Apache Storm分布式集群主要节点由控制节点(Nimbus节点)和工作节点(Supervisor节点),在集群下,怎么保证拓扑的可靠性,storm提供哪些容错机制?
我们部署了两台(Master、Salve2),然后启动了两个Supervisor和对应两个worker


一、Nimbus节点出现故障(进程挂掉)
Nimbus节点出现故障,Supervisor节点还正常运行对应的worker也是正常工运行,只是Supervisor不能接受Nimbus新任务的分配。
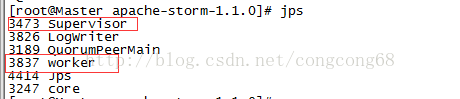
Master服务器中的Nimbus进程挂掉了,对Supervisor、worker进程不影响。

二、Supervisor节点出现故障(进程挂掉)
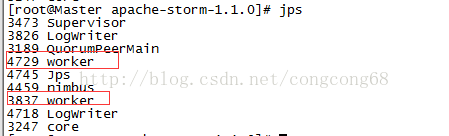
出故障的Supervisor节点对应的worker也就挂掉了,但Nimbus节点监控把对应的worker的重新分配到其他的Supervisor节点上运行。
我们把对应的Salve2中的supervisor进程挂掉

Nimbus节点监控把对应的worker的重新分配到Master的Supervisor节点上运行。

三、Nimbus和Supervisor节点都出现故障
Nimbus节点出现故障并某其中一个Supervisor出现故障时,Supervisor对应的worker不存在了,因为没有Nimbus节点监控把对应的worker的重新分配到其他的Supervisor节点上运行。
四、Worker 进程挂掉
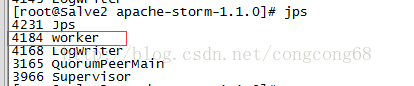
因拓扑内存溢出或者其它导致Worker 挂掉,Supervisor会重新启动Worker。
我们对Salve2的Worker进程挂掉,

然后等了一会,Supervisor会重新启动Worker
总结:
Nimbus和Supervisor被设计成是快速失败且无状态的,他们的状态都保存在ZooKeeper,如果其中某一个或者两个进程都挂掉,都不会影响其它的Supervisor已经在运行worker进程,但Nimbus和Supervisor本身不会自动重启。