集成学习
如果你向几千个人问一个复杂的问题,然后汇总他们的回答。一般情况下,汇总出来的回答比专家的回答要好。同样,如果你聚合一组预测器(比如分类器、回归器)的预测,的大的结果也比最好的单个预测器要好。这样的一组预测器称为集成,对于这种技术被称为集成学习,一个集成学习的算法被称为集成方法。
常见的集成方法有如下集中,bagging,boosting,stacking。
投票分类器
假设你已经训练好一些分类器,比如一个罗辑回归,一个svm,一个随机森林,一个k近邻。为了得到更好的结果,最简单的方法就是整合每个分类器的预测,然后将投票结果最多的作为预测类别,这种大多数投票分类器称作为硬投票。这样得到的结果普遍好于单个的分类器,从而实现将多个弱学习器变成一个强学习器。同时,要保证预测器尽可能的相互独立,这样会得到更优的效果。这样能保证他们犯不同类型的错误,从而提升准确率。
from sklearn.model_selection import train_test_split
from sklearn.datasets import make_moons
X, y = make_moons(n_samples=500, noise=0.30, random_state=42)
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42)
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import VotingClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
log_clf=LogisticRegression()
svc_clf=SVC()
rnd_clf=RandomForestClassifier()
voting_clf=VotingClassifier(estimators=[('lr', log_clf), ('rf', rnd_clf), ('svc', svc_clf)], voting='hard')
voting_clf.fit(X_train, y_train)
from sklearn.metrics import accuracy_score
for clf in (log_clf, rnd_clf, svc_clf, voting_clf):
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
print(clf.__class__.__name__, accuracy_score(y_test, y_pred))LogisticRegression 0.864 RandomForestClassifier 0.88 SVC 0.888 VotingClassifier 0.88
如果想让所有分类器估算出来概率,将概率在多个分类器上平均,依靠概率最高的进行分类并作出预测,这样的方法称为软投票法。通常来说,他的表现更加优秀于硬投票法,因为他对于那些更自信的投票器赋予更高的权重。在SVC中,往往不表现出概率,所以要将其超参数
SVC(probability=True)LogisticRegression 0.864 RandomForestClassifier 0.872 SVC 0.888 VotingClassifier 0.912
结果表现明显优于硬投票。
bagging,pasting
获取不同种类分类器的方法之一是使用不同的训练算法。除此之外,还有一种方法就是每个预测器采用的算法相同,但是在不同的训练集随机子集上进行训练。采样如果将结果放回,则被称为bagging方法(自举汇聚法)。如果不放回,则称为pasting方法。
bagging和pasting都允许训练实例多个预测器中被多次采样,但是只有bagging允许实例被同一个预测器多次采样。
sklearn中的bagging和pasting
from sklearn.ensemble import BaggingClassifier
from sklearn.tree import DecisionTreeClassifier
bag_clf=BaggingClassifier(DecisionTreeClassifier(), n_estimators=500, max_samples=100, bootstrap=True, n_jobs=-1)
bag_clf.fit(X_train, y_train)
y_pred=bag_clf.predict(X_test)
accuracy_score(y_test, y_pred)如果要使用pasting方法,将bootstrap=Flase即可。
此时的准确率为0.92,改为pasting方法看结果为0.912相差的并不多。再看一下再决策树下的表现
tree_clf = DecisionTreeClassifier(random_state=42)
tree_clf.fit(X_train, y_train)
y_pred_tree = tree_clf.predict(X_test)
print(accuracy_score(y_test, y_pred_tree))结果为0.856,由此可以体现出集成学习的优势,1vs500决策树的差距。
包外评估
对于bagging方法来说,有些实例可能被采样多次,那些未被采样的例子称为包外实列(OOB)。
BaggingClassifier(oob_score=True)这样设定就可以在结束后,自动进行包外评估。
bag_clf=BaggingClassifier(DecisionTreeClassifier(), n_estimators=500, bootstrap=True, n_jobs=-1, oob_score=True)
bag_clf.fit(X_train, y_train)
bag_clf.oob_score_结果为:0.9013333333333333
测试集的结果显示如下
from sklearn.metrics import accuracy_score
y_pred=bag_clf.predict(X_test)
accuracy_score(y_test, y_pred)结果为0.904,与包外评估差距不大。
随机森林
理解了bagging算法,随机森林(Random Forest,以下简称RF)就好理解了。它是Bagging算法的进化版,也就是说,它的思想仍然是bagging,但是进行了独有的改进。我们现在就来看看RF算法改进了什么。
首先,RF使用了CART决策树作为弱学习器,这让我们想到了梯度提示树GBDT。第二,在使用决策树的基础上,RF对决策树的建立做了改进,对于普通的决策树,我们会在节点上所有的n个样本特征中选择一个最优的特征来做决策树的左右子树划分,但是RF通过随机选择节点上的一部分样本特征,这个数字小于n,假设为nsubnsub,然后在这些随机选择的nsubnsub个样本特征中,选择一个最优的特征来做决策树的左右子树划分。这样进一步增强了模型的泛化能力。
如果nsub=nnsub=n,则此时RF的CART决策树和普通的CART决策树没有区别。nsubnsub越小,则模型约健壮,当然此时对于训练集的拟合程度会变差。也就是说nsubnsub越小,模型的方差会减小,但是偏倚会增大。在实际案例中,一般会通过交叉验证调参获取一个合适的nsubnsub的值。
除了上面两点,RF和普通的bagging算法没有什么不同, 下面简单总结下RF的算法。
输入为样本集D={(x,y1),(x2,y2),...(xm,ym)}D={(x,y1),(x2,y2),...(xm,ym)},弱分类器迭代次数T。
输出为最终的强分类器f(x)f(x)
1)对于t=1,2...,T:
a)对训练集进行第t次随机采样,共采集m次,得到包含m个样本的采样集DtDt
b)用采样集DtDt训练第t个决策树模型Gt(x)Gt(x),在训练决策树模型的节点的时候, 在节点上所有的样本特征中选择一部分样本特征, 在这些随机选择的部分样本特征中选择一个最优的特征来做决策树的左右子树划分
2) 如果是分类算法预测,则T个弱学习器投出最多票数的类别或者类别之一为最终类别。如果是回归算法,T个弱学习器得到的回归结果进行算术平均得到的值为最终的模型输出。
极端随机森林
extra trees是RF的一个变种, 原理几乎和RF一模一样,仅有区别有:
1) 对于每个决策树的训练集,RF采用的是随机采样bootstrap来选择采样集作为每个决策树的训练集,而extra trees一般不采用随机采样,即每个决策树采用原始训练集。
2) 在选定了划分特征后,RF的决策树会基于基尼系数,均方差之类的原则,选择一个最优的特征值划分点,这和传统的决策树相同。但是extra trees比较的激进,他会随机的选择一个特征值来划分决策树。
从第二点可以看出,由于随机选择了特征值的划分点位,而不是最优点位,这样会导致生成的决策树的规模一般会大于RF所生成的决策树。也就是说,模型的方差相对于RF进一步减少,但是偏倚相对于RF进一步增大。在某些时候,extra trees的泛化能力比RF更好。
特征重要性
一般来说,更加重要的特征越接近于根结点附近。sklearn中,可以通过feature_importances_来查看每个特征的重要性。随机森林有利于快速提取特征的重要性。
from sklearn.datasets import load_iris
iris=load_iris()
from sklearn.ensemble import RandomForestClassifier
rnd_clf=RandomForestClassifier(n_estimators=500, n_jobs=-1)
rnd_clf.fit(iris["data"], iris["target"])
for name, score in zip(iris["feature_names"], rnd_clf.feature_importances_):
print(name, score)sepal length (cm) 0.10346956848238457 sepal width (cm) 0.025617561677439962 petal length (cm) 0.43341727470590563 petal width (cm) 0.43749559513426994
提升法
boosting是指将多个弱学习器结合称为一个强学习器的任意集成方法,大多数提升法的思路是循环训练预测器,每一次对其先序进行一些改正。主要分为AdaBoost和梯度提升两个方法。
AdaBoost
新预测器对其先序进行纠正的方法之一,就是关注前序拟合不足的实例。这就是AdaBoost方法。
要构建一个AdaBoost分类器,首先要训练一个基础分类器,用其他训练集进行预测。然后对错误的分类是实例增加其相对权重,接着,对第二个分类器进行预测,继续更新权重。
同样,这也暴漏了一个巨大的缺点。相对bagging和pasting来说,AdaBoost无法并行,每一个预测器只有当前一个预测器完成并评估后才开始训练。因此在拓展方面,相对其他两个差距较大。
from sklearn.ensemble import AdaBoostClassifier
ada_clf = AdaBoostClassifier(
DecisionTreeClassifier(max_depth=1), n_estimators=200,
algorithm="SAMME.R", learning_rate=0.5, random_state=42)
ada_clf.fit(X_train, y_train)

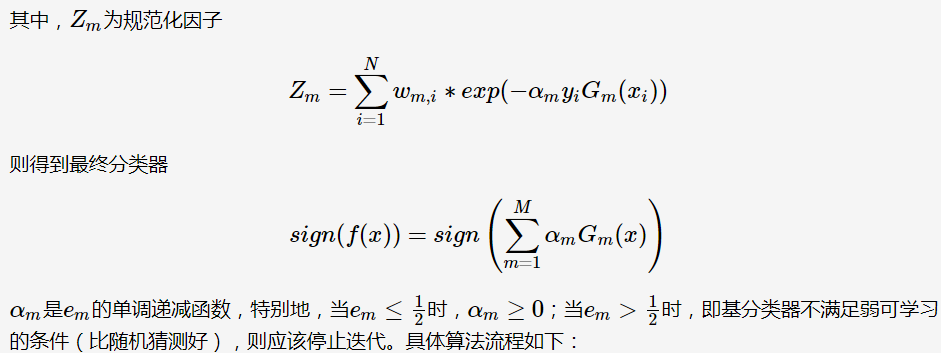
梯度提升
不同与AdaBoost那样在每个迭代中调整实例权重,而是让新的预测器对前一个预测器的残差进行拟合。
np.random.seed(42)
X = np.random.rand(100, 1) - 0.5
y = 3*X[:, 0]**2 + 0.05 * np.random.randn(100)首先,拟合出一个决策回归树
from sklearn.tree import DecisionTreeRegressor
tree_reg1=DecisionTreeRegressor(max_depth=2)
tree_reg1.fit(X, y)针对第一棵树的残差,训练第二棵树
y2=y-tree_reg1.predict(X)
tree_reg2=DecisionTreeRegressor(max_depth=2)
tree_reg2.fit(X, y2)针对第二棵树的残差,训练第三棵树
y3=tree_reg2.predict(X)
tree_reg3=DecisionTreeRegressor(max_depth=2)
tree_reg3.fit(X,y3)将所有树的预测相加,从而对新实例进行预测
y_pred = sum(tree.predict(X_new) for tree in (tree_reg1, tree_reg2, tree_reg3))
当然,我们也可以采用简单的方法。直接调用GBRT集成即可
from sklearn.ensemble import GradientBoostingRegressor
grbt=GradientBoostingRegressor(max_depth=2, n_estimators=3, learning_rate=1.0)
grbt.fit(X, y)其中,学习率过低以及预测器太少都容易导致拟合不足的问题,学习率过高或者预测器太多则会导致过拟合的问题。
堆叠法
不同于其他方法,它基于一个很简单的想法:与其使用一些简单的函数来聚合集成中所有预测器的预测,为什么不训练一个模型来执行这个聚合呢?比如是那个预测器分别预测了不同的值(3.1,2.7,2.9),然后最终的预测器将这些预测作为输入,进行最终的预测。
流程如下:
首先将训练集分成两个子集,第一个子集用来训练第一层的预测器。
然后用第一层的预测器在第二个子集上进行预测。因为预测器从未见过这些实例,所以可以确保预测是“干净的”。将这些预测值作为输入特征,创建一个新的训练集。在这个新的训练集上训练混合器,让它根据第一层的预测来预测目标值。通过这种方法可以训练多种不同的混合器。