Strom集群中各角色说明
概述
每一个工作节点上运行的Supervisor监听分配给它那台机器的工作,根据需要启动/关闭工作进程,每一个工作进程执行一个Topology的一个子集;一个运行的Topology由运行在很多机器上的很多工作进程Worker组成。那么Storm的核心就是主节点(Nimbus)、工作节点(Supervisor)、协调器(ZooKeeper)、工作进程(Worker)、任务线程(Task)。
主节点Nimbus
主节点通常运行一个后台程序——Nimbus。
Nimbus守护进程的主要职责是管理,协调和监控在集群上运行的topology。包括topology的发布,任务指派,事件处理失败时重新指派任务。
将topology发布到Storm集群,将预先打包成jar文件的topology和配置信息提交(submitting)到nimbus服务器上。一旦nimbus接收到了topology的压缩包,会将jar包分发到足够数量的supervisor节点上。当supervisor节点接收到了topology压缩文件,nimbus就会指派task(bolt和spout实例)到每个supervisor并且发送信号指示supervisoer生成足够的worker来执行指派的task。
nimbus记录所有supervisor节点的状态和分配给它们的task。如果nimbus发现某个supervisor没有上报心跳或者已经不可达了,它会将故障supervisor分配的task重新分配到集群中的其他supervisor节点。
nimbus不会引起单点故障。这个特性是因为nimubs并不参与topology的数据处理过程,它仅仅是管理topology的初始化,任务分发和进行监控。实际上,如果nimbus守护进程在topology运行时停止了,只要分配的supervisor和worker健康运行,topology一直继续数据处理。此时你只需要重启nimbus进程即可,无任何影响。
但要注意的是:在nimbus已经停止的情况下supervisor异常终止,因为没有nimbus守护进程来重新指派失败这个终止的supervisor的任务,数据处理就会失败。不过这种概率是很小的,因为nimbus进程一般不会宕掉。
目前storm官方出于nimbus宕机对集群影响不大的考虑,并没有实现nimbus的高可用方案。
如果你想宕掉nimbus进程,使用kill -9即可。
工作节点Supervisor
工作节点同样会运行一个后台程序——Supervisor,用于收听工作指派并基于要求运行工作进程。而Nimbus和Supervisor之间的协调则通过ZooKeeper系统。
同样,你可以用kill-9来杀死Supervisor进程,然后重启就可以继续工作。
协调服务组件ZooKeeper
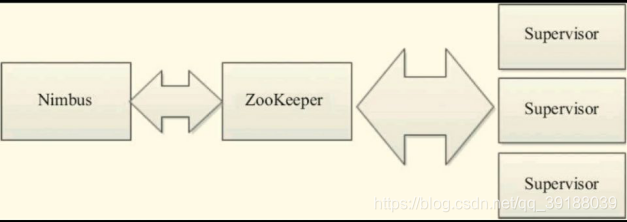
ZooKeeper是完成Nimbus和Supervisor之间协调的服务。Storm使用ZooKeeper协调集群,由于ZooKeeper并不用于消息传递,所以Storm给ZooKeeper带来的压力相当低。在大多数情况下,单个节点的ZooKeeper集群足够胜任,不过为了确保故障恢复或者部署大规模Storm集群,可能需要更大规模的ZooKeeper集群。Nimbus、Supervisor与ZooKeeper的关系如图所示。

Worker
具体处理事务进程Worker:运行具体处理组件逻辑的进程。
Task
具体处理线程Task:Worker中的每一个Spout/Bolt线程称为一个Task。同一个Spout/Bolt的Task可能会共享一个物理线程,该线程称为Executor。
Storm任务分配调度流程及调优
Storm的任务分配流程及算法如下:
1、先由nimbus来计算拓扑的工作量,及计算多少个task,task的数目是指spout和bolt的并发度的分别的和,例如一个拓扑中有一个spout和一个bolt,并且spout的task并发度为2,bolt的task并发度为3,则task数为5;
2、nimbus会把计算好的工作分配给supervisor去做,工作分配的单位是task,即把计算好的一堆task分配给supervisor去做,即将task-id映射到supervisor-id+port上去,具体流程如下:
①从zk上获得已有的assignment
②查找所有可用的slot,所谓slot就是可用的worker,在所有supervisor上配置的多个worker的端口。
③将任务均匀地分配给可用的worker
3、Supervisor会根据nimbus分配给他的任务信息来让自己的worker做具体的工作
4、Worker会到zookeeper上去查找给他分配了哪些task,并且根据这些task-id来找到相应的spout/bolt,它还需要计算出这些spout/bolt会给哪些task发送消息,然后建立与这些task的连接,然后在需要发消息的时候就可以给相应的task发消息。
Nimbus的任务分配算法特点如下:
1、在slot(槽位)充沛的情况下,能够保证所有topology的task被均匀的分配到整个集群的所有机器上
2、在slot不足的情况下,它会把topology的所有的task分配到仅有的slot上去,这时候其实不是理想状态,所以在nimbus发现有多余slot的时候,它会重新分配topology的task分配到空余的slot上去以达到理想状态。
3、 在没有slot的时候,它什么也不做
Storm与任务分配相关的配置选项
Storm自身的分配机制会尽量保证一个Topology会被平均分配到当前集群上,但是它没有考虑整个集群的负载均衡;例如现在集群有三台机器(三台Supervisor),每个上面的可用Slot数目均为四个,那么现在提交Topology,并且Topology占用1个worker,提交多个Topology后,它会先将整个集群中的一个机器占满,然后再去给别的机器分配。这种分配方式对有些场景是不太适用的,因此Storm自身的分配机制增加了额外的一个配置;
配置项如下:
default.schedule.mode: “average”
如果default.schedule.mode配置为average,则在使用默认的分配机制时会优先将任务分配给空闲Slot数目最多的机器。
Storm常见参数配置
示例:
#Storm集群对应的ZooKeeper集群的主机列表
storm.zookeeper.servers:
- "ip01"
- "ip02"
- "ip03"
#Storm集群对应的ZooKeeper集群的服务端口,ZooKeeper默认端口为2181
storm.zookeeper.port: 2181
#Storm的元数据在ZooKeeper中存储的根目录
storm.zookeeper.root: /storm
#整个Storm集群的Nimbus节点
nimbus.host: ip01
#Storm的Slot(槽位)。Slot和Worker是一一对应的。即有一个slot就可以启动一个worker进程。因为进程和进程之间需要通信,比如传输数据,所以需要配置端口号。
配置几个端口,每台服务器就会启动几个slot。(注意端口不要冲突)
配置建议1:因为Storm是基于内存的实时计算,所以在配置Slot个数时,最好是服务器core的整数倍。比如一台服务器8核,slot的个数:8、16、24……
配置建议2:slot个数不要超过: (物理内存 - 虚拟内存)/每个java进程最大的内存使用量
比如:物理内存:64 虚拟内存:4 每个java进程:1
一般配置32个 。
supervisor.slots.ports:
- 6700
- 6701
- 6702
- 6703
- 6704
- 6705
- 6706
- 6707
- 6708
- 6709
- 6710
#Storm集群的UI地址端口号,默认是8080
ui.port :8080
Storm的容错机制
任务级容错
Bolt任务crash引起的消息未被应答。此时,acker中所有与此Bolt任务关联的消息都会因为超时而失败,对应的Spout的fail方法将被调用。
acker任务失败。如果acker任务本身失败了,它在失败之前持有的所有消息都将超时而失败。Spout的fail方法将被调用。
Spout任务失败。在这种情况下,与Spout任务对接的外部设备(如MQ)负责消息的完整性。例如,当客户端异常时,kestrel队列会将处于pending状态的所有消息重新放回队列中。
任务槽(slot)故障
Worker失败。每个Worker中包含数个Bolt(或Spout)任务。Supervisor负责监控这些任务,当worker失败后会尝试在本机重启它,如果它在启动时连续失败了一定的次数,无法发送心跳信息到Nimbus,Nimbus将在另一台主机上重新分配worker。
Supervisor失败。Supervisor是无状态(所有的状态都保存在Zookeeper或者磁盘上)和快速失败(每当遇到任何意外的情况,进程自动毁灭)的,因此Supervisor的失败不会影响当前正在运行的任务,只要及时将他们重新启动即可。
Nimbus失败。Nimbus也是无状态和快速失败的,因此Nimbus的失败不会影响当前正在运行的任务,但是当Nimbus失败时,无法提交新的任务,只要及时将它重新启动即可。
Storm的Nimbus目前不具备HA。因为官方给出的解释:Nimbus是无状态和快速失败,不会对已经运行的task有影响。
1.如果想让Nimbus具有HA机制,建议学习阿里的JStorm(性能也要比原生的Strom要高)
2.可以查看Storm最新的1.0版本
集群节点(机器)
Storm集群中的节点故障。此时Nimbus会将此机器上所有正在运行的任务转移到其他可用的机器上运行。
Zookeeper集群中的节点故障。Zookeeper保证少于半数的机器宕机系统仍可正常运行,及时修复故障机器即可。
Storm—anchor(锚定)与ack机制
概述
Storm提供了一种API能够保证spout发送出来的每个tuple都能够执行完整的处理过程。在我们之前做的例子中,并没有实现这种消息的可靠性保证。
spout的可靠性
在Storm中,可靠的消息处理机制是从spout开始的。一个提供了可靠的处理机制的spout需要记录它发射出去的tuple,当下游bolt处理tuple或者子tuple失败时spout能够重新发射。子tuple可以理解为bolt处理spout发射的原始tuple后,作为结果发射出去的tuple。另外一个视角来看,可以将spout发射的数据流看作一个tuple树的主干。
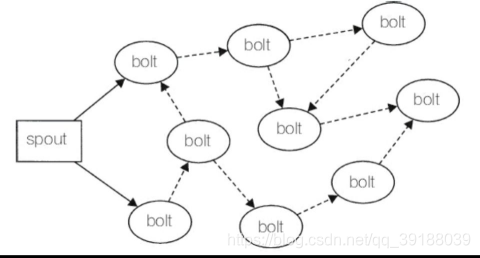
在图中,实线部分表示从spout发射的原始主干tuple,虚线部分表示的子tuple都是源自于原始tuple。这样产生的图形叫做tuple树。
在有保障数据的处理过程中,bolt每收到一个tuple,都需要向上游确认应答(ack)者报错。对主干tuple中的一个tuple,如果tuple树上的每个bolt进行了确认应答,spout会调用ack方法来标明这条消息已经完全处理了。如果树中任何一个bolt处理tuple报错,或者处理超时,spout会调用fail方法。
Spout的nextTuple()发送一个tuple。为实现可靠的消息处理,首先要给每个发出的tuple带上唯一的ID,并且将ID作为参数传递给SpoutOutputCollector的emit()方法
bolt的可靠性
bolt要实现可靠的消息处理机制包含两个步骤:
1.当发射衍生的tuple时,需要锚定读入的tuple
2.当处理消息成功或者失败时分别确认应答或者报错
锚定一个tuple的意思是,建立读入tuple和衍生出的tuple之间的对应关系,这样下游的bolt就可以通过应答确认、报错或超时来加入到tuple树结构中。
注:非锚定的tuple不会对数据流的可靠性起作用。如果一个非锚定的tuple在下游处理失败,原始的根tuple不会重新发送。
案例——可靠的单词计数
为了进一步说明可控性,让我们增强SentenceSpout类,支持可靠的tuple发射方式。需要记录所有发送的tuple,并且分配一个唯一的ID。我们使用HashMap<UUID,Values>来存储已发送待确认的tuple。每当发送一个新的tuple,分配一个唯一的标识符并且存储在我们的hashmap中。当收到一个确认消息,从待确认列表中删除该tuple。如果收到报错,从新发送tuple:
Spout代码示例:
public class WordCountSpout extends BaseRichSpout{
private ConcurrentHashMap<UUID,Values> pending;
private String[] data=new String[]{
"hello storm",
"hello world",
"hello hadoop",
"hello world"
};
private SpoutOutputCollector collector;
private static int i=0;
@Override
public void nextTuple() {
Values line=new Values(data[i]);
//为当前的tuple生成一个标识id
UUID msgId=UUID.randomUUID();
this.pending.put(msgId,line);
collector.emit(line,msgId);
if(i==data.length-1){
i=0;
}else{
i++;
}
}
@Override
public void open(Map conf, TopologyContext context, SpoutOutputCollector collector) {
this.collector=collector;
this.pending=new ConcurrentHashMap<>();
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("line"));
}
@Override
public void ack(Object msgId) {
this.pending.remove(msgId);
}
@Override
public void fail(Object msgId) {
collector.emit(this.pending.get(msgId),msgId);
}
}
为支持有保障的处理,需要修改bolt,将输出的tuple和输入的tuple锚定,并且应答确认输入的tuple:
Bolt代码示例:
public class SplitBolt extends BaseRichBolt{
private OutputCollector collector;
@Override
public void execute(Tuple tuple) {
try {
String line=tuple.getStringByField("line");
String[] words=line.split(" ");
for(String word:words){
//将输入tuple和输出tuple进行锚定
collector.emit(tuple,new Values(word));
}
//ack方法的作用是向上游发送确认机制,表明此tuple以接收并成功处理
collector.ack(tuple);
} catch (Exception e) {
//fail方法的作用是向上游发送失败确认,上游收到后,会重新发送tuple
collector.fail(tuple);
}
}
@Override
public void prepare(Map arg0, TopologyContext arg1, OutputCollector arg2) {
collector=arg2;
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word"));
}
}
补充:如果是用anchor和ack机制,对于Bolt组件,可以实现:BaseBasicBolt
可以不用省略锚定 ack和fail的代码
代码示例:
public class OtherBolt extends BaseBasicBolt{
@Override
public void execute(Tuple input, BasicOutputCollector collector) {
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
// TODO Auto-generated method stub
}
}
Storm可靠性保证
概述
Storm提供了数据流处理时的可靠性,所谓的可靠性是指spout发送的每个tuple都能够执行完整的处理过程。这种消息传输的可靠性保证其实有三个级别,分别是:
1)至多处理一次,但可能会丢失数据 at most once
2)至少处理一次,数据处理不会丢失,但可能会重复处理 at least once
3)精确处理一次,一定能被处理,且仅处理一次 exactly once
第一种级别实际上是一种最弱的保证,我们做的最开始的数字案例和单词统计案例就是这个级别。
第二种级别是要比第一种可靠很多,实际上我们用的acker机制就是实现了这种级别。但可能会带来的问题是,一条数据会被重复处理多次。
比如:当一个tuple在传输出去之后,下游节点需要在指定时间内反馈ack,如果超时,则认为处理失败,上游会重新发送。所以,如果某一时刻由于网络波动造成了较大的传输延迟,就可能会造成一个Tuple被上游重复发送,最后导致重复处理。
对于这种情况,也不是没有办法解决。我们可以调节topology.message.timeout.secs(default:30)
适当调大是更为稳妥的方式。
第三种级别是最理想的,虽然利用anchor和ack机制保证所有Tuple都被成功处理,如果Tuple出错,则可以重传,但是如何保证出错的Tuple只被处理一次(不被重复处理)?之前的Storm版本提供了一套事务性组件Transactional Topology,用来解决该问题。现在版本中已经弃用Transactional Topology原语,在Storm0.8之后版本取而代之的是Trident框架,提供了更加方便和直观的接口。
Trident框架
概述
Storm是一个分布式的实时计算系统,利用ack机制保证所有Tuple都被成功处理。如果Tuple出错,则可以重传,但是如何保证出错的Tuple只被处理一次。之前的Storm版本提供了一套事务性组件Transactional Topology,用来解决该问题。现在版本中已经弃用Transactional Topology原语,取而代之的是Trident框架。
Trident是在Storm基础上的以实时计算为目标的高度抽象。它在提供处理大吞吐量数据能力(每秒百万次消息)的同时,也提供了低时延分布式查询和有状态流式处理的能力。
Trident的batch和partition
Trident将多个Tuple元组变为能批量处理的集合(batch)来处理
此外,Trident在并发度的控制上,舍弃了worker,executor,task等繁琐的概念,取而代之的是用分区(partition)来刻画并发度。
可以这样理解:我们在Trident框架时,如何提高并发度?很简单,只需要设置并提高分区数量即可,而不需要再繁琐的设置有几个worker,有几个executor,每个executor运行几个task。所以这也是Trident框架的魅力所在,因为它大大简化了对Storm集群的使用门槛。可能有人会有疑惑,分区到底是什么?实际上,Trident的分区本质上就是对worker,executor,task的进一步封装。而一个分区到底有多少worker,executor,task,程序员不需要了解,因为Trident框架自身会根据集群环境做出调整和优化,经过大量的实践表明,使用Trident分区来控制并发度要远远比程序员手动设置原生的storm并发度要好。
batch(批次)和partition(分区)是什么关系?
batch是Trident框架处理流数据的最小逻辑单元,如果你设置一个batch里只运行一个tuple,那就相当于和原生的storm没任何差别,但很少有人这么多。所以一个batch就是一组tuple的集合。
partition(分区)默认是1个,即在默认情况下,如果你用Trident处理流数据,会有很多个batch,那么这些batch都在这1个分区里运行。
如果设置了多个分区,那么情况是:
某一个分区里可能会运行多个batch
某一个batch也可能会同时运行在不同的分区上(比如一个batch里,有100个tuple,其中有20个tuple运行在分区1,另外80个tuple运行在分区2)
此外,Tident还提供如下的流数据处理功能:
1)Joins
2)Aggregations
3)Grouping
4)Function
5)Filter等能力
综上,Trident使得实时计算更加优雅,其API可以完成大吞吐量的流式计算、状态维护、低时延查询等功能。Trident让用户在获取最大性能的同时,以更自然的方式进行实时计算。
Trident框架的事务机制
Trident还提供一致性(consistent)、有且仅有一次(exactly-once)、按顺序处理等语义,这些语义就是对事务特性的支持。
1)Trident将Tuple分成小的能批量处理的集合(即批次,batch)。
2)给每一批Tuple分配一个唯一ID作为事务ID(txid)。当这一批Tuple重新发送时,txid不变。
3)批与批之间的状态更新是严格按顺序的。例如,第三批Tuple状态的更新,必须要等到第二批Tuple状态更新成功之后才可以进行。
Trident划分数据流批次的示意图如下图所示。
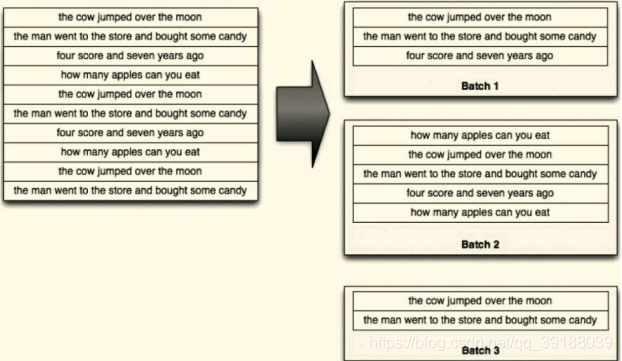
有了这些定义,状态实现可以检测到当前这批Tuple是否以前处理过,并根据不同的情况进行不同的处理。
Trident入门案例
public class TridentDriver {
public static void main(String[] args) {
Config config=new Config();
//声明spout发生元组的key值
Fields fields=new Fields("age","name");
//定义一个批次中最多处理的信息数量
int maxBatchSize=100;
@SuppressWarnings("unchecked")
FixedBatchSpout numberSpout=new FixedBatchSpout(fields, maxBatchSize,
new Values(23,"tom"),new Values(30,"li"),new Values(40,"wang"),new Values(60,"zhao"));
//设置消息源是否循环发送消息,true是循环发送,false是不循环
numberSpout.setCycle(true);
TridentTopology topology=new TridentTopology();
//通过spout获取流
Stream stream=topology.newStream("s1", numberSpout);
// TODO
//本例是以本地集群方式启动
LocalCluster cluster=new LocalCluster();
cluster.submitTopology("trident_number_topology",config,topology.build());
//运行5s后 退出
Utils.sleep(5000);
cluster.killTopology("trident_number_topology");
cluster.shutdown();
}
}
Trident-Filter
案例说明:
我们现在要实现两个Filter,一个Filter用于将 key:age和name 及对应的value值打印输出,而另一个Filter则只打印key:name及对应的value打印输出
过滤操作通过过滤器 - Filter 实现。
所有Filter都要直接或间接实现Filter接口,通常我们会去继承BaseFilter抽象类。
Filter收到一个输入tuple后可以决定是否留着这个tuple。
InfoPrintFilter代码:
案例说明:
我们现在要实现两个Filter,一个Filter用于将 key:age和name 及对应的value值打印输出,而另一个Filter则只打印key:name及对应的value打印输出
过滤操作通过过滤器 - Filter 实现。
所有Filter都要直接或间接实现Filter接口,通常我们会去继承BaseFilter抽象类。
Filter收到一个输入tuple后可以决定是否留着这个tuple。
InfoPrintFilter代码:
案例说明:
我们现在要实现两个Filter,一个Filter用于将 key:age和name 及对应的value值打印输出,而另一个Filter则只打印key:name及对应的value打印输出
过滤操作通过过滤器 - Filter 实现。
所有Filter都要直接或间接实现Filter接口,通常我们会去继承BaseFilter抽象类。
Filter收到一个输入tuple后可以决定是否留着这个tuple。
InfoPrintFilter代码:
public class TridentDriver {
public static void main(String[] args) {
Config config=new Config();
Fields fields=new Fields("age","name");
int maxBatchSize=100;
@SuppressWarnings("unchecked")
FixedBatchSpout numberSpout=new FixedBatchSpout(fields, maxBatchSize,
new Values(23,"tom"),new Values(30,"li"),new Values(40,"wang"),new Values(60,"zhao"));
numberSpout.setCycle(true);
TridentTopology topology=new TridentTopology();
Stream stream=topology.newStream("s1", numberSpout);
//设置过滤器,此过滤器未对fields字段做过滤
stream.each(fields,new InfoPrintFilter());
//设置过滤器,此过滤器只会接收 name字段的tuple
//stream.each(new Fields("name"), new NamePrintFilter());
LocalCluster cluster=new LocalCluster();
cluster.submitTopology("trident_number_topology",config,topology.build());
Utils.sleep(5000);
cluster.killTopology("trident_number_topology");
cluster.shutdown();
}
}
注:stream.each()方法的返回值还是一个Stream,所以用户可以根据业务场景将多个Stream连在一起,并结合具体的filter过滤来实现相应的功能。
对于NamePrintFilter的改造
我们现在想做这样一件事,即当 filter收到 tuple后,我们只想保留name="zhang"的元组,而其他的舍弃。这样一来,由此filter过滤生成的流,在后续传输的过程中,则只剩下
name=zhao这一个元组
NameFilter代码:
public class NameFilter extends BaseFilter{
@Override
public boolean isKeep(TridentTuple tuple) {
//只保留 name=zhang的元组到后续的流中
if(tuple.getStringByField("name").equals("zhao")){
return true;
}else{
return false;
}
}
}
TridentDriver代码:
……其他代码略
//通过设置两个过滤器形成两个流,第一个流过滤了只剩下name=zhao的元素,第二个用于打印输出
stream.each(new Fields(“name”), new NameFilter()).each(new Fields(“name”),new NamePrintFilter());
Trident-Function
概述
函数操作通过 函数 - Function 来实现。
所有Function都要直接或间接实现Function接口,通常我们会去继承BaseFunction抽象类。
一个function收到一个输入tuple后可以输出0或多个tuple。
输出tuple的字段被追加到接收到的输入tuple后面。
each(Fields,Function,Fields)
第一个参数:要从流中获取哪些Fields进入Function,注意new Fields(String …fields)中属性的声明声明的顺序决定了Function中tuple中属性的顺序
第二个参数:Function对象
第三个参数:Function执行过后额外追加的属性的Fields
案例说明
基于上一个案例,我们已经实现了将name=zhang的tuple元组过滤出来,现在我们想通过function,来实现为元组加入 key:gender value:male 这样的功能
GenderFunction代码:
public class GenderFunction extends BaseFunction{
@Override
public void execute(TridentTuple tuple, TridentCollector collector) {
collector.emit(new Values("male"));
}
}
TridentDriver代码:
……其他代码略
stream.each(new Fields("name"), new NameFilter()).
each(new Fields("name"),new GenderFunction(),new Fields("gender")).
each(new Fields("name","gender"),new NamePrintFilter());
Trident-partitionAggregate
分区聚合操作
分区聚合操作由聚合器 - CombinerAggregator, ReducerAggregator, Aggregator 来实现。
分区聚合操作(partitionAggregate)对每个Partition中的tuple(以batch为单位)进行聚合.
与前面的Function在原tuple后面追加数据不同,分区聚合操作的输出会直接替换掉输入的tuple,仅输出分区聚合操作中发射的tuple。
~方法:
partitionAggregate(Fields,Aggreator/CombinerAggregator/ReducerAggregator,Fields)
第一个参数:要进入聚合器的字段们
第二个参数:聚合器对象
第三个参数:聚合后输出的字段们
CombinerAggregator
public interface CombinerAggregator extends Serializable {
T init(TridentTuple tuple);
T combine(T val1, T val2);
T zero();
}
1)CombinerAggregator接口只返回一个tuple,并且这个tuple也只包含一个field。
2)开始前首先调用zero()方法产生一个初始值val1。
3)调用init方法对当前tuple进行处理,产生当前tuple对应的val2
4)再调用combine函数将之前的val1和当前tuple对应的val2进行合并处理,
返回合并后的值成为新的val1
循环如上步骤处理分区中内的所有tuple,并将最终产生的val1作为整个分区合并的结果返回。
案例说明
我们现在想将所有人的age年龄做叠加
AgeCombinerAggregator代码:
public class AgeCombinerAggerator implements CombinerAggregator<Integer>{
//此方法返回值是val2
@Override
public Integer init(TridentTuple tuple) {
int age=tuple.getIntegerByField("age");
return age;
}
//此方法用于接收val1和val2,用户根据业务场景自行处理
@Override
public Integer combine(Integer val1, Integer val2) {
int result=val1+val2;
System.out.println("本次年龄计算的结果:"+result);
//每次返回的result结果作为下次接收的val1值
return result;
}
//此方法返回值是初始值val1
@Override
public Integer zero() {
return 0;
}
}
TridentDriver代码:
……其他代码省略
//设置combiner分区聚合,用于计算所有人的年两之和
stream.partitionAggregate(new Fields(“age”),new AgeCombinerAggerator(),new Fields(“result”));
注:上面返回的stream流中,返回的tuple的fields字段是result,value是153(合并之后的结果)
ReducerAggregator
public interface ReducerAggregator <T> extends Serializable {
T init();
T reduce(T curr, TridentTuple tuple);
}
educerAggregator接口只返回一个tuple,并且这个tuple也只包含一个field。
执行过程:
1)开始时先调用init方法产生初始值curr。
2)调用reduce方法,方法中传入当前curr和当前tuple进行处理,产生新的curr返回
3)如果流结束,则最终产生的curr作为tuple的值返回。
AgeReducerAggregator 代码:
public class AgeReducerAggregator implements ReducerAggregator<Integer>{
//产生一个初始值 curr
@Override
public Integer init() {
return 0;
}
@Override
public Integer reduce(Integer curr, TridentTuple tuple) {
int age=tuple.getIntegerByField("age");
int result=age+curr;
System.out.println("当前的年龄加和为:"+result);
return result;
}
}
public class AgeReducerAggregator implements ReducerAggregator{
//产生一个初始值 curr
@Override
public Integer init() {
return 0;
}
@Override
public Integer reduce(Integer curr, TridentTuple tuple) {
int age=tuple.getIntegerByField(“age”);
int result=age+curr;
System.out.println(“当前的年龄加和为:”+result);
return result;
}
}
Aggregator
通常我们不会直接实现此接口,更多的时候继承BaseAggregator抽象类:
public interface Aggregator extends BaseAggregator {
T init(Object batchId, TridentCollector collector);
void aggregate(T val, TridentTuple tuple, TridentCollector collector);
void complete(T val, TridentCollector collector);
}
Aggregator是 最通用的聚合器。
Aggregator接口可以发射含任意数量属性的任意数据量的tuples,并且可以在执行过程中的任何时候发射:
1)init:在处理数据之前被调用,它的返回值会作为一个状态值传递给aggregate和complete方法。
2)aggregate:用来处理每一个输入的tuple,它可以更新状态值也可以发射tuple
3)complete:当所有tuple都被处理完成后被调用
AgeAggregator代码:
public class AgeAggregator extends BaseAggregator<Integer>{
private static int result=0;
//初始化方法,返回值是val,此值会传到aggregate方法和complete方法中
@Override
public Integer init(Object batchId, TridentCollector collector) {
return 0;
}
@Override
public void aggregate(Integer val, TridentTuple tuple, TridentCollector collector) {
int age=tuple.getIntegerByField("age");
result=result+age;
System.out.println(result);
//在每次处理过程中,也可以通过collector发射元组
}
//当流停止后,会进入此方法。但一般情况下,storm实时流计算是不会终止的
@Override
public void complete(Integer val, TridentCollector collector) {
}
}
public class AgeAggregator extends BaseAggregator<Integer>{
private static int result=0;
//初始化方法,返回值是val,此值会传到aggregate方法和complete方法中
@Override
public Integer init(Object batchId, TridentCollector collector) {
return 0;
}
@Override
public void aggregate(Integer val, TridentTuple tuple, TridentCollector collector) {
int age=tuple.getIntegerByField("age");
result=result+age;
System.out.println(result);
//在每次处理过程中,也可以通过collector发射元组
}
//当流停止后,会进入此方法。但一般情况下,storm实时流计算是不会终止的
@Override
public void complete(Integer val, TridentCollector collector) {
}
}
Trident-Repartition
重分区操作 - Repartitioning operations
Repartition操作可以改变tuple在各个task之上的划分。
Repartition也可以改变Partition的数量。
Repartition需要网络传输。
重分区时的并发度设置
parallelismHint:设置重分区时的并发度,此方法将会将会向前寻找最近的一次重分区操作,设置这两个方法之间的所有操作的并发度为指定值,如果不设置所有重分区操作的并发度默认为1。
重分区操作包括如下方式:
1)shuffle:随机将tuple均匀地分发到目标partition里。
等价于原生Storm的ShuffleGrouping
2)broadcast:每个tuple被复制到所有的目标partition里
等价于原生Storm的AllGrouping
3)partitionBy:对每个tuple选择partition的方法是:(该tuple指定字段的hash值) mod (目标partition的个数),该方法确保指定字段相同的tuple能够被发送到同一个partition。
等价于原生Storm的FieldsGrouping
4)global:所有的tuple都被发送到同一个partition。
等价于原生Storm的GlobalGrouping
5)batchGlobal:确保同一个batch中的tuple被发送到相同的partition中。
6)patition:该方法接受一个自定义分区的function(实现backtype.storm.grouping.CustomStreamGrouping)
注:重分区方法如果不通过parallelismHint方法设置并发度则默认后续方法的并发度为1.
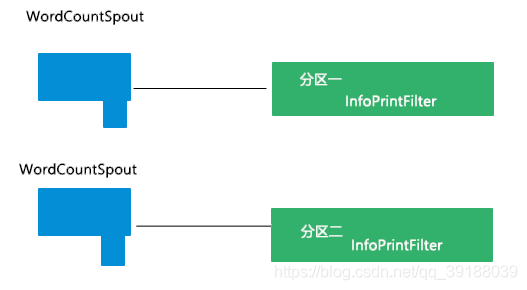
案例1
实现如下图所示的并发效果:
WordCountSpout代码:
public class WordCountSpout extends BaseRichSpout{
private Values[] values=new Values[]{
new Values("hello world"),
new Values("hello hadoop"),
new Values("hello storm"),
new Values("hello world"),
new Values("hello hadoop"),
new Values("hello world")
};
private int i=0;
private SpoutOutputCollector collector;
@Override
public void open(Map conf, TopologyContext context, SpoutOutputCollector collector) {
this.collector=collector;
}
@Override
public void nextTuple() {
if(i==values.length){
}else{
collector.emit(values[i]);
i++;
}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("line"));
}
}
InfoPrintFilter代码:
public class InfoPrintFilter extends BaseFilter{
private TridentOperationContext context;
@Override
public void prepare(Map conf, TridentOperationContext context) {
this.context=context;
}
@Override
public boolean isKeep(TridentTuple tuple) {
Fields fields=tuple.getFields();
Iterator<String> it=fields.iterator();
while(it.hasNext()){
String key=it.next();
Object value=tuple.getValueByField(key);
System.out.println("分区编号:"+context.getPartitionIndex()+"key:"+key+"="+value);
}
return true;
}
}
TridentDriver代码:
public class TridentDriver {
@SuppressWarnings("unchecked")
public static void main(String[] args) {
Config config=new Config();
Fields fields=new Fields("line");
int maxBatchSize=100;
WordCountSpout wordSpout=new WordCountSpout();
TridentTopology wordCountTopology=new TridentTopology();
Stream stream=wordCountTopology.newStream("wordcount",wordSpout);
stream.each(fields, new InfoPrintFilter());
//设置重分区时的并发度,此方法将会将会向前寻找最近的一次重分区操作,设置这两个方法之间的所有操作的并发度为指定值,在本例中,向前寻找没有发现 shuffle,group,broadcast等重分区操作,所以会将最初的设定分区操作视为分区操作,
这就意味着把原来的spout数据源由一个变为两个
stream.parallelismHint(2);
stream.each(fields, new InfoPrintFilter());
LocalCluster cluster=new LocalCluster();
cluster.submitTopology("word_count_topology",config,wordCountTopology.build());
Utils.sleep(5000);
cluster.killTopology("word_count_topology");
cluster.shutdown();
}
}
案例二:
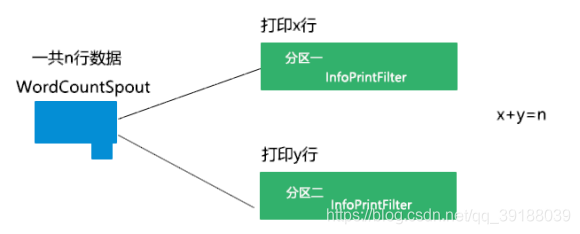
public class TridentDriver {
@SuppressWarnings("unchecked")
public static void main(String[] args) {
Config config=new Config();
TridentTopology wordCountTopology=new TridentTopology();
wordCountTopology.newStream("wordcount",new WordCountSpout()).shuffle()
.each(new Fields("line"), new InfoPrintFilter())
.parallelismHint(2);
LocalCluster cluster=new LocalCluster();
cluster.submitTopology("word_count_topology",config,wordCountTopology.build());
//运行5s后 退出
Utils.sleep(5000);
cluster.killTopology("word_count_topology");
cluster.shutdown();
}
}
案例3
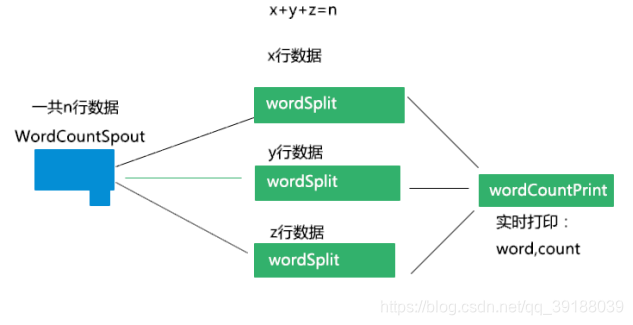
WordCountSpout代码:
public class WordCountSpout extends BaseRichSpout{
private Values[] values=new Values[]{
new Values("hello world"),
new Values("hello hadoop"),
new Values("hello storm"),
new Values("hello world"),
new Values("hello hadoop"),
new Values("hello world"),
};
private int i=0;
private SpoutOutputCollector collector;
@Override
public void open(Map conf, TopologyContext context, SpoutOutputCollector collector) {
this.collector=collector;
}
@Override
public void nextTuple() {
if(i==values.length){
}else{
collector.emit(values[i]);
i++;
}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("line"));
}
}
WordSplitAggregator代码:
public class WordSplitAggregator extends BaseAggregator<String>{
private TridentOperationContext context;
@Override
public void prepare(Map conf, TridentOperationContext context) {
this.context=context;
}
@Override
public String init(Object batchId, TridentCollector collector) {
return null;
}
@Override
public void aggregate(String val, TridentTuple tuple, TridentCollector collector) {
String line=tuple.getStringByField("line");
String[] words=line.split(" ");
System.out.println("wordsplit--分区编号:"+context.getPartitionIndex()+"所处理的行数据为:"+line);
for(String word:words){
collector.emit(new Values(word));
}
}
@Override
public void complete(String val, TridentCollector collector) {
// TODO Auto-generated method stub
}
}
WordCountPrintFilter代码:
public class WordCountPrintFilter extends BaseFilter{
private TridentOperationContext context;
private static Map<String,Integer> map=new HashMap<>();
@Override
public void prepare(Map conf, TridentOperationContext context) {
this.context=context;
}
@Override
public boolean isKeep(TridentTuple tuple) {
String word=tuple.getStringByField("word");
if(map.containsKey(word)){
map.put(word,map.get(word)+1);
}else{
map.put(word, 1);
}
System.out.println("wordcount--分区编号:"+context.getPartitionIndex()+"|"+word+":"+map.get(word));
return false;
}
}
TridentDriver代码:
public class TridentDriver {
@SuppressWarnings("unchecked")
public static void main(String[] args) {
Config config=new Config();
TridentTopology wordCountTopology=new TridentTopology();
wordCountTopology.newStream("wordcount",new WordCountSpout())
.shuffle().partitionAggregate(new Fields("line"),new WordSplitAggregator(),new Fields("word"))
.parallelismHint(3).global().each(new Fields("word"), new WordCountPrintFilter()).parallelismHint(1);
LocalCluster cluster=new LocalCluster();
cluster.submitTopology("word_count_topology",config,wordCountTopology.build());
Utils.sleep(5000);
cluster.killTopology("word_count_topology");
cluster.shutdown();
}
}
单词的实时统计案例
TridentDriver代码:
public class TridentDriver {
@SuppressWarnings("unchecked")
public static void main(String[] args) {
Config config=new Config();
Fields fields=new Fields("line");
int maxBatchSize=100;
FixedBatchSpout wordSpout=new FixedBatchSpout(fields, maxBatchSize,
new Values("hello world"),
new Values("hello hadoop"),
new Values("hello storm"),
new Values("hello world"),
new Values("hello hadoop"),
new Values("hello world"));
wordSpout.setCycle(false);
TridentTopology wordCountTopology=new TridentTopology();
Stream stream=wordCountTopology.newStream("wordcount",wordSpout);
//考虑使用分区聚合器,输入是line->输出是word->输入是word->输出是word,wordcount
stream.partitionAggregate(fields,new WordCountAggregator(),new Fields("word","count")).each(new Fields("word","count"), new WordCountPrintFilter());
LocalCluster cluster=new LocalCluster();
cluster.submitTopology("word_count_topology",config,wordCountTopology.build());
//运行5s后 退出
Utils.sleep(5000);
cluster.killTopology("word_count_topology");
cluster.shutdown();
}
}
WordCountAggregator代码:
public class WordCountAggregator extends BaseAggregator<String>{
private static Map<String, Integer> map=new HashMap<>();
@Override
public String init(Object batchId, TridentCollector collector) {
return null;
}
@Override
public void aggregate(String val, TridentTuple tuple, TridentCollector collector) {
String line=tuple.getStringByField("line");
String[] words=line.split(" ");
for(String word:words){
if(map.containsKey(word)){
map.put(word, map.get(word)+1);
}else{
map.put(word,1);
}
}
for(Entry<String,Integer> entry:map.entrySet()){
collector.emit(new Values(entry.getKey(),entry.getValue()));
}
0
}
@Override
public void complete(String val, TridentCollector collector) {
}
}
WordCountPrintFilter代码:
public class WordCountPrintFilter extends BaseFilter{
@Override
public boolean isKeep(TridentTuple tuple) {
String word=tuple.getStringByField("word");
int count=tuple.getIntegerByField("count");
System.out.println(word+":"+count);
return false;
}
}
Storm的应用场景
概述
要从海量数据中提取加工对业务有用的信息,选取合适的技术将事半功倍,省去了重新造轮子的烦恼。对海量数据进行批处理运算,Hadoop依旧保持着无法撼动的地位。但在对实时性要求较高的应用场景中,Hadoop就显得力不从心。它需要将数据先落地存储到HDFS上,然后再通过MapReduce进行计算。这样的批处理运算流程使它很难将延时缩小到秒级。
Storm的处理速度最快可以达到毫秒级别。Storm的QPS (Query Per Second)达到9万~10万。
JStorm QPS(12万~11万)。
此外,对于实时处理的技术,还可以用Spark Streaming。
Storm的另外一个优势在于:Storm可以一个一个tuple处理,(细粒度处理),所以像金融领域的实时流处理,优先选择Storm。
Storm是基于数据流的实时处理系统,提供了大吞吐量的实时计算能力(因为Storm是一个分布式架构)。每条数据到达系统时,立即在内存中进入处理流程,并在很短的时间内处理完成。实时性要求较高的数据分析场景,都可以尝试使用Storm作为技术解决方案。
应用场景
1.语音实时墙
以移动互联网行业中的智能手机移动APP为对象,实时统计用户的访问频率和访问地址,并将统计实时反映在前端页面的地图中,投影到大显示屏上。
移动互联是非常热门的行业,而且这个行业也诞生了不少优秀的应用,用户量也非常巨大,微信就是其中的一款应用。在用户量巨大的前提下,移动APP的安装、浏览和点击的日志数量会成几何级数暴增,基于这些日志数据的统计分析,特别是实时计算方面,实现的难度比较高,借助实时计算框架进行开发的门槛则会降低很多。Storm恰恰是众多实时计算框架中的首选。
语音“实时墙”项目的需求是将用户登录的地点实时显示在地图上,数据量为每天一亿,每秒峰值20000,要求系统具备高可靠性,某些单点出现问题不能对服务造成影响,数据落地到数据展示的时延在30s内。Hadoop处理MapReduce任务会花费分钟级别,这显然不能满足业务对数据实时性秒级别的需求,Storm这个实时的、分布式以及具备高可靠性的计算系统,能较好地弥补Hadoop执行MapReduce任务分钟级别的不足,全内存计算使得寻址速度是Hadoop硬盘寻址速度的百万倍以上,因此Storm解决高并发瓶颈,能让数据的输入输出处理更加安全、快速,稳定地处理并发及安全性也将保证复杂繁琐的数据收集准确而高效。
2.网络流量流向实时分析
通过Storm实时分析网络流量流向,并将实时统计反映在前端页面的图表中以备查询。网络流量流向是IP网络运营管理的重要基础数据,通过采集和分析流量数据,运营商可以了解整个网络的运行态势、网络负载状况、网络安全状况、流量发展趋势、用户的行为模式、业务与站点的接受程度,还可以为制定灵活的资费策略和计费方式提供依据。
3.交通—基于GPS的实时路况分析
基于GPS数据,通过Storm可以做实时路况分析系统。实时路况能实时反映区域内交通路况,指引最佳、最快捷的行驶路线,提高道路和车辆的使用效率。
目前,提供路况服务的公司主要有三家:世纪高通、北大千方(收购掌城)、九州联宇。它们为百度地图和Google地图这些路况数据的应用服务商提供数据。
JStorm介绍
git主页:https://github.com/alibaba/jstorm
阿里拥有自己的实时计算引擎
原生Storm的缺点
1)现有storm调度太简单,无法定制
2)Storm 任务分配不平衡
3)RPC OOM一直没有解决
4)监控太简单
5)对ZK 访问频繁,会对ZK造成过大的负载,因为还要考虑其他框架也在使用Zookeeper
比如Hadoop,HBase,Storm,Dubbo,Kafka
JStorm的特点
1)Nimbus 实现HA:当一台nimbus挂了,自动热切到备份nimbus
2)减少对ZK的访问量:去掉大量无用的watch
3)可以自定义任务分配,比如哪个端口,用多少个cpu slot,多少内存。
JStorm相比Storm性能更好
JStorm 0.9.0 性能非常的好,单worker 发送最大速度为11万QPS(query per second)~12万QPS。
比Storm 0.9.0快10%~30%。
性能提升的原因:
1)Zeromq 减少一次内存拷贝
2)增加反序列化线程
3)优化ack代码
4)Task 内部异步化。Worker 内部全流水线模式,Spout nextTuple和ack/fail运行在不同线程