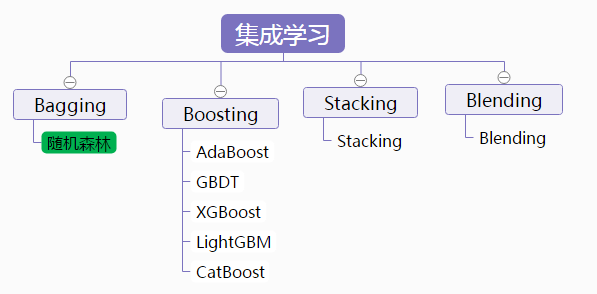
随机森林步骤:
-
构建多个数据集
在包括N个样本的数据集中,采用有放回的抽样方式选择N个样本,构成中间数据集,然后在这个中间数据集的所有特征中随机选择几个特征,作为最终的数据集。以上述方式构建多个数据集;一般回归问题选用全部特征,分类问题选择全部特征个数的平方根个特征
-
为每个数据集建立完全分裂的决策树
利用CART为每个数据集建立一个完全分裂、没有经过剪枝的决策树,最终得到多棵CART决策树;
-
预测新数据
根据得到的每一个决策树的结果来计算新数据的预测值。回归问题:采用多棵树的平均值。分类问题:采用投票计数的方法,票数大的获胜,相同的随机选择。可以把树的棵树设置为奇数避免这一问题。
随机森林方法图示:
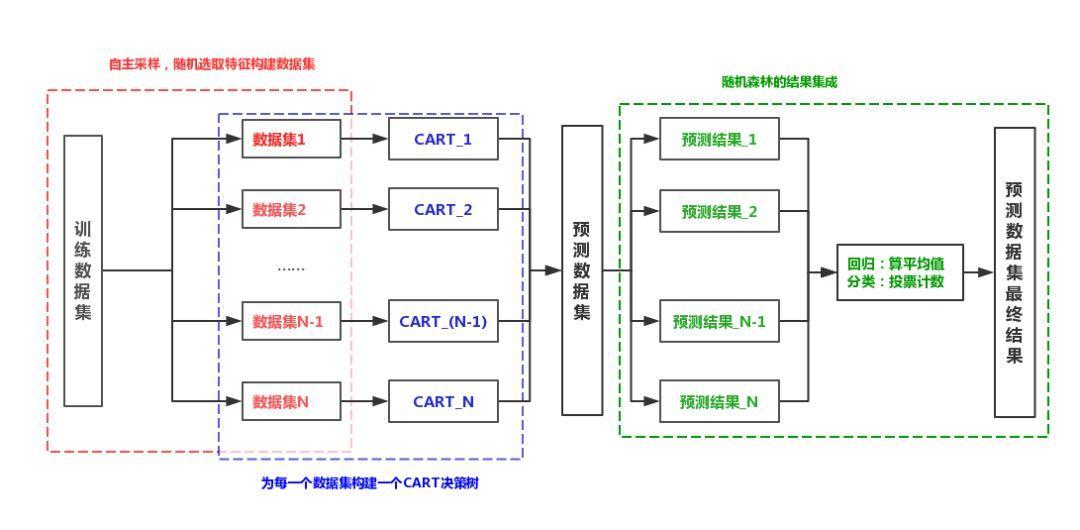

方法实现:
- 回归问题
利用sklearn.ensemble包中的RandomForestRegressor,此函数的重要参数说明:
n_estimators:建立树的个数,也就是上图中的N;
criterion:计算分割点的方法,默认为基尼系数,默认即可;
**max_features:**随机选择特征的个数,默认为"auto",回归问题默认即可;
**max_depth:**树的最大深度,默认即可;
**min_samples_split:**节点数据集中的样本个数等于次数则不再分裂,默认即可;
- 分类问题
利用sklearn.ensemble包中的RandomForestClassifie,此函数的重要参数说明**:**
n_estimators:建立树的个数,也就是上图中的N;
criterion:计算分割点的方法,默认为基尼系数,默认即可;
**max_features:**随机选择特征的个数,默认为"auto",设为“sqrt”;
**max_depth:**树的最大深度,默认即可;
**min_samples_split:**节点数据集中的样本个数等于次数则不再分裂,默认即可;
一般,参数的组合选择,可选用交叉验证法获得比较好的参数组合。

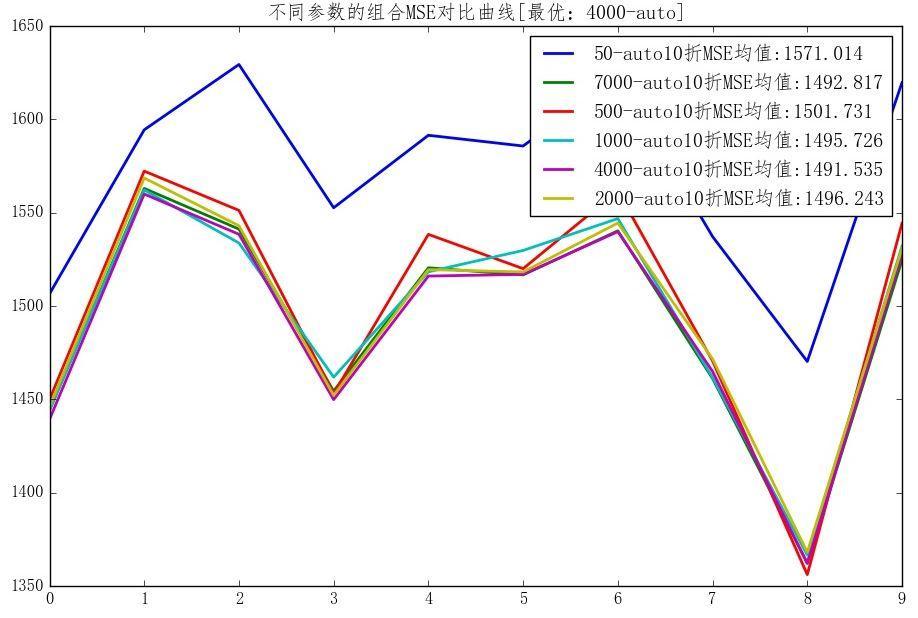
回归实例:北京Pm2.5预测
- 随机森林不同参数设置MSE对比
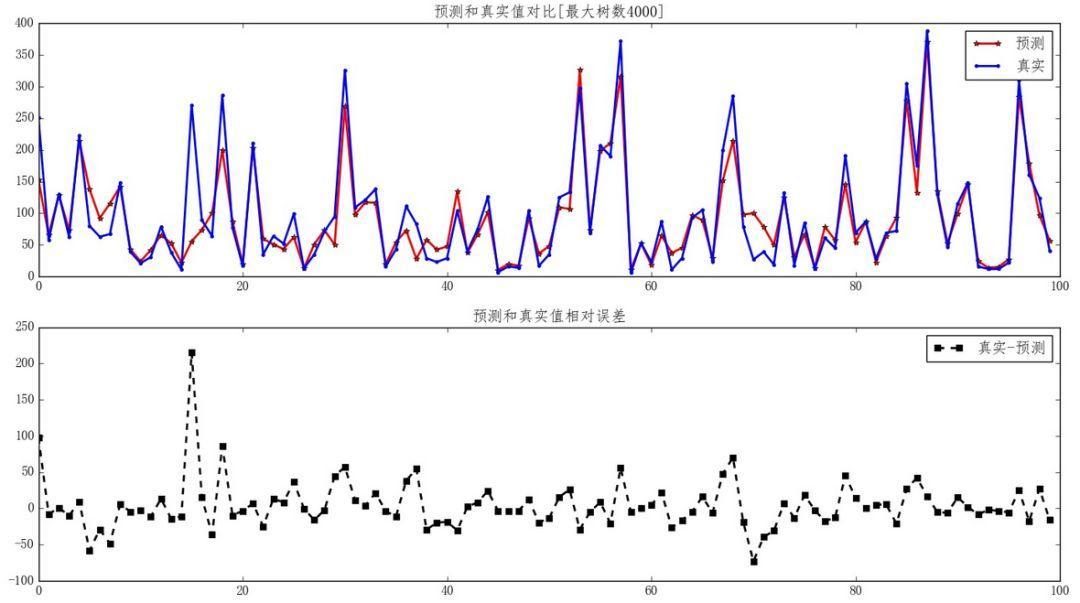
- 预测数据集真实值和预测值对比
分类实例:成年人收入
- 随机森林不同参数设置F1度量对比
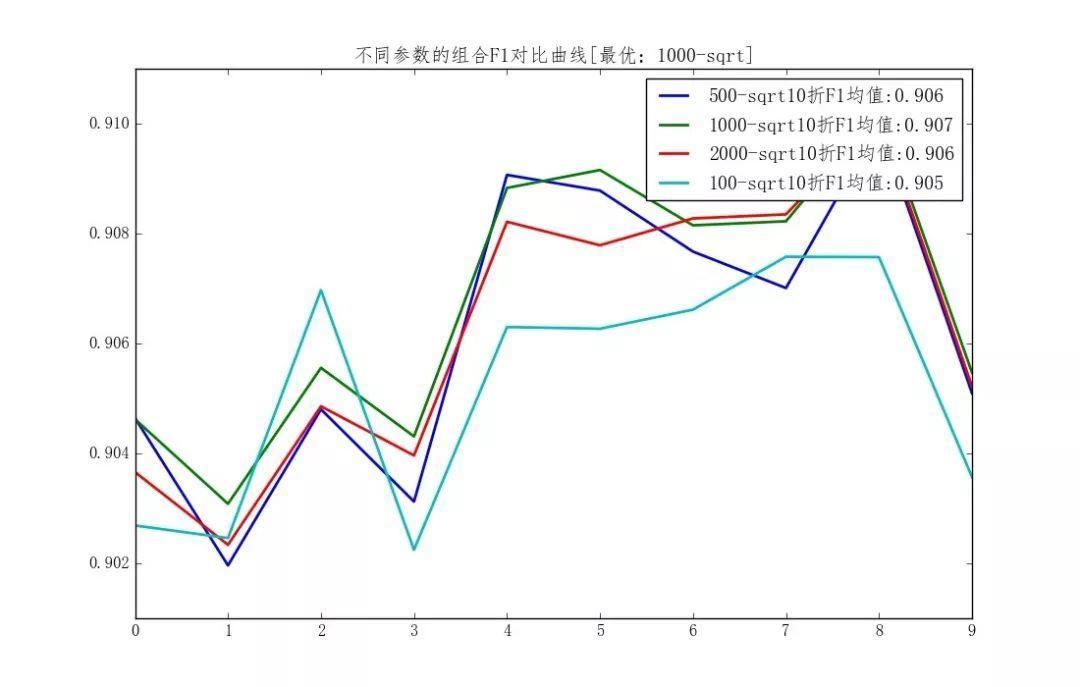
- 预测数据集混淆矩阵、F1度量,精确率以及召回率
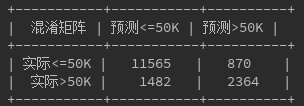
**F1度量:**0.8118182938497857
**精确率:**0.85553712916897
**召回率:**0.7723503873809958
实例代码:随机森林,扫描下方二维码或者微信公众号直接搜索”Python范儿“,关注微信公众号pythonfan, 获取更多实例和代码。
