准确率表现最好。Naive Bayes的工作原理是假设数据集的特征彼此独立 — 因此被称为Naive。
结果
该项目根据推特文本对文本进行分类,以预测他们是否患有抑郁症。贝叶斯模型在测试集中的准确性已经达到了一个非常好的水平。患者过去活泼开朗,但他们最近的推特非常沮丧,或者他们的状态发生了变化,比如睡眠问题和身体问题。这类用户可能患有抑郁症
代码
library(tidyverse)
library(ggthemes)
library(e1071) # has the naiveBayes algorithm
library(caret) # good ML package, I like the confusionMatrix() function
library(tm) # for text mining
# Load package
library(wordcloud)
Sys.setenv(LANG="en_US.UTF-8")
### https://www.kaggle.com/datasets/infamouscoder/mental-health-social-media
data <- read_csv("Mental-Health-Twitter.csv")
data$label <- factor(data$label,levels = c(0,1),
labels = c("no depression","depression"))
table(data$label)
data$post_text <- gsub("[^[:alnum:][:blank:]?&/\\-]", "", data$post_text)
corpus <- Corpus(VectorSource(data$post_text))
corpus
clean.corpus <- corpus %>% tm_map(tolower) %>%
tm_map(removeNumbers) %>%
tm_map(removeWords, stopwords()) %>%
tm_map(removePunctuation) %>%
tm_map(stripWhitespace)%>%
tm_map(stemDocument)
inspect(clean.corpus[1:5])
no_depression <- subset(data,label=="no depression")
wordcloud(no_depression$post_text, max.words = 100, scale = c(3,0.5))
depression <- subset(data,label=="depression")
wordcloud(depression$post_text, max.words = 100, scale = c(3,0.5))
df <- data%>%
group_by(user_id,label)%>%
count()
ggplot(df, aes(x = label)) +
geom_bar() +
geom_text(aes(label = ..count..), stat = "count", vjust = 2, colour = "white") + ylab("people")
# Create the Document Term Matrix
dtm <- DocumentTermMatrix(clean.corpus)
dim(dtm)
dtm = removeSparseTerms(dtm, 0.999)
dim(dtm)
#Inspecting the the first 10 tweets and the first 15 words in the dataset
inspect(dtm[0:10, 1:15])
data$post_text[1]
freq<- sort(colSums(as.matrix(dtm)), decreasing=TRUE)
wf<- data.frame(word=names(freq), freq=freq)
head(wf)
ggplot(head(wf,10),aes(x = fct_reorder(word,freq),y = freq)) + geom_col() + xlab("word") + ggtitle("Top 10 words in Tweets")
convert_count <- function(x) {
y <- ifelse(x > 0, 1,0)
y <- factor(y, levels=c(0,1), labels=c("No", "Yes"))
y
}
# Apply the convert_count function to get final training and testing DTMs
datasetNB <- apply(dtm, 2, convert_count)