错误率(error rate):分错样本占总样本的比例;
对于数据集 D D D,分类错误率定义为:
E ( f ; D ) = 1 m ∑ i = 1 m I ( f ( x i ) ≠ y i ) E(f;D)=\frac{1}{m}\sum_{i=1}^m\mathbb{I}(f(x_i)\neq y_i) E(f;D)=m1i=1∑mI(f(xi)=yi)
精度(accuracy):精度 = 1 - 错误率
精度的定义为:
a c c ( f , D ) = 1 m ∑ i = 1 m I ( f ( x i ) = y i ) = 1 − E ( f ; D ) \begin{aligned} acc(f,D)&=\frac{1}{m}\sum_{i=1}^m\mathbb{I}(f(x_i)= y_i)\\ &=1-E(f;D) \end{aligned} acc(f,D)=m1i=1∑mI(f(xi)=yi)=1−E(f;D)
对于二分类问题,可将样例根据其真实类别与学习预测类别的组合划分为真正例(true positive)、假正例(false positive)、真反例(true negative)、假反例(false negative),简写为 TP、FP、TN、FN,有 TP+FP+TN+FN = 样例总数.
可以用一个“混淆矩阵”来表示
| 真实情况\ 预测结果 | 正例 | 负例 |
|---|---|---|
| 正例 | TP(真正例) | FN(假反例) |
| 负例 | FP(假正例) | TN(真反例) |
查准率 P P P (precision) 与查全率 R R R (recall) 分别定义为:
P = T P T P + F P P = \frac{TP}{TP+FP} P=TP+FPTP
R = T P T P + F N R = \frac{TP}{TP+FN} R=TP+FNTP
一般来说,查准率高时,查全率往往偏低;而查全率高时,查准率偏低.
例子说明:若希望将好瓜尽可能多的选出来,则可以通过增加选瓜的数量来实现,如果将所有的西瓜都选上,那么所有的好瓜也必然都被选上了,但这样查准率就会较低;若希望选出的好瓜比例尽可能高,则可只挑选最有把握的瓜,但这样也会漏掉不少好瓜,使得查全率较低.通常只有在一些简单的任务中,才可能使查全率和查准率都很高.
为了表达分类器对查准率和查全率的不同偏好,用 F β F_\beta Fβ 表示,定义为:
F β = ( 1 + β 2 ) ∗ P ∗ R ( β 2 ∗ P ) + R F_\beta = \frac{(1+\beta^2)*P*R}{(\beta^2*P)+R} Fβ=(β2∗P)+R(1+β2)∗P∗R
当 β > 1 \beta>1 β>1 时查全率有更大的影响; β < 1 \beta<1 β<1 时查准率有更大的影响
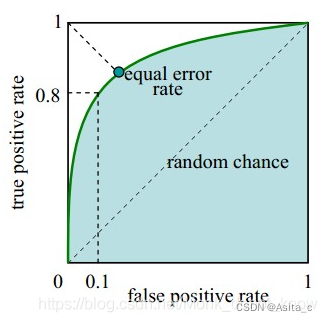
根据学习器的预测结果对样例进行排序,按此顺序逐个把样本作为正例进行预测,每次计算出两个重要量的值,分别以它们为横、纵坐标作图,就得到了”ROC曲线“.其纵轴是”真正例率(TPR)“,横轴是”假正率(FPR)“
T P R = T P T P + F N TPR = \frac{TP}{TP+FN} TPR=TP+FNTP
F P R = F P T N + F P FPR = \frac{FP}{TN+FP} FPR=TN+FPFP
ROC曲线与横轴围成的面积称为AUC,即AUC越大分类器性能越高
特异度(Specificity)-TNR
S p e c i f i c i t y = T N T N + F P Specificity = \frac{TN}{TN+FP} Specificity=TN+FPTN
假警报率 - FDR
F D R = F P F P + T N FDR = \frac{FP}{FP+TN} FDR=FP+TNFP
G-mean
G − m e a n = R e c a l l ∗ S p e c i f i c i t y G-mean = \sqrt{Recall*Specificity} G−mean=Recall∗Specificity
当数据不平衡的时候,这个值很有参考价值